

MiniMax正在举行为期5天的开源周活动!首日正式开源最新推理模型MiniMax-M1,重新定义长文本推理新标杆- 全球最长上下文窗口:
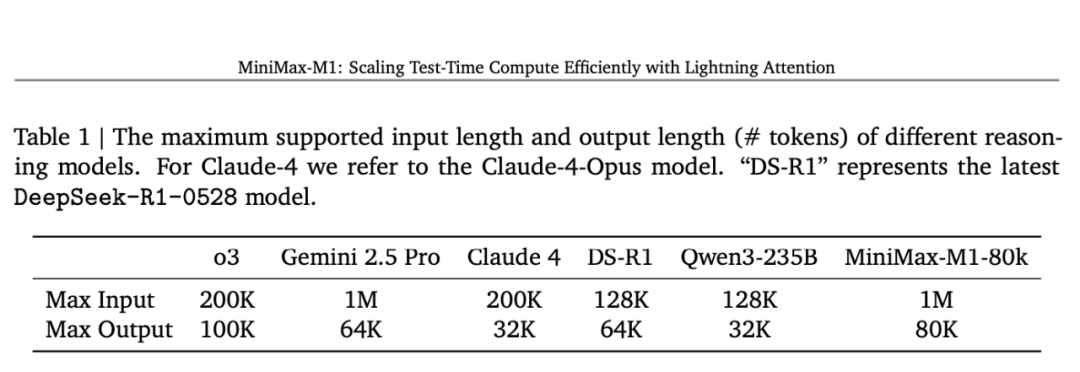
支持100万token输入,8万token输出
开源模型中最先进的智能体应用表现
突破性训练效率:仅耗资53.47万美元完成强化学习训练

MiniMax是全球首个开放权重的混合注意力大规模推理模型——MiniMax-M1。
该模型采用创新的混合专家架构(MoE)与闪电注意力机制相结合的设计方案,基于此前发布的MiniMax-Text-01模型(MiniMax et al., 2025)研发而成,总参数量达4560亿,单token激活参数为459亿。M1模型原生支持100万token的上下文长度,是DeepSeek R1上下文窗口的8倍。其搭载的闪电注意力机制显著提升了推理计算效率——以10万token生成为例,M1的浮点运算量仅为DeepSeek R1的25%。这些特性使M1特别适合需要处理长文本输入和深度思考的复杂任务
在训练方面,MiniMax-M1通过大规模强化学习(RL)覆盖了从传统数学推理到沙盒式现实软件工程环境的多样化场景。除了闪电注意力机制自带的RL训练效率优势外,还提出了创新性RL算法CISPO:该算法通过裁剪重要性采样权重而非token更新的方式,显著优于其他主流RL变体。