
MI300X

AMD跑DeepSeek性能超H200!128并发Token间延迟不超50ms,吞吐量达H200五倍

AMD MI300X在FP8下全面超越英伟达H200,吞吐量最高可达H200的5倍。得益于SGLang框架和优化的AI内核库AITER,MI300X在延迟相似的情况下实现了更高的吞吐量,并且在固定并发情况下性能提升75%。
AMD开源30亿小参数模型,媲美Qwen-2.5
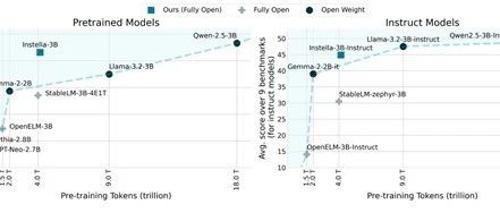
AMD开源了最新小参数模型Instella-3B及其微调版本。该模型性能超越Llama-3.2-3B和Gemma-2-2B,并在多个基准测试中表现优异。