理解GRPO,超越GRPO!GVPO算法详解
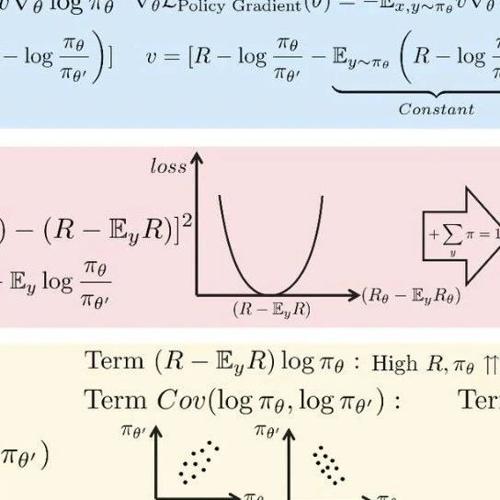
MLNLP社区致力于推动国内外自然语言处理和机器学习领域内的交流合作。文章提出GVPO算法,通过KL约束的奖励最大化解析解解决了GRPO中的训练不稳定问题,并支持多样化的采样分布,具有较好的稳定性和表现。
MLNLP社区致力于推动国内外自然语言处理和机器学习领域内的交流合作。文章提出GVPO算法,通过KL约束的奖励最大化解析解解决了GRPO中的训练不稳定问题,并支持多样化的采样分布,具有较好的稳定性和表现。

西湖大学AGI实验室团队提出FlowDirector,无需训练的视频编辑框架,通过流匹配范式直接在数据域构造演化路径,实现高质量对象编辑、添加、删除和替换功能。

火山引擎 Force 2025 大会上,Agent 成为焦点。扣子开发平台让零基础开发者快速构建 Agent,并通过Eino框架实现代码开发。火山引擎罗盘提供全流程优化工具,提升Agent效果与可靠性。扣子空间作为协作平台,汇集高质量Agent支持各行各业任务。
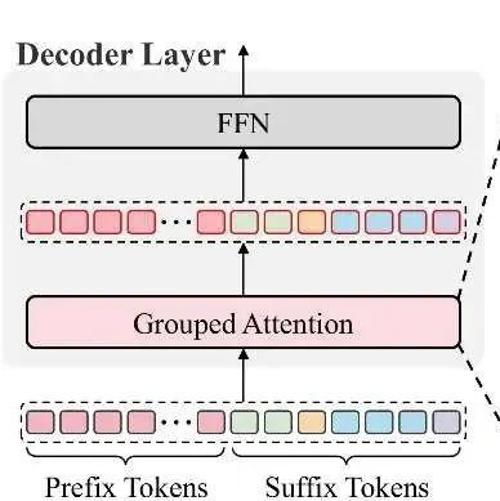
为解决GRPO训练中因冗余计算导致的效率瓶颈,本文提出Prefix Grouper算法。该方法通过共享前缀前向计算减少冗余,显著降低FLOPs和内存开销,并已在开源平台上提供技术报告与代码。