

今天是2025年6月6日,星期五,北京,晴
我们来回顾下大模型相关技术0605进展,围绕社区如何学习讨论,大模型实操项目集合,强化学习评估偏差,多模态一键换装,Deepseek-R1-0528蒸馏数据等进展,供各位参考。
其中,尤其是如何针对性的学习,是很多人的困境,所以来谈谈。
一、如何针对性的学习-带着问题去学习
社区昨天有个很有趣的话题,问题是“想要用大模型抽取三元组,但是理论基础掌握的不够,能指点我一下都补一下啥基础知识”
这个其实引申出来一个很有趣的学习命题,我们来看看。
你觉得需要什么基础知识?先问下自己,你缺啥?你已经知道你掌握的不够,怎么不够?缺什么呢?应该是你遇到了什么问题,缺啥补啥好一些。带着问题去补,不要为了补而补。如果看论文深入不了,一到底层公式就不明白,只能停留在应用层面,那就去看公式,但是,即便看懂公式了,然后呢?就如,我觉得我不懂python,要补一下。然后会了又如何呢?会发现实际开发与学的很不一样,关键还是要解决问题。比如因为这个缺的东西,阻碍了我解决某个问题,干中学,不是学后干。不要觉得自己缺啥去干啥,而是自己解决某个问题时发现缺啥,再去干啥。
但是有时候不知道某个问题缺什么怎么办?那就不干,因为你连问题都分析不清楚,说明这件事大概率不成立,或者说问题建模的还不到位。学会提问,学会把问题描述清楚,其实答案已经有了50%,就如上面那个知识图谱三元组抽取,是具体什么问题?任务明确。只是你要解决这个任务。问题应该是,你用什么方案去做,微调还是对齐,还是强化,还是什么。那么,必然是你目前所用的方案,没效果,或者指标很低?或者什么的。那么为什么指标低,问题是啥。这个需要去分析,才能分析出来你缺啥。你即便把强化学习公式,买个图谱的书读完,懂了更多的概念,然后呢?没意义的。因为学无止境。你为了理解一个概念,会牵扯出10个,10个又会扯出100个新概念。越学越多,然后你的问题依旧没解决。也就是递归学习,好没效率的。这也是很多人的困境。
