


在人工智能快速发展的今天,我们已逐渐习惯于让 AI 识别图像、理解语言,甚至与之对话。但当我们进入真实三维世界,如何让 AI 具备「看懂场景」、「理解空间」和「推理复杂任务」的能力?这正是 3D 视觉语言模型(3D VLM)所要解决的问题。
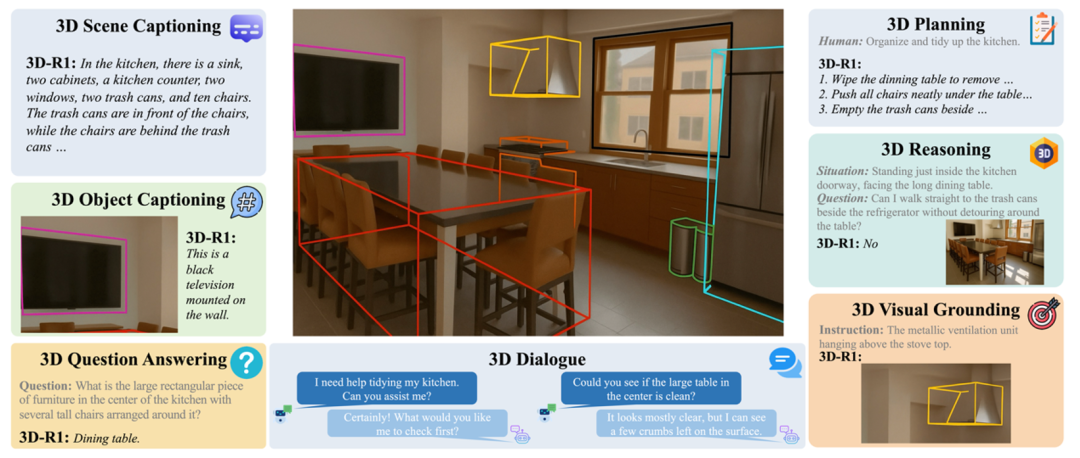
本文介绍的一项新研究 —— 3D-R1,提出了一种更通用、更具推理能力的三维视觉语言模型,它在多个 3D 任务中表现出了显著的性能提升,有望成为 3D 人工智能通用系统的新范式。

-
论文标题:3D-R1: Enhancing Reasoning in 3D VLMs for Unified Scene Understanding
-
论文链接:https://arxiv.org/pdf/2507.23478
背景:3D 场景理解为何重要?
让 AI 理解一个真实的三维环境,远比识别一张图片复杂得多。无论是服务机器人、自动驾驶,还是 AR/VR 应用,都离不开 AI 对空间结构、物体布局和多步任务的精准理解。但当前大多数 3D VLM 依然存在两大核心问题:
-
空间理解不足:许多模型依赖固定视角或简单全景拼接,导致遮挡物或关键结构难以准确识别;
-
推理能力薄弱:缺乏高质量的三维推理数据与奖励信号,模型难以进行深入的多步逻辑思考。
3D-R1:增强推理能力的 3D 通用模型
为解决上述挑战,研究团队提出了 3D-R1。它不仅聚焦于对 3D 场景的精准感知,还专门设计了增强「推理能力」的训练机制,使模型能像人一样「思考」和「判断」。
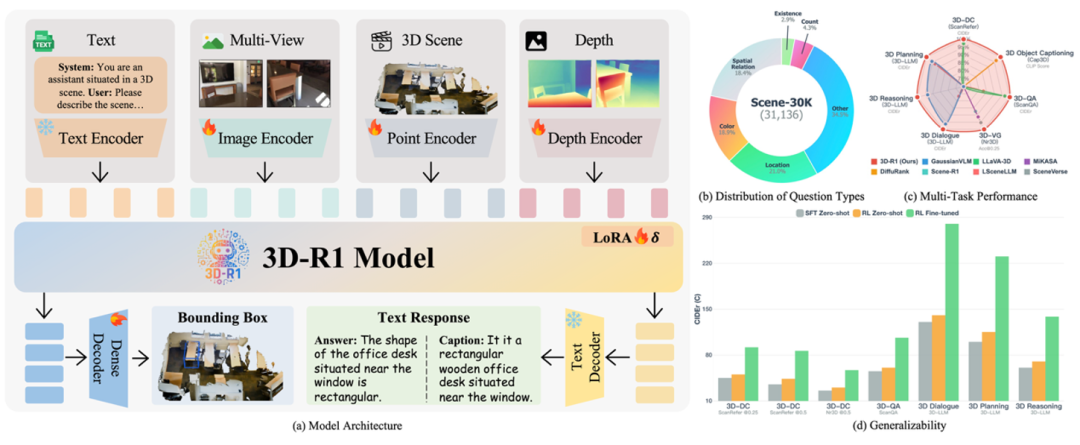
我们从三个关键方面对现有方法进行了创新:
