
Tokenization谢幕?H-Net登场:Mamba作者新作正面硬刚Transformer
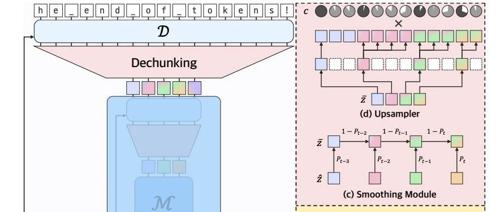
近年来语言模型取得了显著进展,主要得益于从特定任务专用模型转向通用的基于强大架构(如Transformer)模型的学习能力。作者之一Albert Gu提出了一种动态分块机制与层级网络相结合的新技术,能够自动学习内容和上下文相关的切分策略,并实现一个完全端到端训练的模型替代传统的分词→语言模型→反分词流水线。
近年来语言模型取得了显著进展,主要得益于从特定任务专用模型转向通用的基于强大架构(如Transformer)模型的学习能力。作者之一Albert Gu提出了一种动态分块机制与层级网络相结合的新技术,能够自动学习内容和上下文相关的切分策略,并实现一个完全端到端训练的模型替代传统的分词→语言模型→反分词流水线。

专注AIGC领域的专业社区分享了DeepSeek R1增强版Chimera的进展及其优越性能。该版本相较于R1-0528版本推理效率提升200%,同时在MTBench、AIME-2024等测试基准中表现出色。

全球首款AI原生UGC游戏引擎Mirage由顶尖机构联合打造,通过实时交互式’世界模型’和先进的扩散模型技术,支持玩家即时生成和控制游戏内容。它打破了传统预设游戏的限制,允许用户按照自己的想象扩展游戏世界。
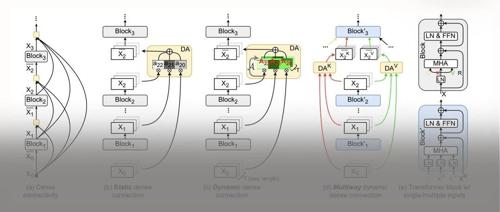
对Transformer中的残差连接进行了创新性改造,仅增加极少的参数和计算量,就让28亿参数的模型

AI大神何恺明正式入职谷歌DeepMind担任杰出科学家,保留MIT终身副教授身份。从微软亚洲研究院到Meta再到如今的谷歌,这位’学界+业界’跨界专家将助力实现AGI目标。
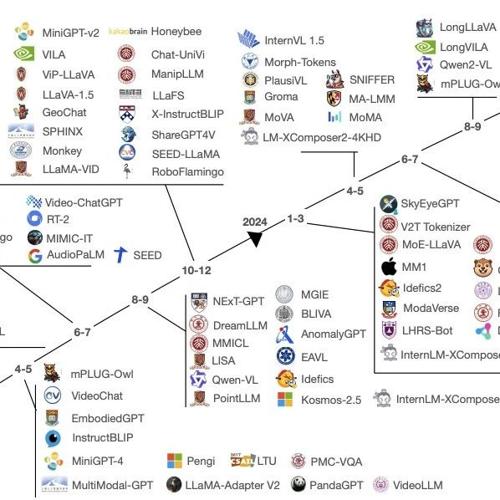
两篇论文综述了从2021年至2025年开发的至少125个多模态大型语言模型,涵盖文本到图像、音乐、视频、人类动作和3D对象等多种生成任务。文章强调自监督学习、专家混合等关键技术,并提出了MLLMs融合策略和技术分析框架。



