
机器狗能当羽毛球搭子了!仅靠强化学习从0自学,还涌现出类人回位行为 Science子刊

机器狗通过强化学习学会了打羽毛球,最高挥拍速度达12米/秒,在与人类选手的协作比赛中展示了精准和类人行为。研究结果发表在Science Robotics上。
机器狗通过强化学习学会了打羽毛球,最高挥拍速度达12米/秒,在与人类选手的协作比赛中展示了精准和类人行为。研究结果发表在Science Robotics上。
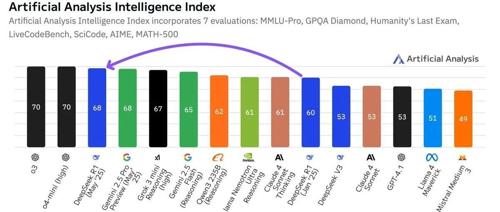
DeepSeek R1 0528 版本在Artificial Analysis的最新排名中得分68分,几乎与闭源模型持平。这反映了开源模型与闭源模型之间差距的进一步缩小,强化学习在提升AI性能方面的效率凸显,并标志着中美两国在人工智能技术领域的齐头并进新阶段。

DeepSeek R1-0528版本超越xAI、Meta等成为全球第二大人工智能实验室,并与谷歌并列。其智能指数得分从60分跃升至68分,超过多个顶级模型,提升主要体现在数学竞赛、代码生成和推理方面。
UC Berkeley团队提出的新方法Intuitor通过优化模型自身的置信程度来提升大模型的复杂推理能力,无需外部奖励信号或标准答案。与传统强化学习相比,Intuitor能有效减少无效响应并提高模型在数学和代码生成任务中的表现。

本文提出ZeroSearch框架,无需真实搜索引擎即可激活大语言模型搜索能力。通过轻量级监督微调将LM转为检索模块,并采用课程学习逐步降低文档质量来激发推理能力,显著降低训练成本和提高性能。
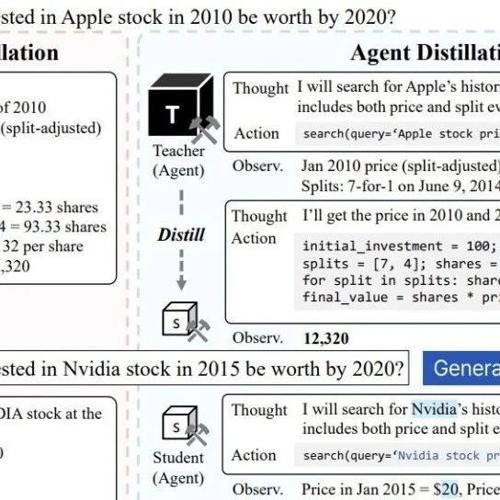
MLNLP社区是国内外知名的机器学习与自然语言处理社区。该社区致力于促进学术界、产业界和爱好者间的交流与进步,特别是针对初学者的提升。近期有论文提出Agent蒸馏技术,通过使用检索工具和代码工具让小模型学会像人类一样解决问题,显著提升了小模型在某些任务上的性能。

2025年5月28日,北京晴。文章探讨了从几张图看RAG及Agent的问题和基于自我置信度作为强化学习监督信号的工作,强调实际业务数据的重要性,并指出不要过度依赖Agent智能体解决问题。


