
AntResearchNLP团队 投稿
量子位 | 公众号 QbitAI
相信大家都有这样一个体验。
跟AI无论什么对话,感觉都是说空话套话。

有时候为了让AI懂自己,许多用户甚至不得不学习复杂的“提示词技巧”,手动编写长长的指令,像是在给AI做“岗前培训”。

那么如何实现高情商AI?蚂蚁通用人工智能研究中心自然语言处理实验室提出了一个叫AlignXplore的方法——
通过强化学习,AlignXplore能够通过深度思考从用户行为中归纳出他/她的偏好,并且这种对人类偏好的洞察可以随着用户行为的变化而动态更新。
更有趣的是,当把归纳好的偏好描述迁移到一个下游对齐模型时,能够让这个模型的个性化对齐能力得到显著提升。

如何让AI真正懂你?
如何让AI真正“懂”你?我们需要让AI从一个“规则执行者”进化成一个“模式发现者”。
这意味着,它要掌握一种被认为是人类智慧核心的能力——归纳推理(Inductive Reasoning)。

△“千人一面”的对齐方式无法满足用户多样的个性化需求,红字蓝字是对应用户的偏好描述
事实上,AI早已对演绎推理(Deductive Reasoning)驾轻就熟,具备令人惊叹的数学解题和代码编写能力。
你给它一个确定的前提(如“求解二次方程 ax²+bx+c=0”)和一套不变的规则(求根公式),它就能通过一步步严密的逻辑推演,给出一个唯一、可验证的正确答案。这是一个典型的“自上而下”(Top-Down)的过程:从普适的公理或规则出发,推导出一个具体的、必然的结论。 在这个世界里,没有模糊地带,只有对与错。
而归纳推理则完全相反,它是一个自下而上(Bottom-Up)的过程:它没有预设的“个人说明书”。它的“线索”就是你的每一个行为: 你追问了什么问题,说明你关心什么;你跳过了哪个回答,说明你不喜欢什么风格;你对哪个笑话点了赞,暴露了你的幽默感。它的“任务”就是从这些海量的、碎片化的行为数据中,提炼出专属于你的互动模式与偏好规律。通过归纳推理,AI有潜力成为你的“知心姐姐”,主动拼凑出一个完整的你。
举个例子,让我们来扮演一次AI知心姐姐,看看它是如何通过两次看似无关的对话,就精准捕捉到你的“潜台词”的:
-
第一次交互:你问“什么是人工智能?它在商业和生活中是怎么用的?”。AI会立刻开始在幕后推理你的偏好:“你可能对AI技术有特别的兴趣,但似乎更关心实际应用,也许是商业导向”。
-
第二次交互:你想学习冥想,在两个候选回答中,你选择了提供具体步骤的那个,而不是阐述冥想哲学的回答。AI会立刻更新它对你偏好的理解:“你的偏好是获取能解决眼前需求的、务实的指导,而不是理论探讨。”
这种渐进式的学习和优化,让AI的“记忆”不再短暂。随着一次次的交互,它会不断收集新的线索,验证并修正之前的假设,对你的“人物画像”进行一次又一次的精修。最终,它不再是被动回答问题的机器,而是在主动地、持续地学习和理解你是谁。
这,就是我们通向真正个性化AI的第一步。
AlignXplore
AlignXplore的训练包括两个阶段。
第一阶段:冷启动训练(Cold-start Training)——拜师学艺。
研究团队首先引入一个更强大的AI作为“导师模型”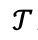 。这个导师会生成大量高质量的“教学案例”。对于每个用户的行为信号集合
