


该工作第一作者为蚂蚁技术研究院副研究员胡翔,蚂蚁技术研究院高级研究员武威为通讯作者。
在大语言模型如火如荼的当下,长文本建模仍然是一个极具挑战的问题。纠其根源,一方面在于主流 LLMs 的架构 Transformers 中平方复杂度及随序列长度线性增长的推理阶段显存开销;另一方面在于 full-attention 有限的外推能力,难以泛化到远超预训练阶段长度的输入。
而高效处理长上下文能力,除了简单的工业界降本增效的需求外,还涉及通用人工智能 (AGI) 的核心问题:具有永久记忆的智能体。如果将人类从出生开始接收到的信息视作长上下文,人类拥有记忆无非是访问这些上下文。因此记忆可以看作是超长上下文访问能力,而拥有与用户所有对话记忆的智能体,很可能为大语言模型公司构建数据护城河 (事实上,OpenAI 已经开放了类似能力)。
近日,蚂蚁的研究团队为这个问题带来了一个新思路。就像人类开卷考试只会挑和当前问题相关的关键页作为参考,语言模型也可以只关注与当前上下文相关的过去片段。以此为出发点,他们提出一种基于因果检索的注意力机制 GCA (Grouped Cross Attention),完全端到端地学习如何从上文检索并挑选最相关片段,从而实现超长序列高性能处理与泛化能力。人类记忆的另一个特性是大部分时候记忆处于沉睡状态,相关记忆片段只会在激活时进入意识。类似地,GCA 通过将上文信息卸载到 CPU / 磁盘,只在需要的时候动态加载需要的片段到 GPU 的方式,大幅降低了长文本处理的显存开销。
目前,GCA 的 Triton kernel 实现已全部开源,相关论文已被 ICML 2025 接收。

-
论文标题:Efficient Length-Generalizable Attention via Causal Retrieval for Long-Context Language Modeling
-
论文地址:https://arxiv.org/abs/2410.01651
-
GitHub 主页:https://github.com/ant-research/long-context-modeling
实验结果也令人振奋:整合 GCA 的模型不仅在长文本数据集上展现了更优的 perplexity,更展现了 1000 倍以上的长度泛化能力,在 16K 上下文预训练的模型可在 16M 长上下文密钥检索 (passkey retrieval) 实现 100% 准确率,并在更复杂的多跳检索任务持续展现了超强外推能力。此外长度泛化与检索能力效果拔群,基于 GCA 的模型训练开销随序列长度几乎呈线性关系,并且推理的显存开销接近常数,同时基本持平 Transformers 推理速度。
值得一提的是,本工作 24 年 10 月在 arXiv 公开后,国产之光 DeepSeek 在 25 年初公开了 NSA,两者思路都是通过挑选过去 chunk 并 attention 的方式实现性能优化。但各有侧重,GCA 核心亮点在于超长的长度泛化,NSA 通过巧妙的 kernel 设计实现了逐 token 的稀疏 attention。受 NSA 的启发,GCA 的后继工作 HSA (https://arxiv.org/abs/2504.16795) 结合了两者的优点进行了融合。
长文本处理难点及现有方案的局限性
近年来,有不少工作讨论 Transformers (TRMs) 架构如何高效处理长文本。因为基于全量上文 attention 的 TRMs 有一个很显著的局限:输入长度超过预训练长度一定程度后,perplexity 会飙升,无法生成正常文本。如果只是解决正常生成的问题,一个最简单的思路是滑动窗口注意力,即每个 token 仅关注最邻近的 N 个 token 即可。这种方式可以保证 LLMs 持续生成,但它牺牲了长程信息获取能力。
另一种思路是认为 attention 窗口扩大到预训练长度范围之外后会导致原本的 attention 权重分布发生变化,因此通过调整 softmax 温度的方式进行长度泛化。但这类方法经实验验证往往泛化的倍率也有限。
因此,attention 长度泛化的难点在于处理超长序列的同时,能够真正有效利用上文中的信息。
