
VRAG-RL:阿里开源多模态RAG推理框架,视觉信息理解与生成的“新引擎”!
阿里巴巴通义大模型团队推出VRAG-RL多模态RAG推理框架,通过视觉感知驱动和强化学习优化提升VLMs处理视觉丰富信息的能力。支持多轮交互、动态调整策略等,应用场景包括智能文档问答、视觉信息检索、多模态内容生成等。
阿里巴巴通义大模型团队推出VRAG-RL多模态RAG推理框架,通过视觉感知驱动和强化学习优化提升VLMs处理视觉丰富信息的能力。支持多轮交互、动态调整策略等,应用场景包括智能文档问答、视觉信息检索、多模态内容生成等。

VRAG-RL 是一种基于强化学习的视觉检索增强生成方法,通过引入多模态智能体训练,实现了视觉语言模型在检索、推理和理解复杂视觉信息方面的显著提升。
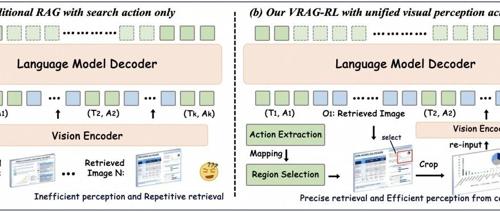
最新研究成果VRAG-RL通过引入强化学习和多模态智能体训练,解决视觉丰富信息检索增强生成任务中的挑战,显著提升了视觉语言模型在检索、推理和理解视觉信息方面的能力。