所以,记住一个三字词,干中学,四字词,以终为始,五字词,学会提问题,六个字,问题驱动过程。七个字,理论与实践结合。就如上面这个抽取的问题,知道什么是三元组,什么是LLM,然后就去干就完了,这点东西还是要知道的,其他的就是解决问题了,干的时候会遇到各种问题,挨个解决就是学习的过程了。而进一步的,我们遇到问题了,会直接想着找方案,比如RAG微调+rag后,问答效果一般,那么也需要先分析清楚是哪出的问题,是chunk切分,还是召回,还是大模型的问题,得找到根。
二、大模型推理、多模态、RAG等处理进展
1、推理数据进展
AM-DeepSeek-R1-0528-Distilled(https://huggingface.co/datasets/a-m-team/AM-DeepSeek-R1-0528-Distilled),从DeepSeek-R1-0528(DeepSeek-R1大型语言模型的改进版本)中提炼出来的高质量推理语料库。与初始版本相比,DeepSeek-R1-0528在推理、指令遵循和多轮对话方面展现出显著的进步。受这些改进的启发,使用DeepSeek-R1-0528作为教师模型,收集并提炼了260万条来自多个领域的多样化查询。
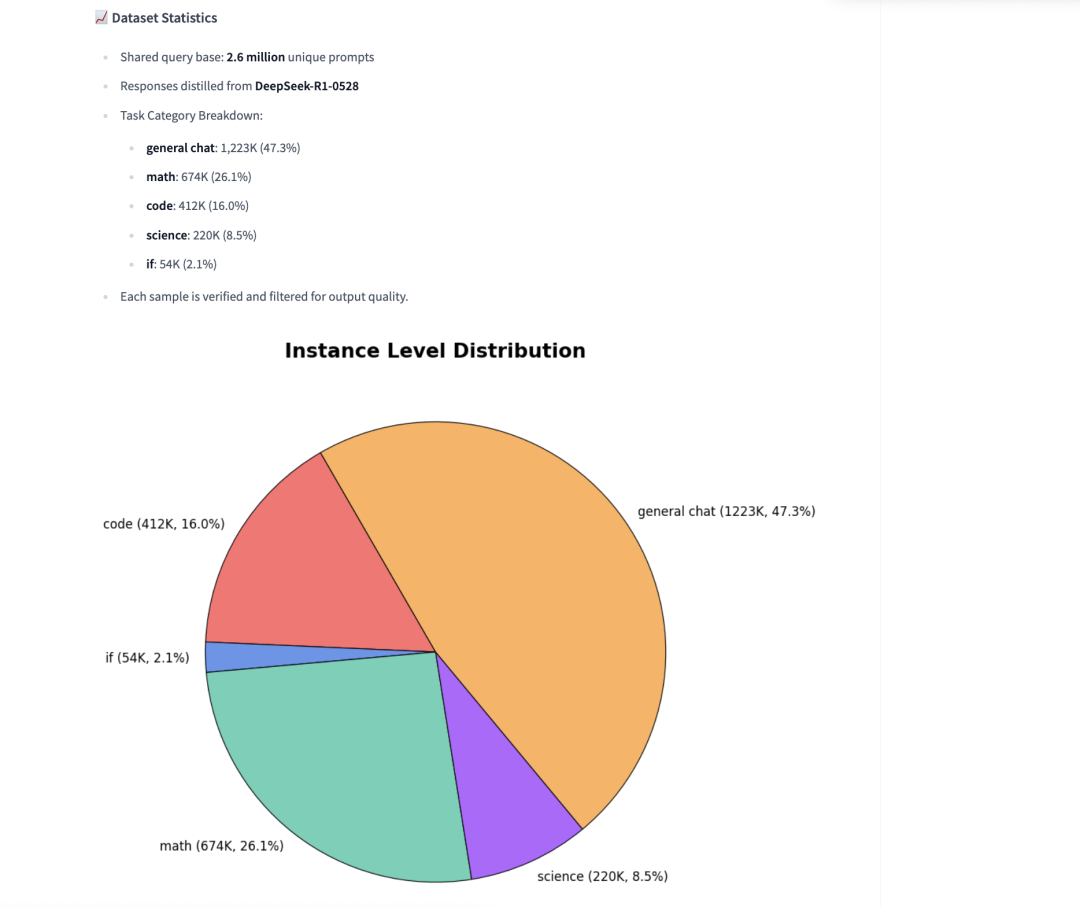
DeepSeek-R1-0528的一个显著特点是其输出比之前的版本长得多,尤其是在数学方面:对于某些数学问题,输出长度比前几代长1.5到2倍。这反映了更详细、更清晰的逐步推理。使用Qwen2.5-32B对该数据集进行训练,AIME2024可以达到87.1,R1是91.4.
2、多模态进展
MagicTryOn视频虚拟试穿项目(https://vivocameraresearch.github.io/magictryon/,https://github.com/vivoCameraResearch/Magic-TryOn/),

替换传统的U-Net架构为更具表现力的扩散Transformer(DiT),结合全自注意力机制,实现视频的时空一致性建模,有意思。
3、RAG有趣新尝试
