
强化学习



揭秘:OpenAI是如何发展出推理模型的?

OpenAI通过内部代号为’Strawberry’的计划,实现了推理能力的飞跃。该计划结合了大语言模型、强化学习和测试时计算技术,催生了名为’o1’的新模型,并在国际数学奥林匹克竞赛中取得佳绩。
LLM抢人血案:强化学习天才被挖空,一朝沦为「无人区」!

Joseph Suarez 通过对强化学习历史的回顾指出,尽管近年来强化学习相关论文数量增加,但领域并未取得持续性的突破。主要原因是学术界的短视行为和过度优化评价体系导致研究进展缓慢。他提倡从头开始构建新的强化学习基础设施,并强调性能工程的重要性。


Anthropic 反杀 OpenAI,LLM 企业市场新格局
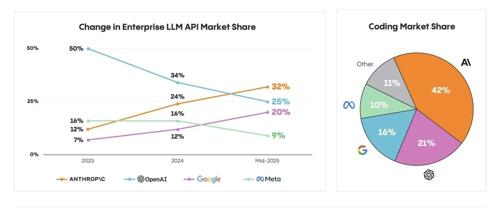
Anthropic 在企业级语言模型市场超越 OpenAI,市场份额达到32%。关键趋势包括代码生成和强化学习的应用、Agent时代的到来以及企业在选择模型时更看重性能而非开源。
告别复杂提示词!蚂蚁新方式让AI自动理解你的个性化需求
蚂蚁通用人工智能研究中心提出AlignXplore方法,通过强化学习和深度思考从用户行为中归纳偏好,并且这种对人类偏好的洞察可以动态更新。AlignXplore让AI更好地理解并回应用户的个性化需求。
