

Llama 4可以不追,但Qwen3你必须知道。
五一前夕,来自阿里通义千问的 Qwen 系列模型迎来重磅升级,能打、能省、能思考,有点东西。

1. Qwen3,新晋开源之王
在开源模型领域,Qwen 系列一直是第一梯队的存在。
这一次的 Qwen3,也不例外。
作为阿里通义推出的新一代大模型,Qwen3 身上的标签多且全面:混合专家(MoE)架构、高性能、低成本、支持“思考模式”和“非思考模式”自由切换、覆盖 119 种语言、36 万亿 tokens 的训练数据、2350 亿总参数 + 220 亿激活参数(Qwen3-235B-A22B)、以 Apache 2.0 许可证全面开源 —— 可部署、可调用、可商用。
这样的模型,这样的通义千问,尊称一句 “国产之光” 不过分吧。
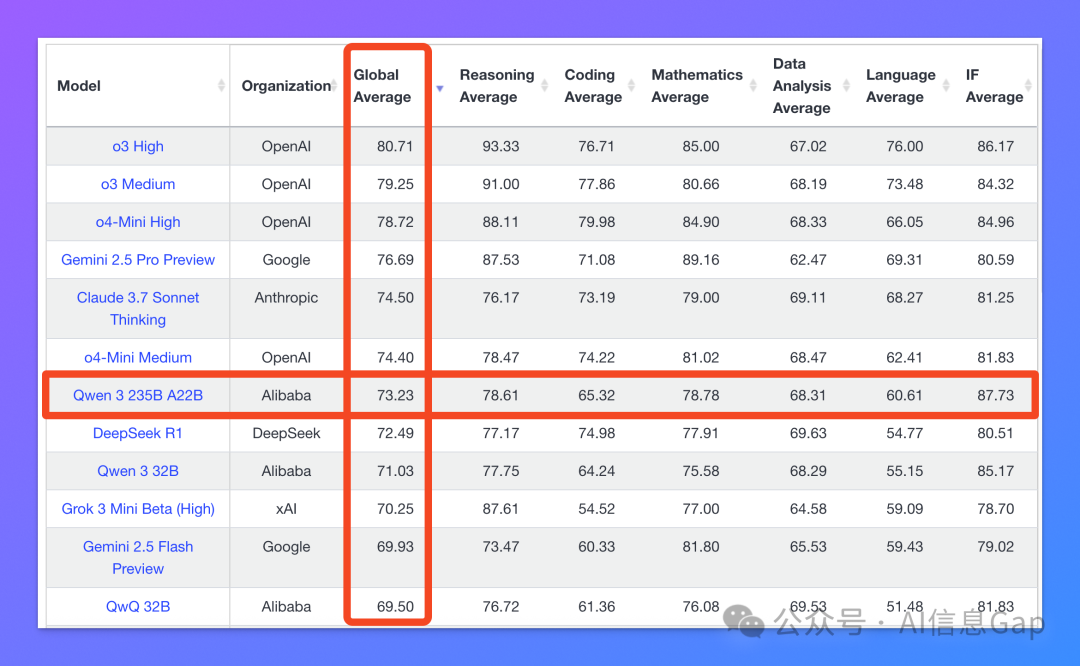
在最新的 LiveBench 大模型排行榜上,Qwen3 已经以 73.23 的综合评分超越 DeepSeek-R1 坐上了开源模型的头把交椅。
2. 核心模型:“巨无霸” + “小怪兽”
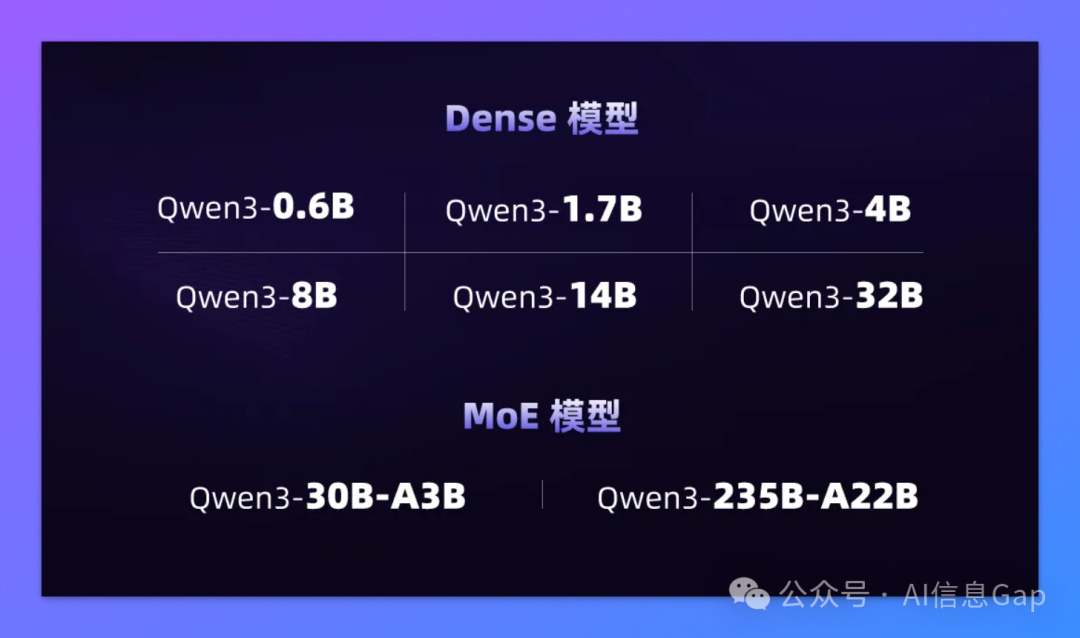
