

德国知名技术咨询公司TNG开源了DeepSeek R1的增强版DeepSeek-TNG-R1T2-Chimera。
Chimera是基于DeepSeek的R1-0528、R1和V3-0324三大模型混合开发而成,同时采用了一种全新的AoE架构。这种架构在提升性能的同时,还能加快模型的推理效率并节省token输出。
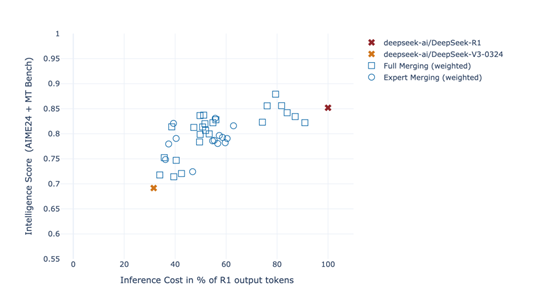
根据测试数据显示,Chimera版本的推理效率比R1-0528版本快200%,而推理成本却大幅度减少。在MTBench、AIME-2024等主流测试基准中,Chimera比普通R1性能更好。
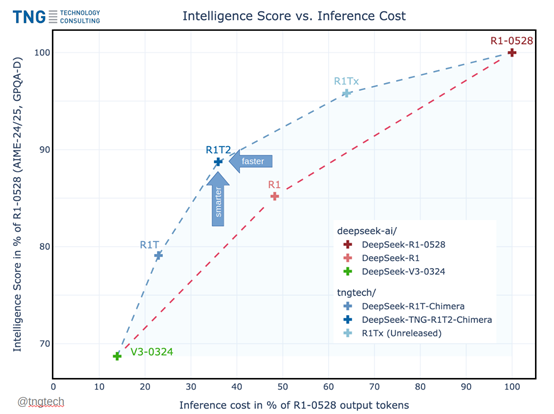
开源地址: https://huggingface.co/tngtech/DeepSeek-TNG-R1T2-Chimera
在深入了解AoE架构之前,我们先简单介绍一下混合专家(MoE)架构。MoE架构的核心是将Transformer的前馈层划分为多个“专家”,每个输入标记仅路由到这些专家的一个子集。这种架构在效率和性能方面都取得了显著的成果。
例如,Mistral在2023年发布的Mixtral-8x7B模型,尽管其在推理过程中激活的参数数量仅为13亿,却与拥有700亿参数的LLaMA-2-70B模型性能相当,且推理效率提高了6倍。
AoE架构的核心则是利用MoE的细粒度结构,通过线性时间复杂度从现有的混合专家父模型中构建出具有特定能力的子模型。
通过插值和选择性合并父模型的权重张量,生成新的模型变体,这些变体不仅继承了父模型的优良特性,还能够根据需要调整其行为表现。
AoE方法的起点是选择一组具有相同架构的模型,这些模型通常是通过对一个预训练模型进行微调得到的。研究者们选择了DeepSeek-V3-0324和DeepSeek-R1作为父模型。这两个模型都基于DeepSeek-V3架构,但经过不同的微调,分别在推理能力和指令遵循能力上表现出色。
为了构建新的子模型,研究者们首先需要准备这些父模型的权重张量。这些权重张量存储在模型的权重文件中,通过解析这些文件,可以直接访问和操作这些张量。
在准备好了父模型的权重张量之后,下一步是进行权重张量的插值与合并。这是AoE方法的核心步骤,通过这个步骤,研究者们可以生成具有不同特性的子模型。
研究者们定义了一个权重系数λi,用于控制每个父模型在合并过程中的贡献。在大多数情况下,这些权重系数是凸组合,即满足λi≥0且所有权重系数之和为1。这种设置允许研究者们在不同的父模型之间平滑地插值,生成一系列中间模型。
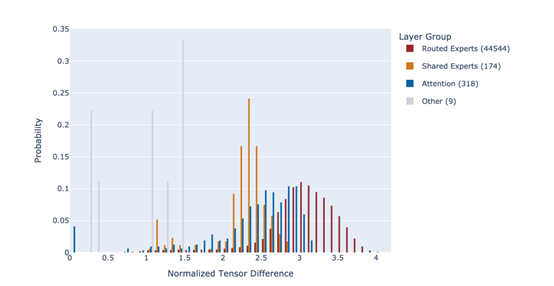
为了进一步优化合并过程,研究者们引入了阈值控制和差异筛选机制。这种方法的核心思想是,只有当某个张量在不同父模型之间存在显著差异时,才将其纳入合并范围。研究者们定义了一个阈值δ,只有当某个张量与基础模型之间的差异超过该阈值时,才会将其纳入合并范围。这种方法有效地避免了合并无关紧要的差异,从而减少了模型的复杂度和计算成本。
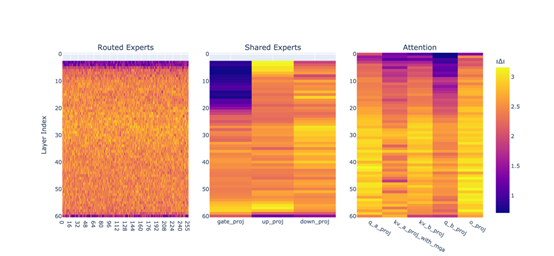
在MoE架构中,路由专家张量起着至关重要的作用。这些张量决定了每个输入标记在推理过程中被路由到哪些专家模块。在AoE方法中,研究者们特别关注了路由专家张量的处理。他们发现,通过合并不同父模型的路由专家张量,可以显著提升子模型的推理能力。
因此,在构建子模型时,研究者们不仅合并了父模型的权重张量,还特别关注了路由专家张量的合并。这种特殊处理使得子模型能够继承父模型的推理能力,同时保持高效的计算性能。
在确定了要合并的张量和权重系数之后,研究者们使用PyTorch框架实现了模型的合并。通过迭代访问父模型的权重文件中的每个张量对象,根据定义的权重系数和阈值,计算合并后的张量值。
这些合并后的张量值被保存到新的权重文件中,从而生成了新的子模型。这个过程不仅高效,而且可以灵活地调整合并策略,以生成具有不同特性的子模型。
(文:AIGC开放社区)