
2分钟玩转HeyGen最新模型:一张照片+一句话,秒出AI分身!超逼真!

HeyGen发布的Avatar IV模型能通过一张照片、一段脚本和声音生成逼真数字人,支持多角度图像输入,不仅能说还能唱。新引擎根据语音节奏自动生成表情和动作,应用场景广泛。
HeyGen发布的Avatar IV模型能通过一张照片、一段脚本和声音生成逼真数字人,支持多角度图像输入,不仅能说还能唱。新引擎根据语音节奏自动生成表情和动作,应用场景广泛。

256 生成上实现了最佳 (SOTA) 性能,FID得分为1.35,同时在短短64个epoch内就达
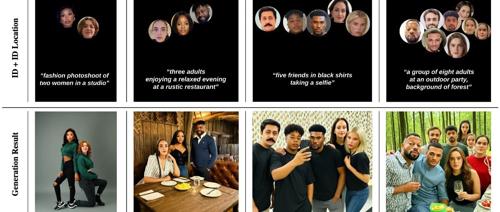
本文提出ID-Patch方案,用于解决多人图像生成中的身份特征泄露问题。通过ID Patch将身份特征转化为小尺寸RGB图像块,精确指定每个人的位置,并与文本提示共同输入增强人物面部真实性。实验结果显示其在身份还原和位置匹配上表现优秀,且生成效率快。

上海 AI Lab 开源的 Aether 项目通过三维时空建模和多模态融合技术,实现了生成式世界模型在虚拟数据上的出色表现,并具备对真实世界的零样本泛化能力。

达摩院在ICLR 2025提出了动态架构DyDiT,通过智能资源分配将DiT模型的推理算力削减51%,生成速度提升1.73倍,FID指标几乎无损,并且仅需3%的微调成本。

UniCombine 是一种基于 DiT 的多条件可控生成框架,能够处理任意条件组合。它在多种多条件生成任务上达到了最先进的性能,并且构建了首个针对多条件组合式生成任务设计的数据集 SubjectSpatial200K。
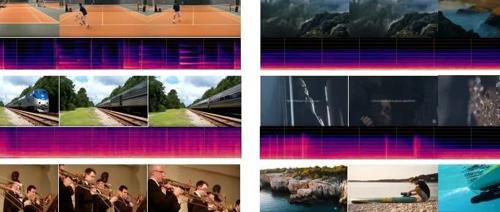
香港科技大学开发的 AudioX 机器学习模型能够根据用户的个性化输入生成独一无二的音频和音乐作品,包括文本、视频、图像等多模态数据,具有强大的跨模态学习能力,并能处理复杂的音频生成任务如音乐补全、修复等。

近日,大连理工大学与莫纳什大学的研究团队提出VLIPP框架,通过引入物理规律提升视频生成的物理真实性。论文指出视频扩散模型在物理场景下表现不佳的原因,并提出两阶段方法,利用视觉语言模型预测运动路径,再用细粒度的视频扩散模型生成符合物理规则的视频。
录用结果揭晓,腾讯优图实验室共有22篇论文入选,内容涵盖深度伪造检测、自回归视觉生成、多模态大语言模

北京大学的研究人员提出了一种名为MotionReFit的新模型,它可以根据用户的文本指令生成逼真的人体动作。该模型通过引入MotionCutMix数据增强技术及带有动作协调器的自回归扩散模型来实现这一目标,支持空间和时间上的动作编辑,无需特定的身体部位规范。