
Claude Opus
刚刚,LMArena最新模型榜单出炉!DeepSeek-R1网页编程能力赶超了Claude Opus 4
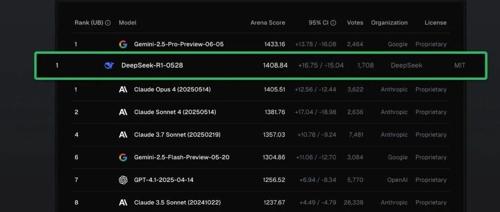
DeepSeek 更新其R1推理模型至0528版本,提升性能并参加LMArena大模型公共基准测试平台的排行榜,DeepSeek-R1(0528)在文本、编程、数学等多个领域排名领先。
Claude与人类共著论文,苹果再遭打脸!实验黑幕曝光

苹果论文被反击,OpenPhilanthropy研究人员揭露大模型在汉诺塔实验、自动评估框架等方面存在缺陷,指出部分测试用例无解却让模型‘背锅’的华点。
炸裂!Claude以第一作者写论文反驳苹果「推理模型根本没有推理能力」:苹果有三大错误

苹果发表《The Illusion of Thinking》论文指责大语言模型缺乏推理能力。Claude Opus反驳指出问题源于实验设计局限性而非AI本质缺陷,指出了论文中的三大关键问题,并提出新的评估方法来区分’推理能力’与’简单打字输出’。
AI编码力压群雄!Anthropic上线最强模型Claude 4系列,“举报”模式引争议

美国AI公司Anthropic发布新一代编码模型Claude Opus 4和Sonnet 4,性能提升高达10%,在SWE-bench上达到业内最先进水平。模型支持多种模式并能通过扩展接口连接到数据库、API等工具,引发了开发者们的广泛好评。
Anthropic发布Claude 4:工程师级AI,而不是更聪明的搜索框或对话机器人
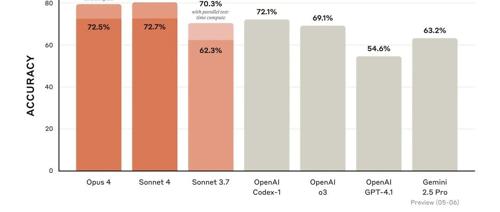
Anthropic联合创始人Dario Amodei在Code with Claude开发者大会上表示,Claude正式进入全链条开发力和标准构建的全新竞争时代。旗舰模型Claude Opus 4延续了推理、代码能力方向,并且表现出色。新功能如‘思维摘要’与‘扩展思维’模式提升用户满意度。API定价及安全级别显著提升,为更多行业提供可靠支持。