目前 Qwen 官方开源了两款 Qwen3 系列中的混合专家(MoE)核心模型:
-
Qwen3-235B-A22B:总参数 2350 亿,激活参数仅 220 亿,典型的“体型巨、能耗低”; -
Qwen3-30B-A3B:总参数 300 亿,激活参数仅 3 亿,主打一个“小块头有大智慧”。
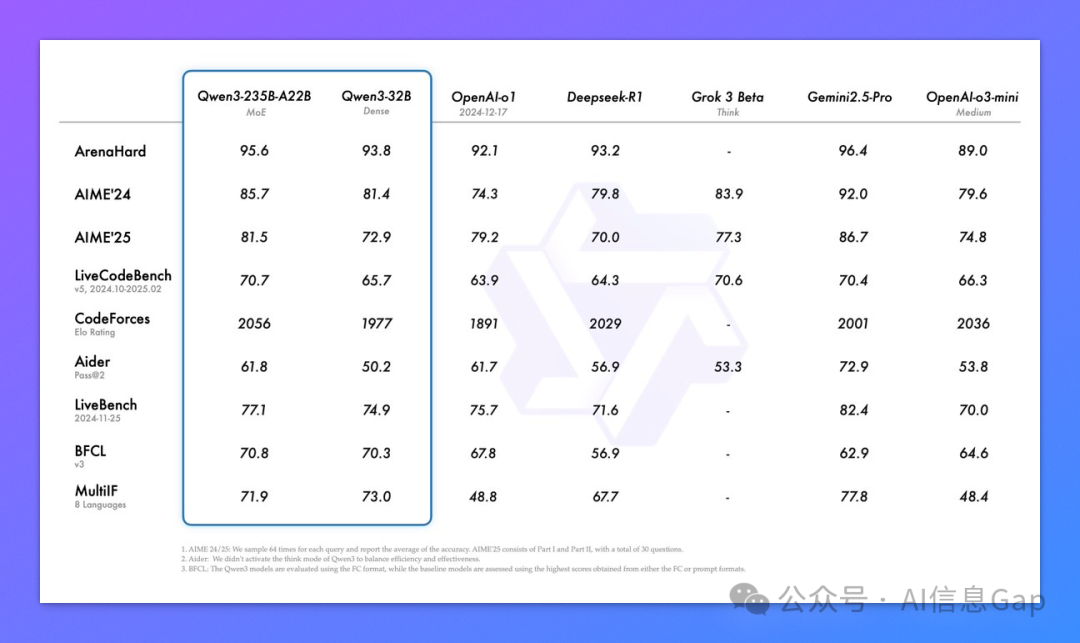
这两个 MOE 模型在 GPQA、AIME24、LiveCodeBench 等基准评测里表现也都非常硬核,综合实力超过了 o1 和 DeepSeek-R1;但和最顶级的满血版 o3、Gemini 2.5 Pro 相比,还是有一定差距的。
3. “思考模式” + “非思考模式”
Qwen3 最大的设计亮点之一,是引入了两种思维模式:
-
思考模式(enable_thinking=True):会自动调用内部思维链(Chain of Thought,CoT)进行多步推理、结构化思考,适合解数学难题、写复杂代码; -
非思考模式(enable_thinking=False):主打一个秒回,适合问“帮我总结这段话”这类简单问题。