(1)构建高质量推理数据集:Scene-30K
大多数 3D 数据集中,只包含简单的描述或问答,而缺乏真正多步逻辑的训练样本。为此,我们基于多个 3D 数据集(如 ScanQA、SceneVerse 等)合成了一个具有逻辑链条的高质量数据集 —— Scene-30K。
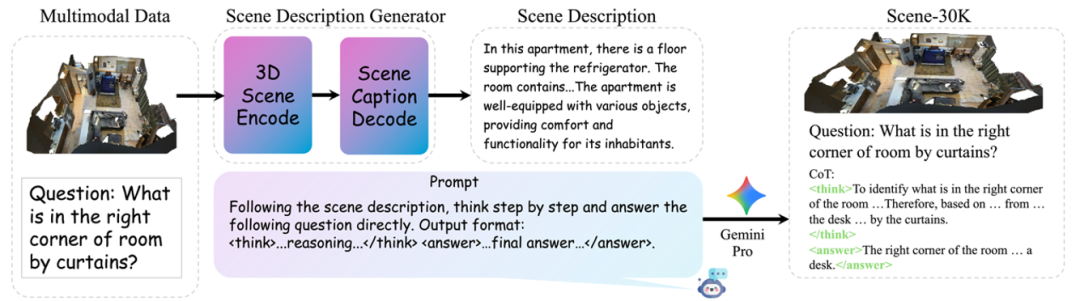
这个数据集的构造流程如下:
1. 场景描述生成:利用预训练 3D 模型对点云生成简洁的场景描述;
2. 推理链生成:将场景描述输入 Gemini 2.5 Pro 等大语言模型生成结构化的推理过程(Chain-of-Thought);
3. 规则过滤:对输出进行格式、逻辑一致性、答案正确性等过滤,确保质量。
最终,我们获得了 3 万条结构规范、逻辑清晰的训练样本,为模型提供「冷启动」训练支持。
(2)结合强化学习:让模型学会「思考」
在冷启动训练之后,我们引入了基于 GRPO(Group Relative Policy Optimization)的强化学习机制,让模型在生成回答的过程中不断自我优化。
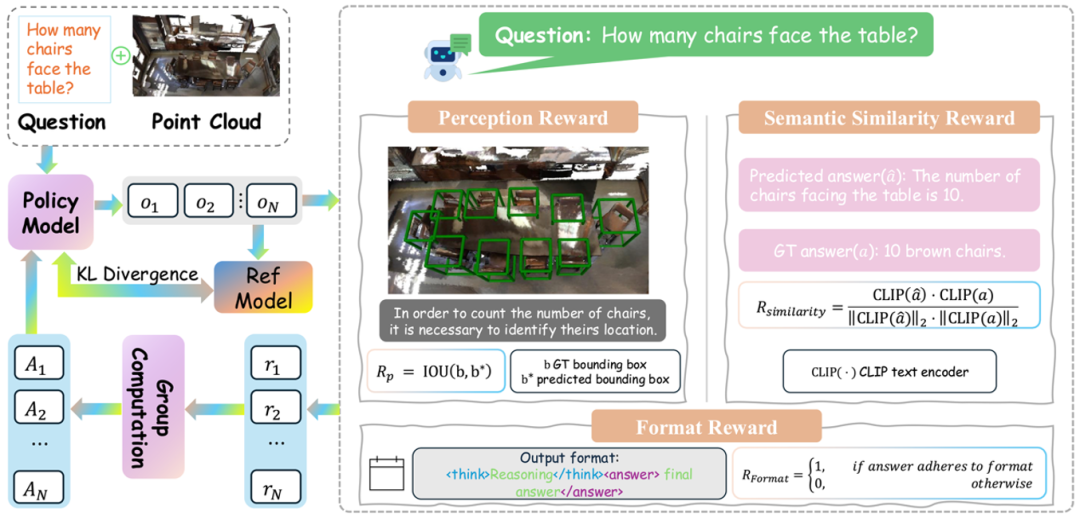
我们设计了三种奖励信号:
-
格式奖励:确保输出结构规范,例如必须包含 < think > 推理和 < answer > 答案格式;
-
感知奖励:通过预测框与真实框的 IoU 计算定位准确性;
-
语义奖励:使用 CLIP 编码器计算预测答案与真实答案的语义相似度。
这种方式使得模型不仅回答正确,而且过程清晰、结构合规、语义贴合,具备更强的泛化推理能力。
(3) 动态视角选择:看到更关键的信息
