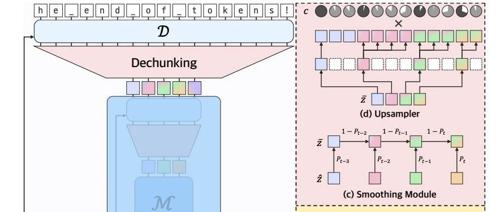
尽管近年来语言模型取得了惊人进展,这一进步主要源于从面向特定任务的专用模型转向基于强大架构(如 Transformer)的通用模型——这些模型能从原始数据中直接学习一切。然而,诸如分词(tokenization)之类的预处理步骤仍是构建真正端到端基础模型的障碍。
「Mamba」作者之一的Albert Gu最新Paper又提出一系列新技术,实现了一种动态分块机制(dynamic chunking):它能自动学习内容与上下文相关的切分策略,并与模型的其余部分联合训练。将该机制嵌入显式的层级网络(hierarchical network:H-Net),即可用一个完全端到端训练的模型替代“分词→语言模型→反分词”的传统流水线。
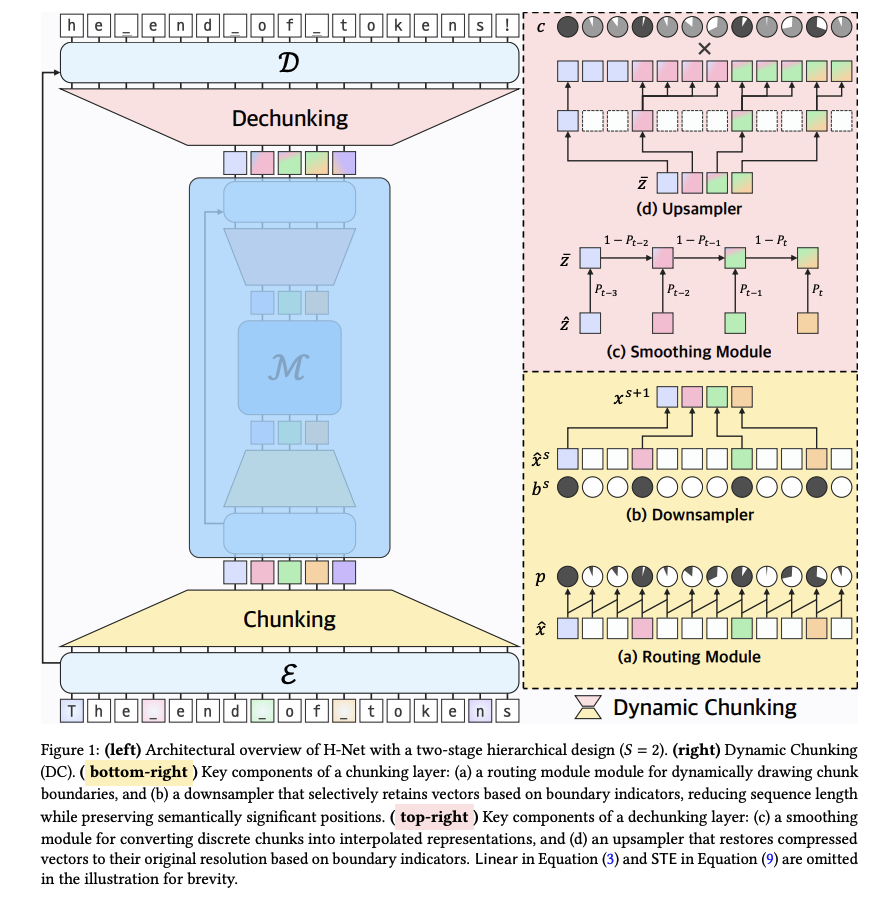
(a) 路由模块——动态决定分块边界;
(b) 下采样器——依据边界指示符保留关键向量,缩短序列长度并保留语义重要位置。
(c) 平滑模块——将离散块插值为连续表示;
(d) 上采样器——依据边界指示符将压缩向量恢复至原始分辨率。
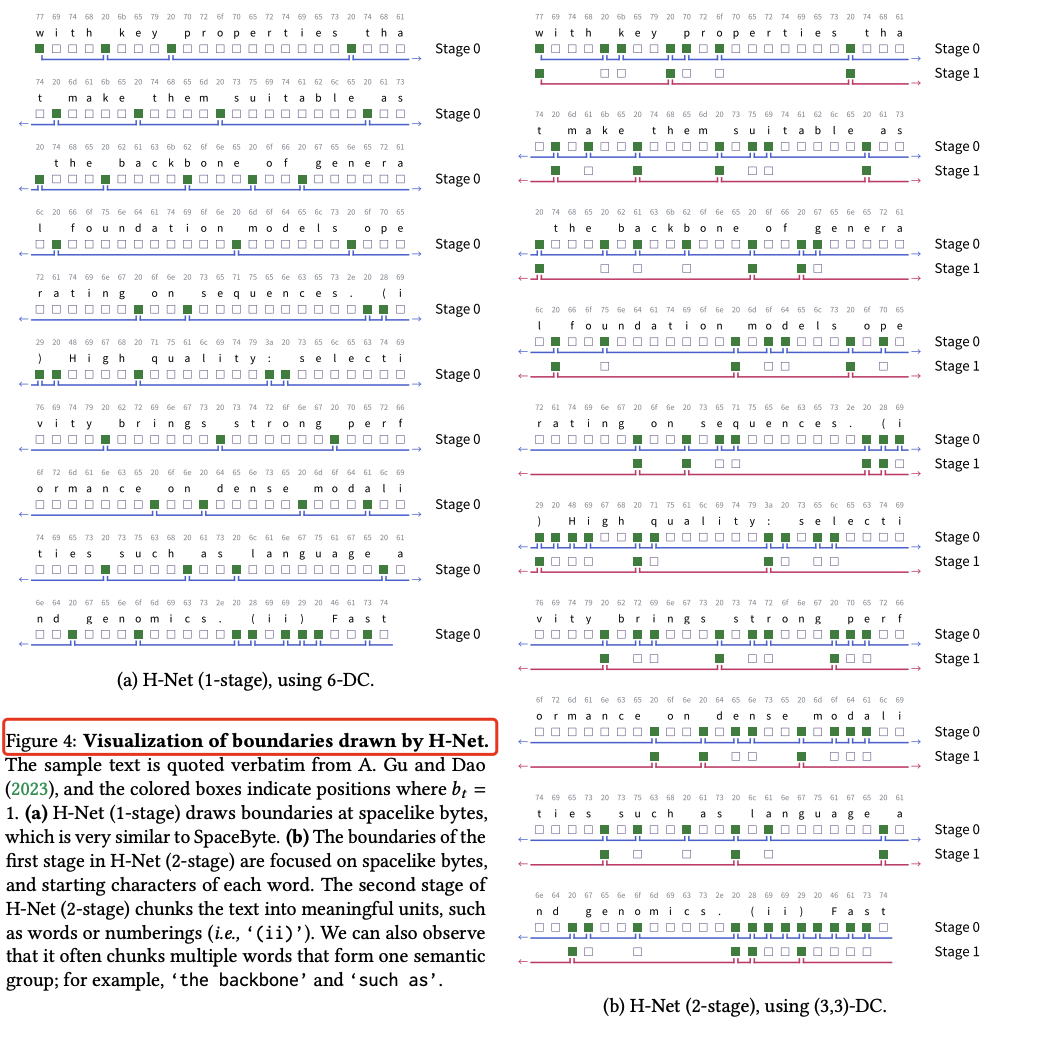
H-Net 所划边界的可视化。(a) 单阶段 H-Net 主要在“类空格”字节处划边界,与 SpaceByte 非常相似。(b) 两阶段 H-Net 的第一阶段同样聚焦于类空格字节和每个单词的首字符;第二阶段则将文本划分为更有意义的单元,如单词或编号(例如 ‘(ii)’)。还观察到,它常将多个语义相关的单词合并为一个块,例如 ‘the backbone’ 和 ‘such as’。
