开源世界的“深度思考者”:Qwen3-235B全面解析,实力对标Gemini 2.5 Pro?

Qwen3-Thinking-2507是阿里巴巴发布的开源大语言模型,采用高效混合专家架构,在复杂推理基准上达到SOTA水平,支持超长上下文和强大的Agent工具调用能力,并通过‘思考’模式实现透明的推理过程。
Qwen3-Thinking-2507是阿里巴巴发布的开源大语言模型,采用高效混合专家架构,在复杂推理基准上达到SOTA水平,支持超长上下文和强大的Agent工具调用能力,并通过‘思考’模式实现透明的推理过程。

阿里开源Qwen3-Coder模型,支持智能体编程和本地部署。它能自主规划完成任务,并拥有480亿参数。Qwen3-Coder通过双重强化学习提升复杂任务处理能力。

美的AI研究院和华东师范大学联合提出ChatVLA-2模型,具备开放世界具身推理能力。通过动态混合专家架构和双阶段训练策略,模型在数学匹配游戏和玩具摆放任务中展示出色表现,成功率达82%。
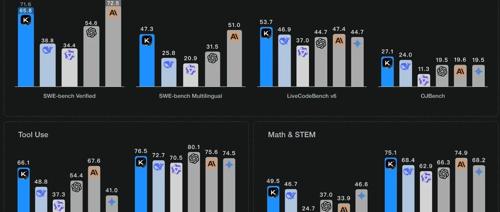
杨植麟提出开源路线,Moonshot AI发布Kimi K2大语言模型,采用混合专家架构,参数量达1万亿,表现出色并在多个基准测试中创造新SOTA记录。核心技术包括MuonClip优化器、大规模Agent数据合成和通用强化学习框架。模型提供两种版本,并通过修改版MIT协议开源。

五一前夕,阿里通义千问发布的Qwen3系列模型在开源领域再次取得突破,支持多种语言、高性能计算和混合专家架构。该模型包括Qwen3-235B-A22B和Qwen3-30B-A3B两个核心模型,覆盖119种语言,并提供丰富的训练数据以降低部署成本。

Meta 最新开源模型 Llama 4 Scout 达到千万级上下文,拥有 1090 亿参数。其使用 NoPE 架构解决长度泛化问题,并通过优化训练流程和强化学习框架提升性能。

Llama 4家族成员发布,Llama 4 Maverick直接登上lmarena.ai评测Top2;Llama 4 Behemoth拥有288B活跃参数量;Llama 4 Maverick和Llama 4 Scout分别拥有17B和7B活跃参数量。这些模型支持多模态智能,并采用了最新的技术如MetaP、后训练策略和MoE架构。

Meta发布了Llama 4系列首批模型,采用混合专家架构并支持多模态训练。推出了性能最强的小尺寸模型Scout、同级别最佳的Maverick以及正在开发中的Behemoth预览版。Llama 4 Scout和Maverick均支持高性能低成本比,实现了业界领先的1000万+ Token 多模态上下文窗口,并提供了智能调参技术和后训练策略优化。