
类R1训练不再只看结果对错!港中文推出SophiaVL-R1模型

SophiaVL-R1 是一项基于类 R1 强化学习训练框架的新模型,它不仅奖励结果的准确性,还考虑了推理过程的质量。通过引入思考奖励机制和 Trust-GRPO 训练算法,SophiaVL-R1 提升了模型的推理质量和泛化能力,在多模态数学和通用测试数据集上表现优于大型模型。
SophiaVL-R1 是一项基于类 R1 强化学习训练框架的新模型,它不仅奖励结果的准确性,还考虑了推理过程的质量。通过引入思考奖励机制和 Trust-GRPO 训练算法,SophiaVL-R1 提升了模型的推理质量和泛化能力,在多模态数学和通用测试数据集上表现优于大型模型。

今天是2025年6月6日,星期五,北京晴。文章回顾了大模型相关技术进展,包括针对性学习、推理数据收集、多模态应用及强化学习评估偏差等内容。关键点在于明确问题并针对性学习,学会提问和理论与实践结合,以提升大模型性能。

近期清华大学团队提出的研究表明,在强化学习训练大模型时,仅使用20%的高熵token就能显著提升模型性能。研究指出80%低熵token会影响模型推理能力,并可能起到负面作用。
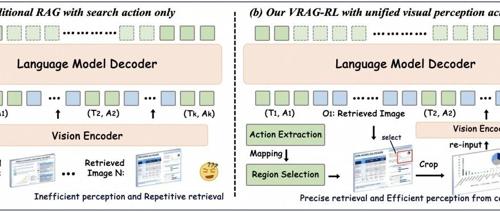
最新研究成果VRAG-RL通过引入强化学习和多模态智能体训练,解决视觉丰富信息检索增强生成任务中的挑战,显著提升了视觉语言模型在检索、推理和理解视觉信息方面的能力。

NVIDIA团队提出ProRL框架,在2000步以上长期强化学习基础上,大幅提升大语言模型的推理能力。ProRL训练后模型在逻辑谜题等任务中表现出显著进步,不仅提高了解题准确率,还能生成新解法。研究揭示了长期RL训练的重要性及其对模型边界扩展的影响。
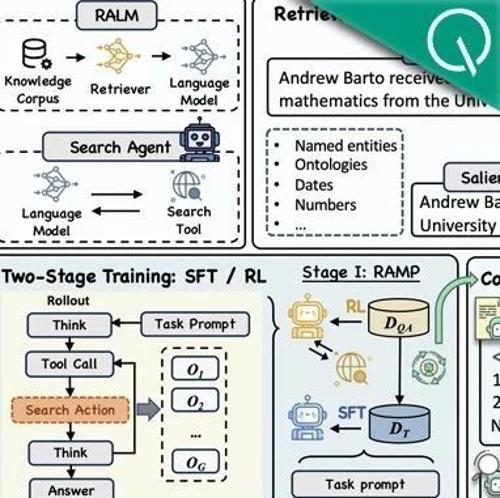
阿里通义实验室发布MaskSearch预训练框架,提升大模型推理搜索能力,在多个开放域问答数据集上显著性能提升。该框架结合检索增强型掩码预测任务与监督微调、强化学习两种训练方法。