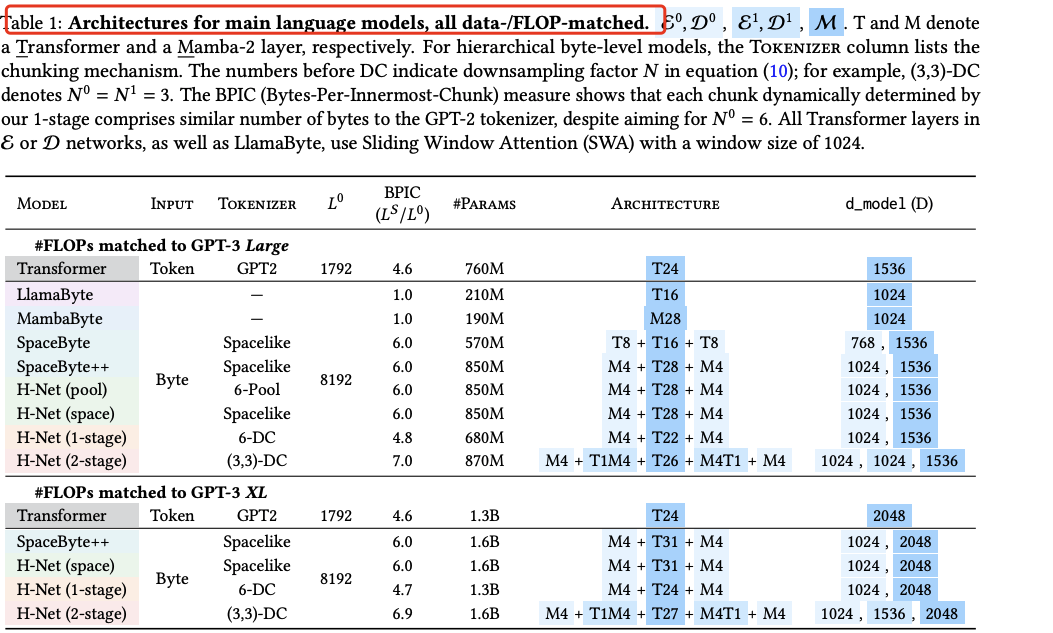
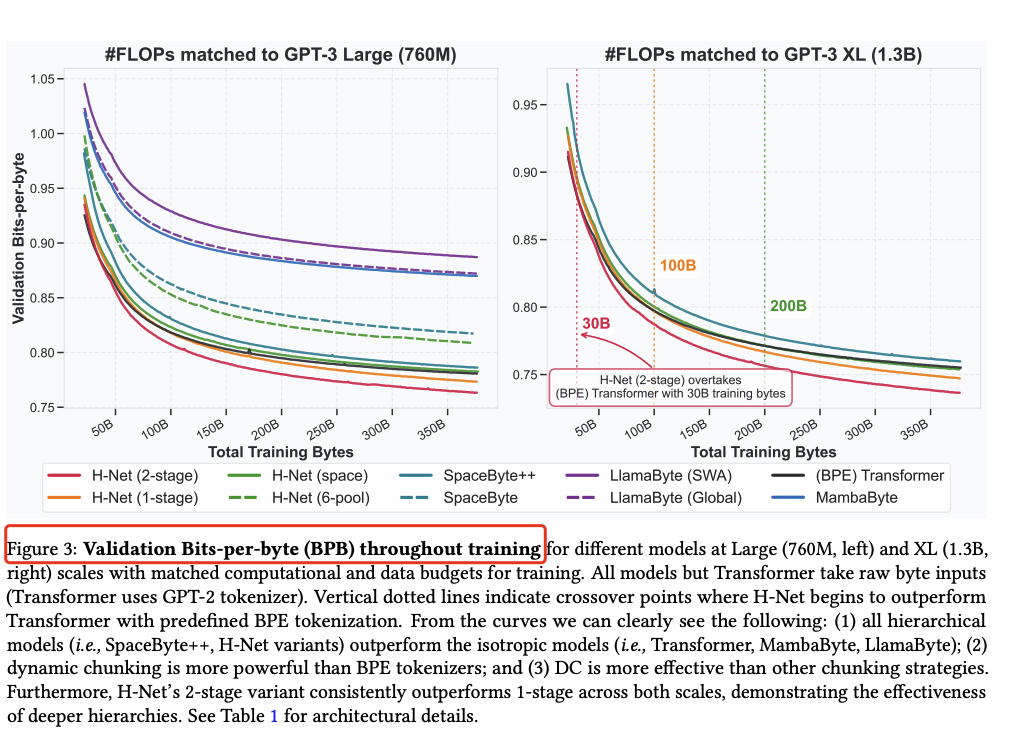
在算力与数据规模相匹配的条件下,仅在byte level运行的单级 H-Net 就能超越基于 BPE token 的强 Transformer 语言模型;将层级扩展为多级后,模型通过抽象层级的叠加进一步提效,数据扩展性显著优于传统模型,性能可与两倍参数量的 token 级 Transformer 相媲美。
| 英文(FineWeb-Edu) |
两阶段 H-Net 仅用 30B bytes 训练即超越 BPE Transformer(1.3B 参数)。
|
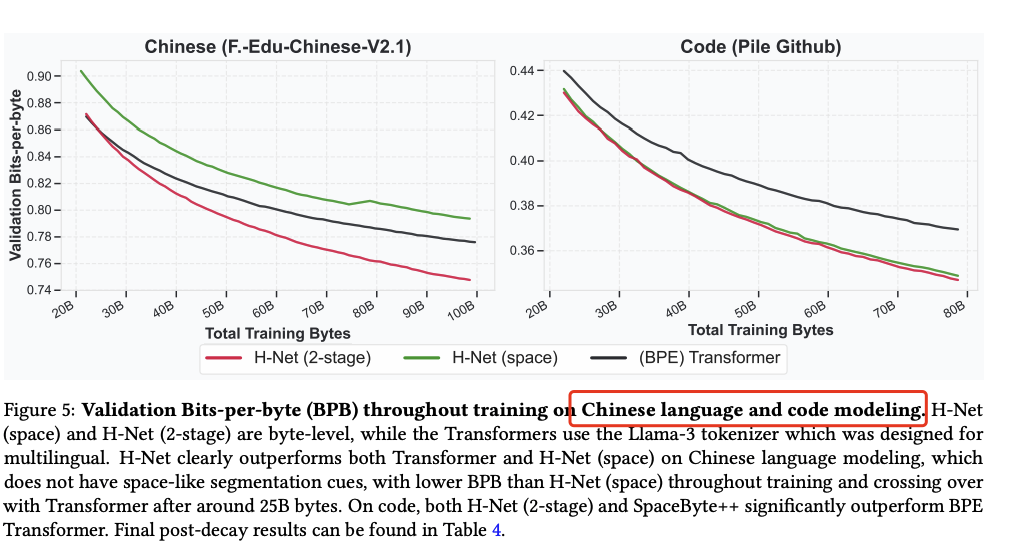