。这个导师会生成大量高质量的“教学案例”。对于每个用户的行为信号集合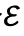 ,会生成多组候选的推理链r和相应的偏好描述d利用奖励函数R(r,d)进行筛选来获取高质量数据
,会生成多组候选的推理链r和相应的偏好描述d利用奖励函数R(r,d)进行筛选来获取高质量数据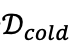 。通过在上进行SFT,实现偏好归纳模型的冷启动。
。通过在上进行SFT,实现偏好归纳模型的冷启动。
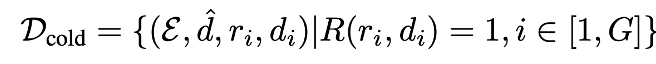
其中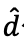 代表可能存在的历史偏好,而G是为每个实例生成的候选样本数量。这里奖励函数定义为:
代表可能存在的历史偏好,而G是为每个实例生成的候选样本数量。这里奖励函数定义为:
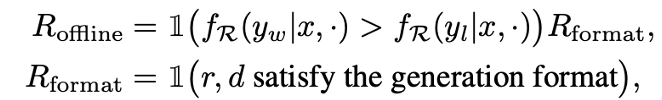
其中,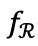 是下游大语言模型R对回复的偏好打分函数。这个通用的奖励框架可以被实例化为两种具体的奖励函数,用于模型的训练与评估:
是下游大语言模型R对回复的偏好打分函数。这个通用的奖励框架可以被实例化为两种具体的奖励函数,用于模型的训练与评估:
1、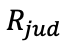 (基于偏好判断的奖励)
(基于偏好判断的奖励)
R作为一个偏好判断模型,直接评估在给定推断出的偏好d后
“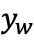 比
比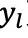 更好”的概率,最大化与用户真实偏好的一致性:
更好”的概率,最大化与用户真实偏好的一致性:
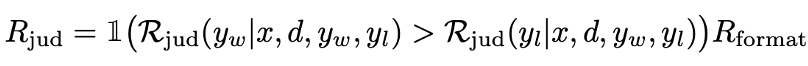
提供了更稳定和有效的训练信号,是AlignXplore在训练和评估中采用的核心奖励函数。
2、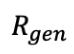 (基于生成概率的奖励)
(基于生成概率的奖励)
R作为一个回复生成模型,衡量在加入偏好描述d前后,模型生成较优回复与生成较差回复间的对数概率差值是否有提升:
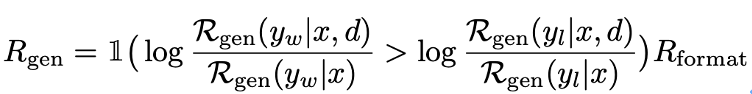
第二阶段:强化学习(Reinforcement Learning)——实战修行。
在这一阶段,采用GRPO算法训练,模型会针对用户的行为,尝试生成多种不同的推理路径和偏好结论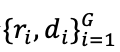 。随后,系统会根据这些结论的准确性给予“奖励”或“惩罚”。通过这种不断的试错和优化,模型学会了如何将初步的分析提炼成更精准、更具指导性的判断。
。随后,系统会根据这些结论的准确性给予“奖励”或“惩罚”。通过这种不断的试错和优化,模型学会了如何将初步的分析提炼成更精准、更具指导性的判断。
优化策略定义如下:
流式偏好推断机制