RAG的有趣新尝试:将文本编码进MP4文件实现思路及Agentic-doc处理文档,https://mp.weixin.qq.com/s/gxuX_gTH13zoLsRcPFAQkg

4、强化学习进展
尤其是关于最近不用外部监督信号进行强化的工作思考,https://safe-lip-9a8.notion.site/Incorrect-Baseline-Evaluations-Call-into-Question-Recent-LLM-RL-Claims-2012f1fbf0ee8094ab8ded1953c15a37,分析了7篇热门的大型语言模型(LLM)强化学习论文(在X社交平台上的点赞数从100+到3000+不等,浏览量从5万+到50万+不等),其中包括《SpuriousRewards》、《RLfrom1example》以及3篇探讨“内在置信度奖励”的论文。
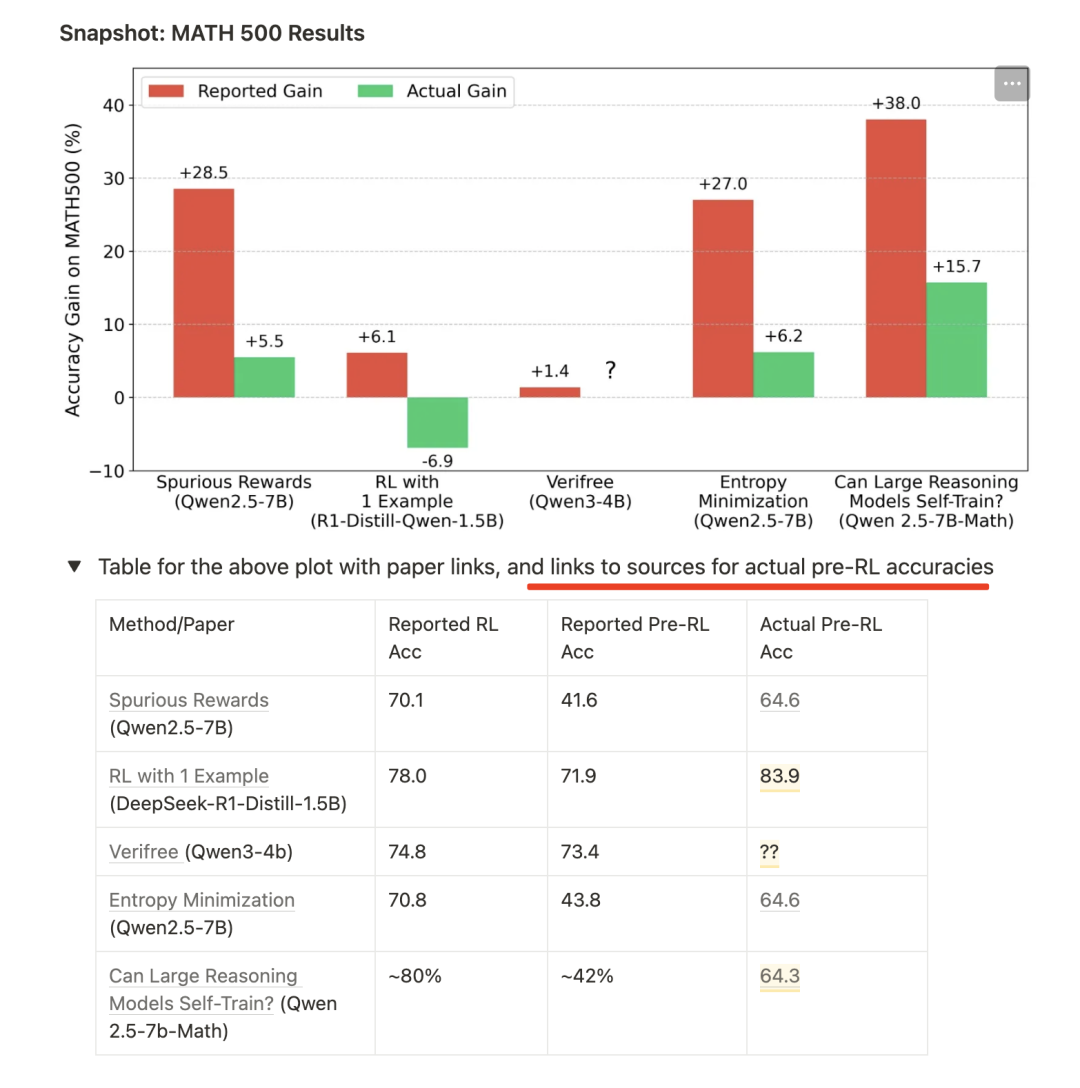
里面有个结论很有趣。在这些论文中的大多数情况下,不同强化学习方法带来的改进实际上并不明确,在相当多的情况下,经过强化学习训练后的模型性能实际上比它们起始时(正确评估的)预强化学习基线还要差。
当然,这其实也说明了当前大模型的评估实际上是相对结论,很难成为标准的绝对性的确定性结论。
5、大模型实操项目集合
Unsloth整理了一个大模型微调的notebook仓库,目前已经超过100份JupyterNotebook,https://github.com/unslothai/notebooks/,
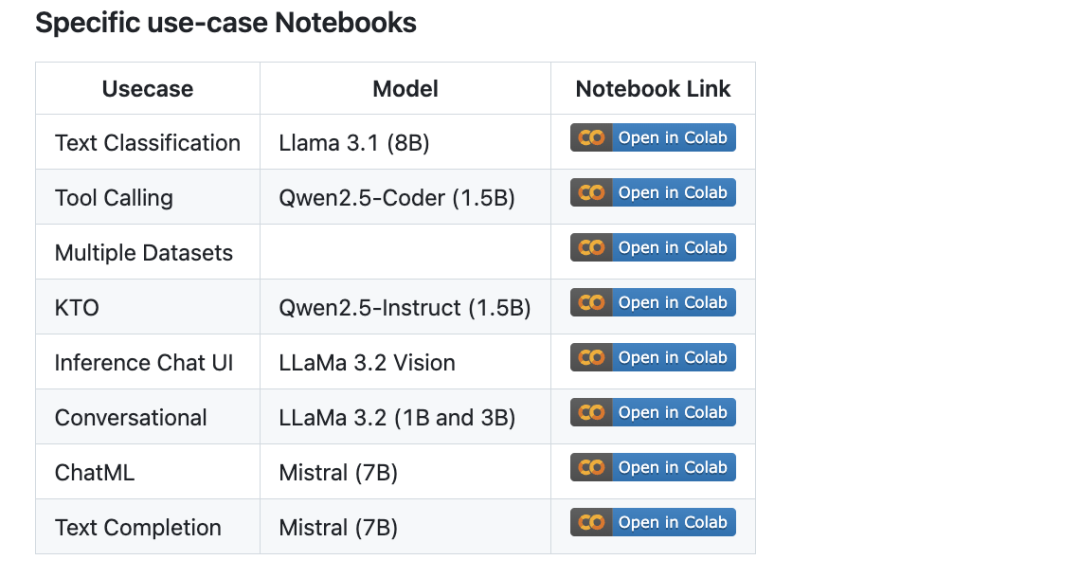
内容涉及:Tool-calling,Classification,Syntheticdata、BERT,TTS,VisionLLMs、GRPO,DPO,SFT,CPT、Dataprep,eval,saving、Llama,Qwen,Gemma,Phi,DeepSeek等模型。
(文:老刘说NLP)