在三维场景中,不同视角包含的信息差异巨大。如果模型只能从固定角度看世界,往往会错过关键细节。为此,我们提出了一种动态视角选择策略,帮助模型自动选择 6 张最具代表性的视图。
这一策略结合三种评分指标:
-
文本相关性(Text-to-3D):视角是否与问题文本高度相关;
-
空间覆盖度(Image-to-3D):该视角是否补充其他视角遗漏的信息;
-
多模态对齐(CLIP 相似度):该视角与语言描述是否匹配。
最终,我们通过可学习的权重融合机制自动优化这些指标组合,选择对任务最关键的观察视角。
多任务基准测试:全面领先
3D-R1 在 7 个 3D 任务上进行了全面评估,包括:3D 问答(3D-QA)、密集描述(3D Dense Captioning)、物体描述(3D Object Captioning)、多轮对话(3D Dialogue)、场景推理(3D Reasoning)、动作规划(3D Planning)、视觉定位(3D Visual Grounding)。
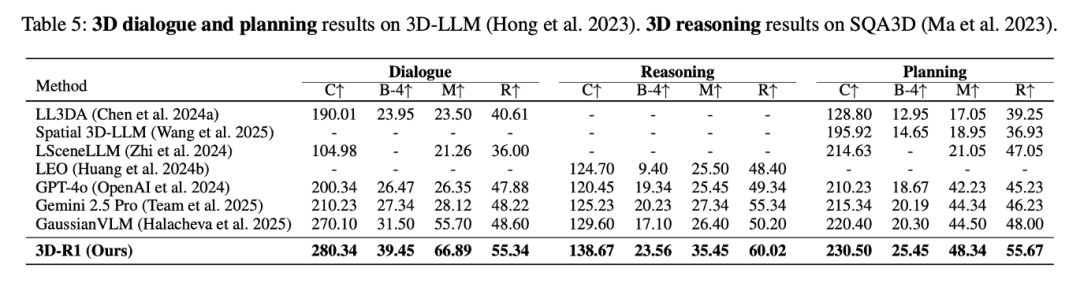
在 3D 场景密集描述任务中,3D-R1 在 ScanRefer 和 Nr3D 两个数据集上均超越了之前的专业模型。
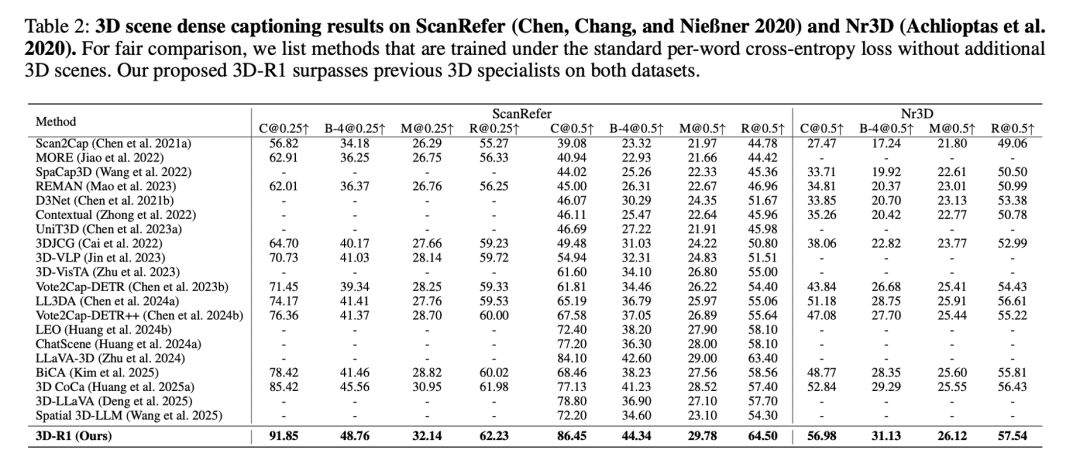
在最具挑战性的 3D 问答任务上,3D-R1 在 ScanQA 基准的验证集和两个测试集上都取得了最优成绩。
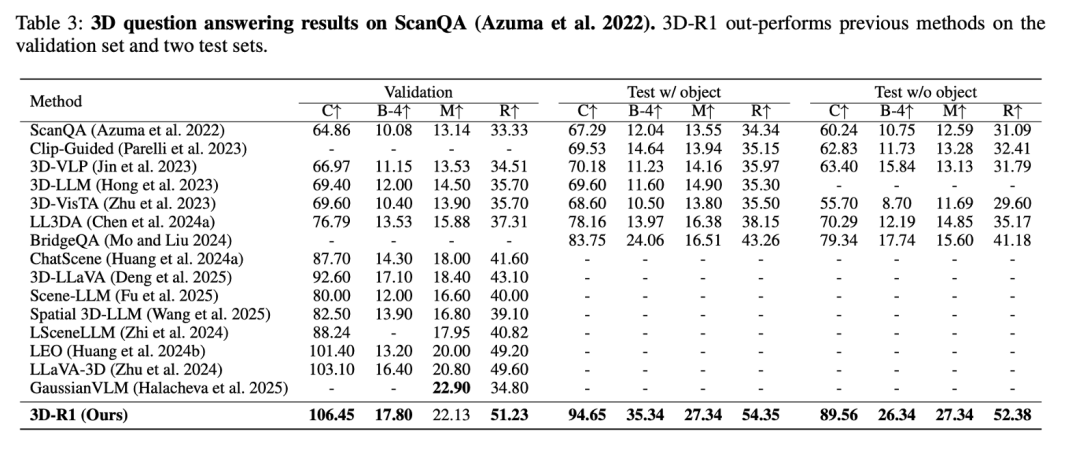
在更复杂的 3D 对话、规划和空间推理任务上,3D-R1 同样展现了其强大的综合能力。
这些结果证明了:无论是感知还是推理,3D-R1 都展现了更强的泛化能力和任务表现。
应用前景广阔