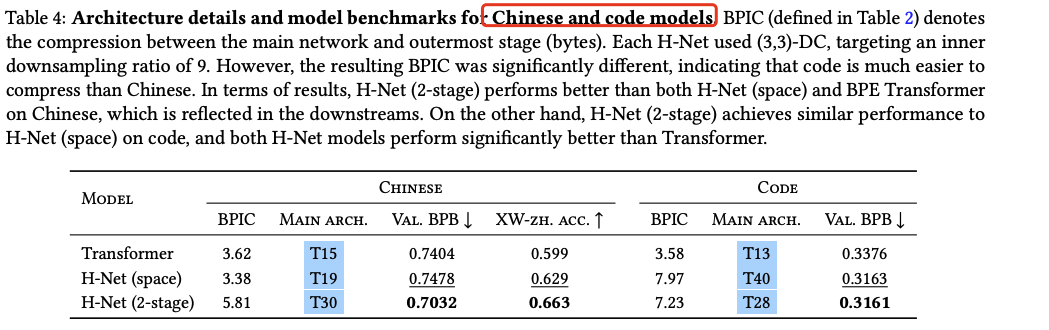
| 中文 |
在 XWinograd-zh 上准确率从 59.9 → 66.3,显著优于 BPE Transformer。
|
| 代码 |
压缩率更高,BPB 更低,表现优于 BPE Transformer。
|
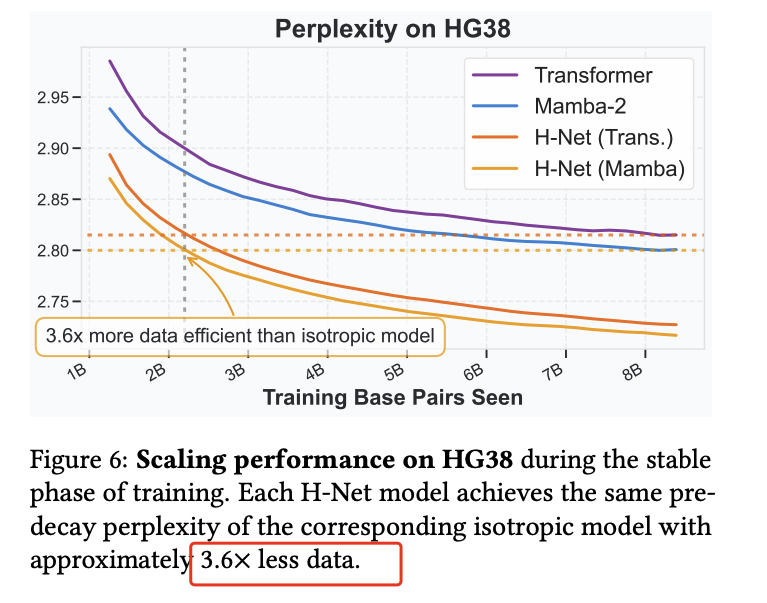
| DNA 序列 |
数据效率提升 3.6×,优于传统 isotropic 模型。
|
Dynamic Chunking for End-to-End Hierarchical Sequence Modelinghttps://arxiv.org/pdf/2507.07955https://goombalab.github.io/blog/2025/hnet-past/
(文:PaperAgent)