
受到deepseek的刺激和启发,杨植麟想通了,走上了开源的路线。
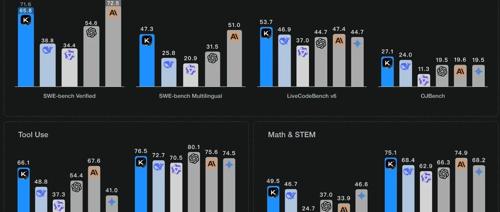
Moonshot AI昨日正式发布Kimi K2大语言模型,采用混合专家(MoE)架构,总参数量达1万亿,激活参数32B,支持128K上下文长度。该模型在代码生成、Agent任务和数学推理等专业领域展现出领先性能,并在多个基准测试中创造了开源模型的新SOTA记录。
核心技术创新
-
MuonClip优化器
采用创新的MuonClip技术替代传统Adam优化器,通过qk-clip机制控制注意力logits规模,在15.5T token训练过程中保持零损失峰值,解决了大规模模型训练稳定性问题。
-
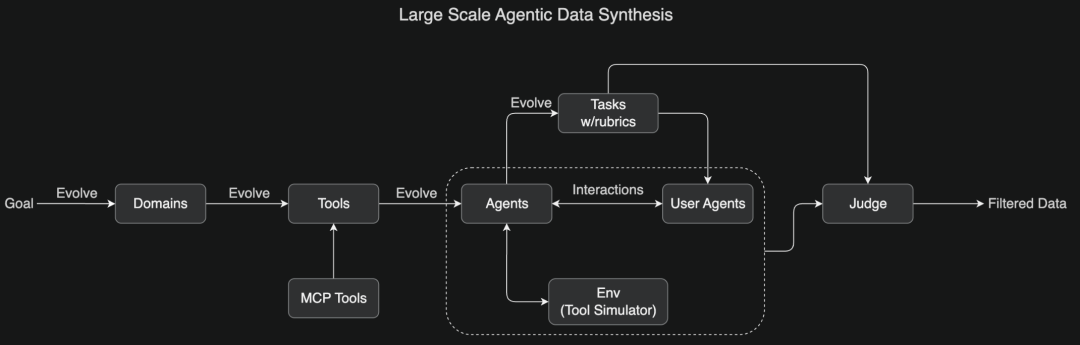
大规模Agent数据合成
构建覆盖数百领域、数千工具的合成pipeline,通过LLM评估筛选高质量样本,显著提升了模型的工具调用能力。
-
通用强化学习框架