Qwen3 并不是第一个支持这样切换思维模式的模型,在它之前,Anthropic 的 Claude 3.7 Sonnet 和谷歌的 Gemini 2.5 Flash 就已经支持了这样的开关。
这其实是一个趋势,Qwen3 也不会是最后一个。
4. 训练数据量翻倍,基础更扎实
相较于前代模型 Qwen2.5,Qwen3 的训练数据量直接翻倍,从 18 万亿提升到了36 万亿 tokens。
不仅数量多,质量也有优化:
-
数学、代码数据用专家模型合成; -
大量语料来自高质量 PDF 文档、网页、结构化问答。
这一代的 Qwen3 应该是通义训练成本最高的一版模型了吧。

5. Dense + MoE 双线开源
除了上面两个 MoE 模型,阿里这次还一口气开源了其他 6 个 Dense 模型:
-
按照参数量从小到大分别是 Qwen3-0.6B、1.7B、4B、8B、14B、32B; -
支持最长 128K 上下文; -
Apache 2.0 许可证,无需申请,可直接商用。
多说一嘴。
Dense(稠密)模型结构简单,所有参数在每次推理中都会参与计算,因而表现稳定,但计算成本高、部署资源消耗大;
MoE(混合专家)模型则通过只激活部分专家网络,在保持性能的前提下显著降低推理成本,更适合在算力有限或对响应速度有要求的场景中使用。两者的本质区别在于参数是否“全员出动”,取舍点则在效率与一致性之间。
6. 多语言:支持 119 种语言
Qwen3 模型的多语言覆盖堪称恐怖,官方公布的数据是:119 种语言与方言。
支持的语言包括但不限于:
-
中文(简体、繁体、粤语)、英文、法语、德语、西班牙语; -
阿拉伯语、希伯来语、爪哇语、意第绪语、斯瓦西里语、冰岛语等等。

7. 部署成本更低:H20 GPU 也能跑 235B 模型
和 6710 亿参数(671B)的老对手 DeepSeek-R1 相比,235B 的 Qwen3-235B-A22B 在本地部署方面的身形更加“苗条”,经济适用。
得益于 MoE 架构的优化,你现在只需要 4张 H20 GPU 就能在本地跑起来 Qwen3-235B-A22B。
这在 2024 年还难以想象,在今天,意味着:
-
显存占用约为同类模型的三分之一; -
推理成本下降 65%-75%。
部署门槛的降低,也让 Qwen 的开源朋友圈正在一点点变大,越来越热闹。

8. 即拿即用的 Qwen3
你能在哪些地方用上 Qwen3?
作为一款开源模型,本地部署是必须支持的。受限于硬件的限制,你可以自行选择部署 MOE 还是 Dense 模型。
-
Hugging Face:https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f -
ModelScope:https://modelscope.cn/collections/Qwen3-9743180bdc6b48 -
本地部署工具:支持 Ollama、LMStudio、llama.cpp、ktransformers 等
当然,对于不喜欢折腾的小可爱,千问团队也已在 Qwen Chat(海外版)以及 通义千问(国内版)同步上线了 Qwen3 模型。
-
Qwen Chat:https://chat.qwen.ai -
通义千问:https://www.tongyi.com/qianwen/

结语
混合专家、高效推理、思维模式切换、百语种覆盖,Qwen3 的目标大概率已经不再是追赶,而是引领。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)