3D-R1 不仅在学术指标上领先,更具备实际应用价值。未来,它可以应用于:
-
家用机器人中:理解屋内物体位置并作出决策;
-
元宇宙 / VR:根据场景进行对话式引导和互动;
-
自动驾驶:理解复杂街景并实时应答;
-
工业检查:根据场景自动识别潜在风险区域。
3D-R1 不仅是一项模型技术创新,更是我们走向更强三维智能体的关键一步。未来,我们计划将其拓展至机器人控制、交互式问答、甚至自动家居整理等现实应用场景中。
本文作者介绍:
黄庭是上海工程技术大学电子电气工程学院在读硕士,研究方向聚焦于三维视觉语言模型、空间场景理解与多模态推理。曾参与多项科研项目,致力于构建具备认知与推理能力的通用 3D-AI 系统。
张泽宇是 Richard Hartley 教授和 Ian Reid 教授指导的本科研究员。他的研究兴趣扎根于计算机视觉领域,专注于探索几何生成建模与前沿基础模型之间的潜在联系。张泽宇在多个研究领域拥有丰富的经验,积极探索人工智能基础和应用领域的前沿进展。
唐浩现任北京大学计算机学院助理教授 / 研究员、博士生导师、博雅和未名青年学者,入选国家级海外高水平人才计划。曾获国家优秀自费留学生奖学金,连续两年入选斯坦福大学全球前 2% 顶尖科学家榜单。他曾在美国卡耐基梅隆大学、苏黎世联邦理工学院、英国牛津大学和意大利特伦托大学工作和学习。长期致力于人工智能领域的研究,在国际顶级期刊与会议发表论文 100 余篇,相关成果被引用超过 10000 次。曾获 ACM Multimedia 最佳论文提名奖,现任 ACL 2025、EMNLP 2025、ACM MM 2025 领域主席及多个人工智能会议和期刊审稿人。更多信息参见个人主页: https://ha0tang.github.io/

©
(文:机器之心)