快慢Reasoning综述!

MLNLP社区致力于促进国内外NLP学术与产业发展间的交流合作。文章介绍了一种双层效率优化框架,包括可控计算(L1)和自适应计算(L2),通过大量实验揭示了语言模型在复杂推理任务中的低效性问题,并提出了一系列解决方案以提升其效能。
MLNLP社区致力于促进国内外NLP学术与产业发展间的交流合作。文章介绍了一种双层效率优化框架,包括可控计算(L1)和自适应计算(L2),通过大量实验揭示了语言模型在复杂推理任务中的低效性问题,并提出了一系列解决方案以提升其效能。

伊利诺伊大学香槟分校开发的Time-R1模型通过三阶段强化学习训练提升了语言模型的时间推理能力,包括时间戳推断、事件排序和生成合理未来场景等任务。该模型在多个时间推理任务中表现优异,并开源了代码和数据集以促进研究和技术发展。

阿里通义团队提出的新范式PARSCALE通过扩展CFG的双路径到P条并行路径,显著提升了1.6B模型的性能,仅占用后者的1/22内存,并将延迟增加量减少至1/6。该方法无需从头训练现有模型(如Qwen-2.5),并在GSM8K数学推理任务中实现了34%的性能提升。
Alation 宣布收购 AI 初创公司 Numbers Station,计划将其产品整合至自有平台以提供更全面的数据管理和 AI 解决方案。

综述了 LLM-SLM 协同机制的最新研究进展,包括流水线式协同、路由机制、辅助性联动、知识蒸馏和模型融合等多种交互机制,系统梳理了关键支撑技术及多样化的应用场景需求,展示了该范式在构建高效、适配性强的人工智能系统的巨大潜力,并深入探讨了系统开销、模型间一致性等持续挑战。
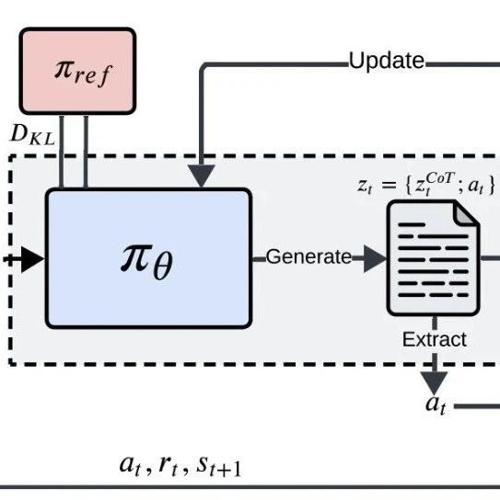
MLNLP社区是国内外知名的机器学习与自然语言处理社区,旨在促进学术界、产业界和爱好者的交流与进步。最新论文揭示了大模型决策中的三大缺陷,并通过强化学习微调结合思维链技术提升其决策能力。