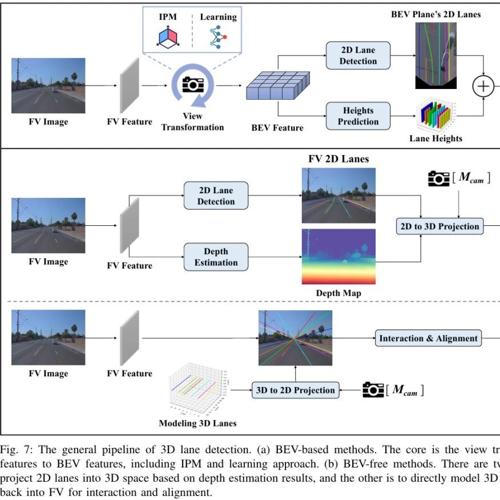
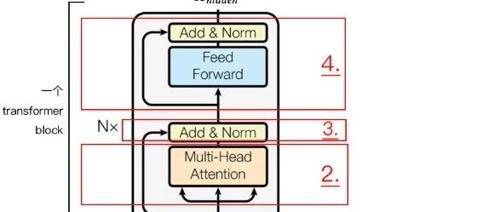
注意力机制






Ilya Sutskever连续三年获NeurIPS 终身成就奖

AI界传奇人物Ilya Sutskever因发表的论文’Sequence to Sequence Learning with Neural Networks’获得NeurIPS最高荣誉。该论文展示了序列学习的革命性方法,并在自然语言处理领域影响深远。
LSTM之父:我也是注意力之父!1991年就发表线性复杂度,遥遥领先Transformer 26年

新智元报道
编辑:LRS
【新智元导读】
Transformer模型自2017年问世以来,已成为AI