混合注意力架构与CISPO算法的结合,使得MiniMax-M1在512张H800 GPU上的完整RL训练仅需三周即可完成,租赁成本低至53.47万美元。同步开放了4万和8万思维预算的两个版本,其中4万版本是8万完整训练过程的中间阶段
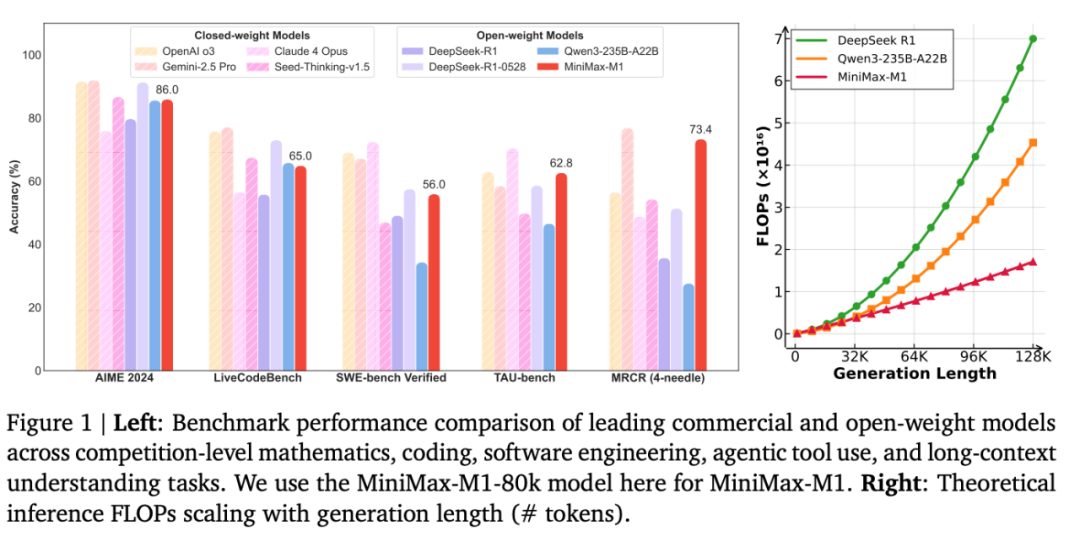
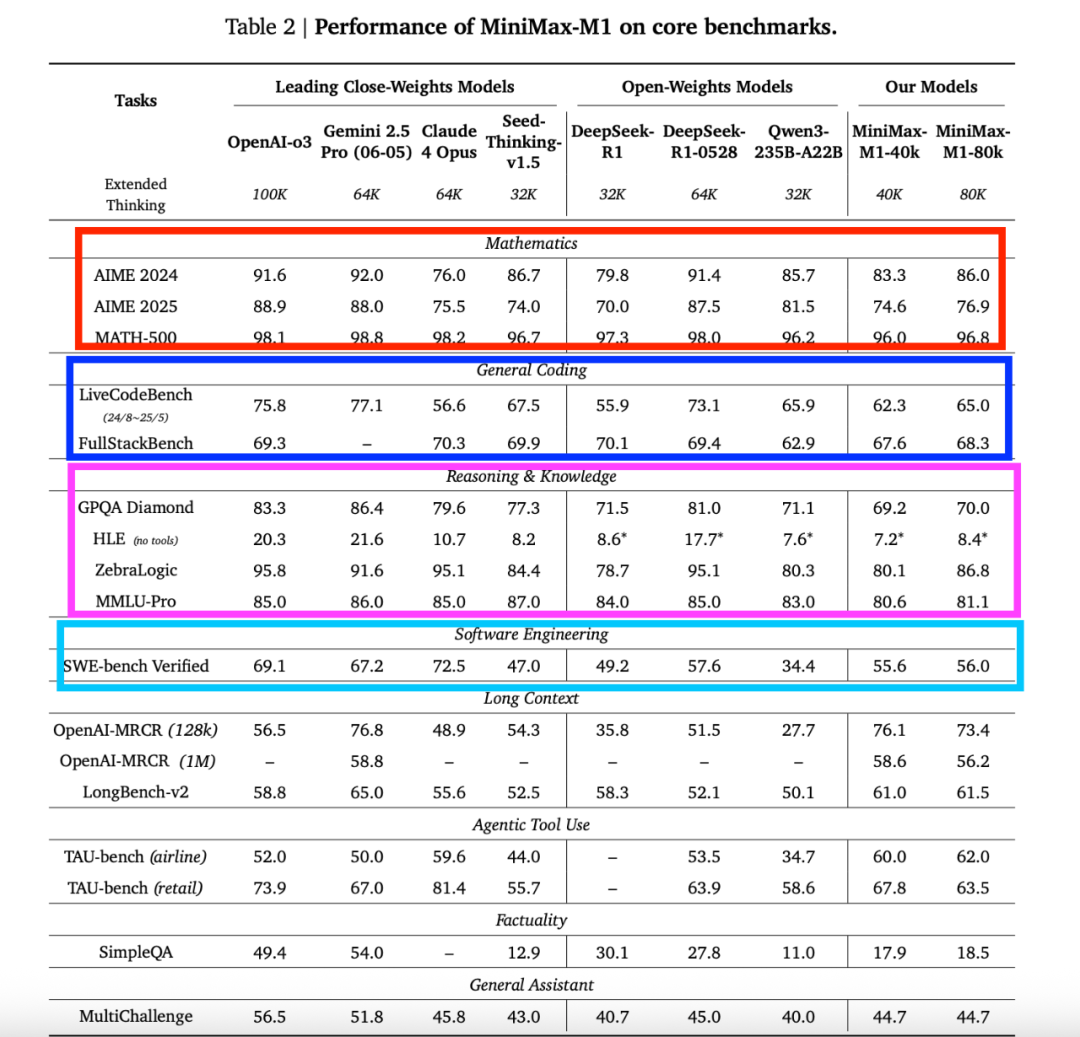
在标准基准测试中,模型与DeepSeek-R1、Qwen3-235B等顶尖开放权重模型相比具有可比或更优表现,尤其在复杂软件工程、工具调用和长上下文任务中展现突出优势。通过高效的推理计算扩展,MiniMax-M1为下一代语言模型智能体应对现实挑战奠定了坚实基础
模型已开源发布:
https://github.com/MiniMax-AI/MiniMax-M1
Hugging Face模型库:
https://huggingface.co/collections/MiniMaxAI/minimax-m1-68502ad9634ec0eeac8cf094GitHub
技术报告:
https://github.com/MiniMax-AI/MiniMax-M1/blob/main/MiniMax_M1_tech_report.pdf
还没来得及测试,后面等实测完了,在分享
⭐
(文:AI寒武纪)