引入自我评价机制(self-judging),在可验证任务(代码/数学)和不可验证任务间建立奖励关联,增强模型泛化能力。
性能表现
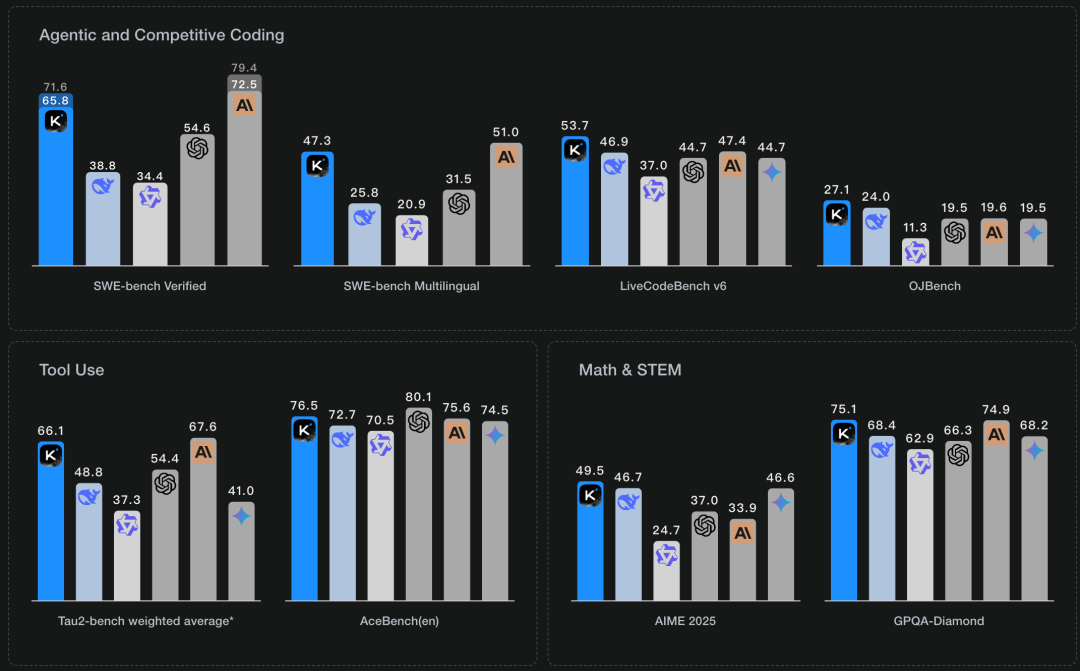
在SWE Bench Verified、Tau2、AceBench等基准测试中,Kimi K2表现突出:
-
SWE Bench Verified单次尝试准确率65.8% -
Tau2零售场景平均得分70.6 -
LiveCodeBench v6 Pass@1达53.7%
开源与部署
本次发布包含两个版本:
-
Kimi-K2-Base:基础预训练模型,适合科研与定制场景 -
Kimi-K2-Instruct:通用指令微调版本,优化问答与Agent任务
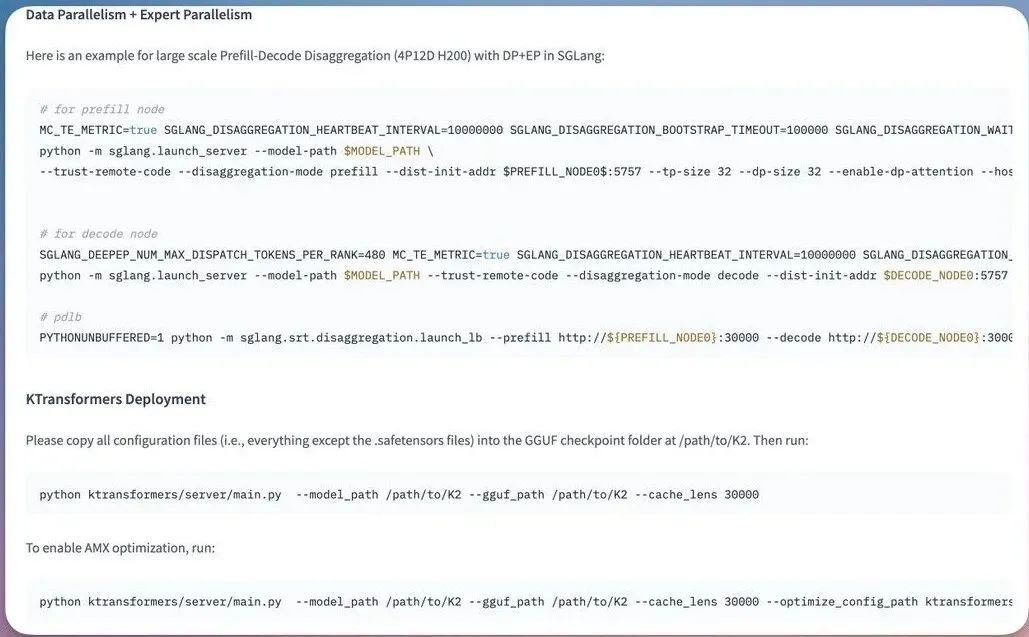
模型采用修改版MIT协议开源,vLLM、SGlang等推理引擎首发支持部署。目前已同步上线Web端、App和API服务。

公众号回复“进群”入群讨论。
(文:AI工程化)