AlignXplore模型支持流式偏好推断机制,即不再需要反复回看用户冗长的历史记录,而是像处理一条源源不断的数据流一样,实时、增量地更新对用户的理解——就像它在之前的例子中发现用户“务实导向”的风格一样。
这种“流式”设计带来的好处是显而易见的:
首先,它大大提高了生成效率;
其次,它极为灵活,当用户从休闲模式切换到工作状态时,它能迅速迭代出一个新的“工作版”偏好,而不是固执地用旧眼光看用户。这才是真正能跟上用户节奏的动态进化系统。
实验结果
在域内测试集AlignX_test和域外测试集P-Soups上,AlignXplore模型在个性化对齐任务上取得了显著的成功,相较于基座模型DeepSeek-R1-Distill-Qwen-7B平均提升了15.49%。
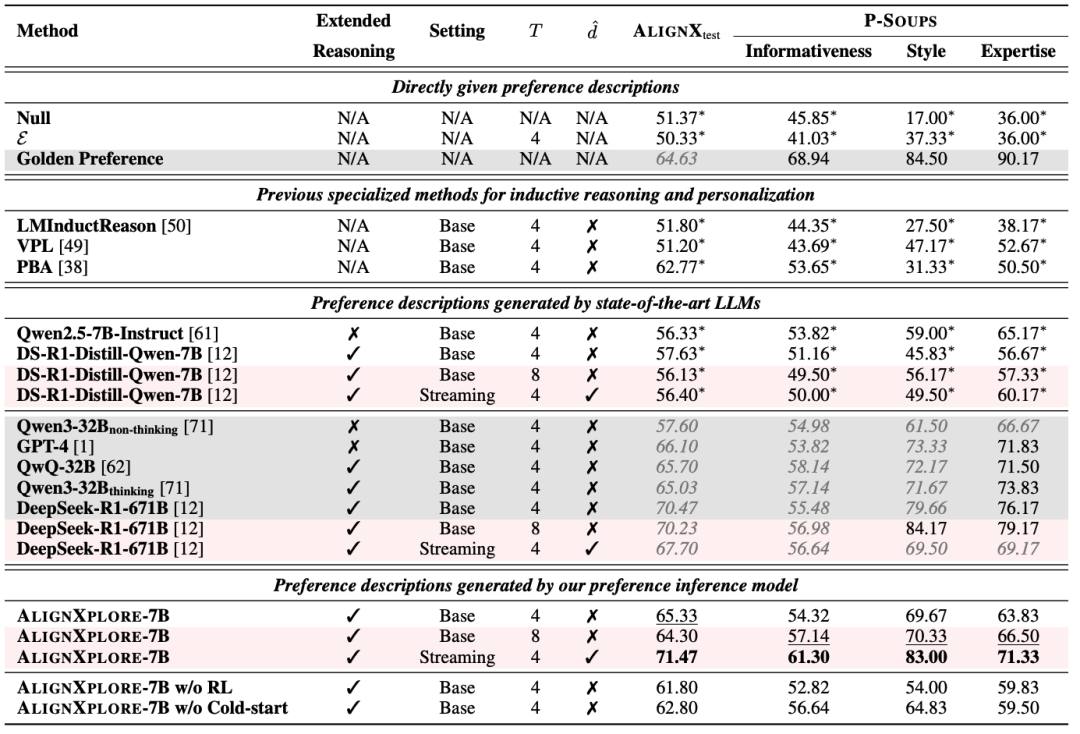
△AlignXplore与各种推理/非推理模型在域内外数据集上的表现
更重要的是,它展现了强大的综合能力:
高效性: 即使互动历史变得非常长,流式推理机制也能保持稳定的响应速度和准确率,不会像传统方法那样需要每次编码所有行为信号致使越来越慢。
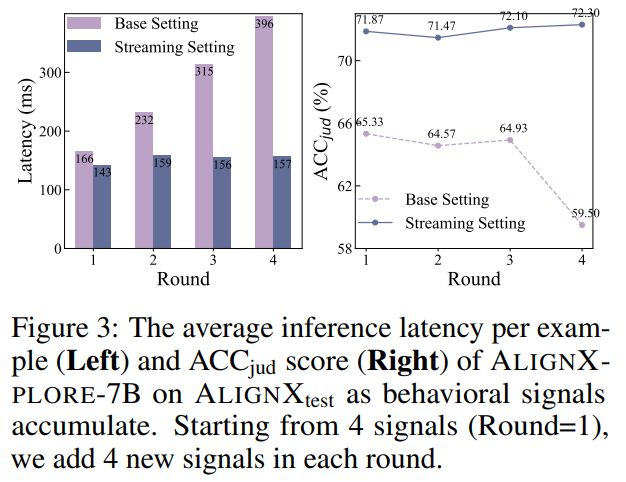
△随着互动的进行,流式推理机制下的响应速度和准确率都保持稳定
泛化能力:它不仅能处理特定的反馈数据,还能从用户发布的帖子user-generated content (UGC)等不同形式的内容中学习,并且其推断出的偏好也能成功地应用于与训练时不同的下游模型,包括QwQ-32B、DeepSeek-R1-671B等。
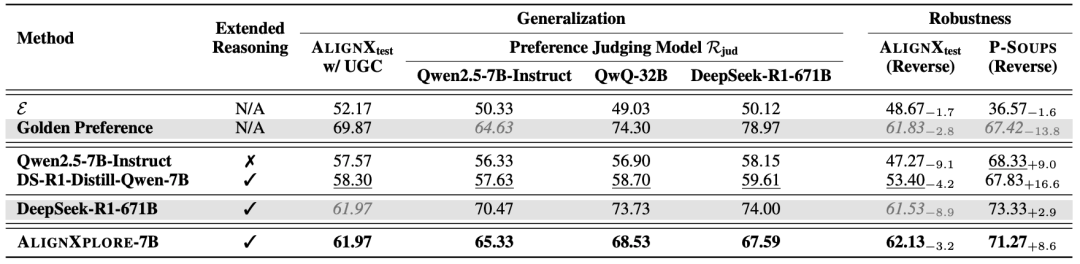
△泛化性实验
鲁棒性:即使用户的偏好发生改变甚至反转,AlignXplore也能灵活适应,不会产生剧烈的效果波动。
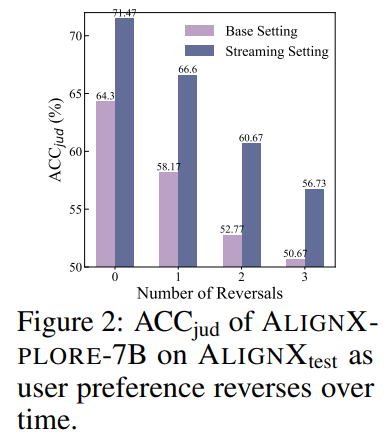
△即便反转初始行为信号的偏好,流式推理机制也能让模型灵活调整偏好推断
总结
该工作第一作者为人大高瓴一年级博士生李嘉楠,目前在蚂蚁实习;蚂蚁通用人工智能研究中心自然语言处理实验室关健、武威为共同第一作者、通讯作者。
AlignXplore是大模型个性化路上的一个全新的尝试。在SOTA结果的背后,这项研究其实有很多思考:
-
在智力上限被一波又一波推高的当下,如何规模化训练大模型“情商”是一个没有得到足够关注却又十分重要的问题。毕竟谁会拒绝一个既聪明又有温度的AI呢?
-
深度思考下的长思维链是大模型智能能力的主要推动力。深度思考本身消耗巨大,那么如果只用来刷分,是不是有点浪费呢?相比于结果,推理过程中产生的知识是不是更有价值呢?AlignXplore可以看作是推理知识在用户理解领域进行迁移应用的一个尝试。毕竟相对于艰深的数学知识,用户理解知识更容易被看懂,也更容易落地。
-
如果客观问题都很快会被AI解决,那么主观问题该怎么办呢?这个世界上到底是客观问题多还是主观问题多呢?无论如何,研究团队认为个性化是通往主观世界的一条重要通道,而AlignXplore是在这条通道上的一次大胆尝试。期待未来有更多相关研究能够涌现。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)