华为昇腾推理对决:开源vLLM vs 官方MindIE,数据说话「Qwen与DeepSeek推理实测」

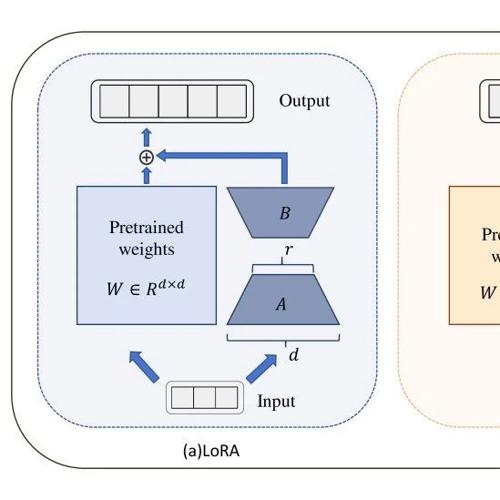
表现良好的 MindIE 推理引擎
,并原生支持 Atlas 800 A2 系列和 Atlas 30
表现良好的 MindIE 推理引擎
,并原生支持 Atlas 800 A2 系列和 Atlas 30

MiniMax举办开源周活动,正式发布最新推理模型MiniMax-M1,支持100万token输入与8万token输出,参数量达4560亿。通过大规模强化学习训练,仅耗资53.47万美元。该模型采用混合注意力架构和闪电注意力机制,显著提升推理效率,并在复杂任务中表现突出。
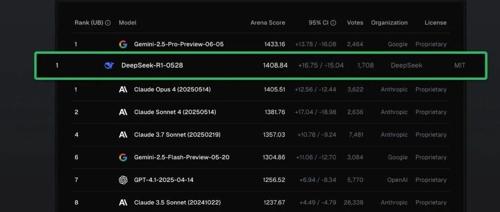
DeepSeek 更新其R1推理模型至0528版本,提升性能并参加LMArena大模型公共基准测试平台的排行榜,DeepSeek-R1(0528)在文本、编程、数学等多个领域排名领先。
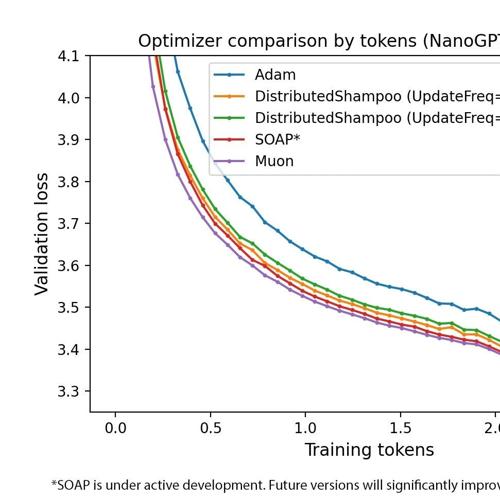
Keller Jordan介绍其优化器Muon,用于神经网络隐藏层参数优化,在NanoGPT和CIFAR-10应用中显著提高训练速度,并与原文献链接。
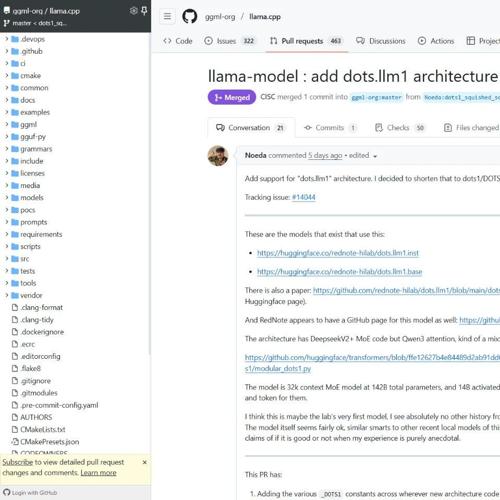
小红书大模型 dots.llm1 已经被 llama.cpp 支持,本地用户可以使用 llama.cpp 作为推理引擎生成小红书风格内容。

PDF等非结构化数据精准地转换成结构化数据(如Markdown、JSON)已成为行业待解决的关键问题

AI教父Hinton为了给有学习障碍的儿子攒养老钱,将自己的神经网络公司卖给谷歌。但正是这次经历让Hinton意识到AI的潜在风险,并开始成为警告AI风险的先知。