
U-Net和ViT凑一块,会发生什么?U-REPA:精准对齐Diffusion U-Net与ViT特征空间,训练提速42%
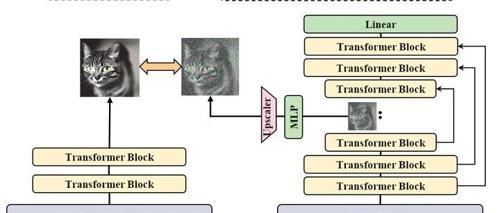
U-Net 架构对齐到 ViT(Vision Transformer)特征空间
的新方法
U-REP
U-Net 架构对齐到 ViT(Vision Transformer)特征空间
的新方法
U-REP

统一多模态模型的目标是整合深度理解与丰富的生成能力,MetaQueries采用‘token → [transformer] → [diffusion] → pixels’范式,通过可学习查询和冻结MLLM在保持性能的同时实现图像生成。

本文介绍了一种基于生成流网络的扩散模型奖励微调方法Nabla-GFlowNet,该方法能够在快速收敛的同时保持生成样本的多样性和先验特性。通过在Stable Diffusion上实验验证了其有效性。
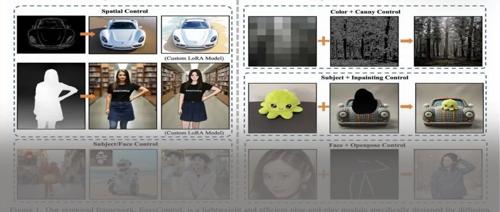
个面向DiT模型的条件生成框架
EasyControl
,通过条件注入LoRA模块、位置感知训练范式

GPT-4o 图像生成引起了广泛兴趣和猜测,OpenAI仅发布系统卡附录详细评估、安全和治理。网络上流传多种猜想及逆向工程猜测其可能采用自回归+扩散或非扩散的自回归生成方式。

FlexWorld团队提出一种新方法,通过合成和整合新的3D内容逐步构建灵活视角的3D场景。该方法结合了微调的视频到视频扩散模型和几何感知的3D场景扩展过程,能够有效生成大幅度相机变化下的高质量3D场景。

散模型的优势,解决了现有扩散模型生成长度受限、推理效率低和生成质量低的问题。通过块状扩散实现任意长度

LightGen 是由香港科技大学 Harry Yang 教授团队联合 Everlyn AI 和 UCF 提出的一种新型高效图像生成模型,旨在解决主流生成模型依赖大量数据和计算资源的问题。论文提出通过知识蒸馏和直接偏好优化策略,在有限的数据和计算资源下实现了高质量图像的生成,并在多个实验中展示了与 SOTA 模型相当甚至超过的性能表现。