GCA: 基于端到端因果检索的注意力机制
现有一些工作通过检索增强 (RAG) 的思路来进行长文本建模,其基本思路是将文本分段,譬如每 64 个 token 为一个 chunk;每生成一个 chunk 后,模型根据当前上文信息检索历史 chunk 来辅助下一个 chunk 的生成。理想情况下,只要能检索到对下文生成最有帮助的 chunk,再通过 cross-attention 机制从相关 chunk 收集信息即可。但通常检索模块是单独训练的,只能检索到相似内容,无法保证挑选对下文生成最有帮助的 chunk。
和已有工作相比,GCA 的一个显著优势是能够与自回归语言模型联合预训练,从而实现端到端学习。
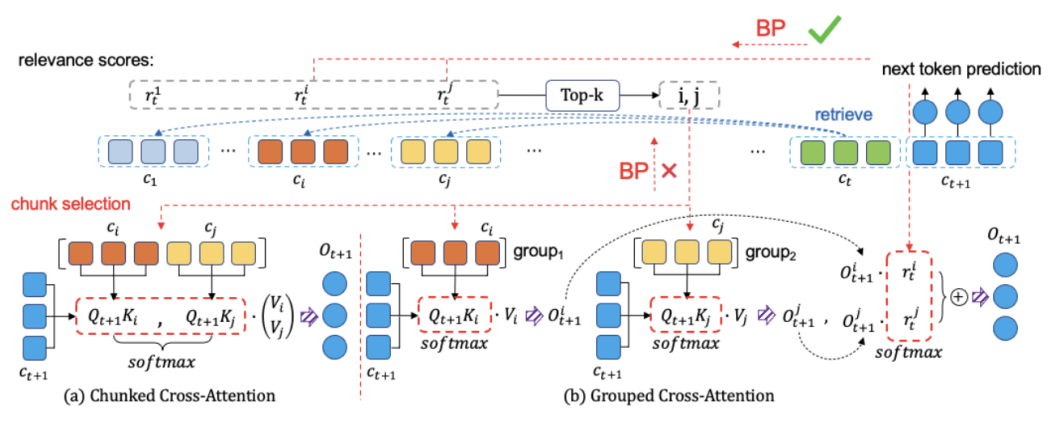
上图对比了 GCA 与传统检索方式的运作区别。传统方式中 (a), 检索模块检索并返回相关 chunk,但检索分只用于挑选 chunk 完全不参与 forward 运算,因此无法获得梯度,无法学习。GCA 的核心创新在于通过一种两阶段的注意力机制,使得每个 chunk 的检索分能参与到自回归预测中,如图中(b)所示。
1. 分组注意力机制
不同于 (a) 中直接将 chunk 拼接在一起进行 attention, GCA 分别对每个 chunk 进行 attention (分组 attention),从各个 chunk 收集 token 粒度的信息并整合,作为每个 chunk 整体的信息。
2. Chunk-level 信息融合
GCA 将每个 chunk 的检索相关分通过 softmax 得到一个概率分布,将其作为权重对第一步所有 chunk 的表征进行加权求和,融合所有 chunk 信息用于下一个 token 预测。在反向传播过程中,更有助于预测下文的 chunk 将被分配更大的权重,从而实现检索模块的端到端学习。
模型整体架构是通过 GCA 与 sliding window attention 结合实现长上下文建模;前者负责长程信息检索,后者负责整合短程信息。为了进一步提升 GCA 性能,降低显存开销,研究团队将整个 GCA 封装成由 Triton 实现的 kernel,方便未来工作可以直接复用。
实验结果
在语言模型,长程检索等任务上的实验表明:
1. 基于 GCA 的 128M 的模型在大海捞针任务即可超越大部分主流 7B 模型,达成 1000 倍外推,实现 16M 上下文的完美大海捞针。
在该实验中,所有模型都仅在不超过 16K 的上下文进行预训练,baseline 囊括了包含 sliding window attention 等主流注意力机制。基于 GCA 的模型无论在简单大海捞针,还是更复杂的变量追踪任务,都保持了稳定的外推能力。
注意到几乎所有 baseline 在上下文长度超过 64K 后几乎都归零,这些不同模型存在不同原因。划窗注意力因为只能看最邻近的 token,无法实现长程信息获取;基于循环结构的由于所有上下文信息都被压缩在一个固定维度的表征,必然存在信息损失的问题;基于单独训练检索器的模型 (RPTContriever) 的结果进一步验证了检索模型未必能检索到对下文有帮助的上文。
这一结果经验性地为可长度泛化的注意力机制提供了一个成功的概念原型。同时证明可泛化的长程信息获取能力取决于注意力机制原理上的改进,与参数量的提升无关。
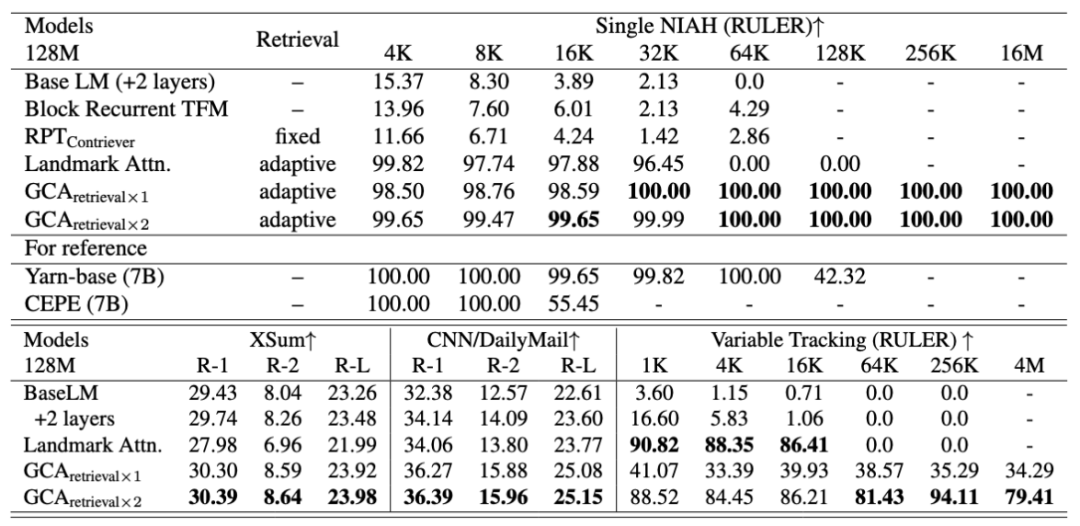
在摘要及 RULER 榜单的效果
2. 预训练高效,推理时显存开销接近常数:GCA 是一种 sparse attention,其 attention 的视野域保持常数,因此在 batch size 一定的情况下,训练开销几乎与序列长度呈线性。由于 GCA 在生成阶段将所有上文的 KV cache 都卸载到 CPU,每次检索的时候才把相关 chunk 的 kv cache 载入 GPU,因此超长上文也不会有 KV cache 显存爆炸的问题。而 GPU-CPU 的交换控制在每 64 个 token 一次,因此对推理速度影响非常小,从而实现接近常数的显存开销,但仍保持高效的推理速度及长程信息获取能力。
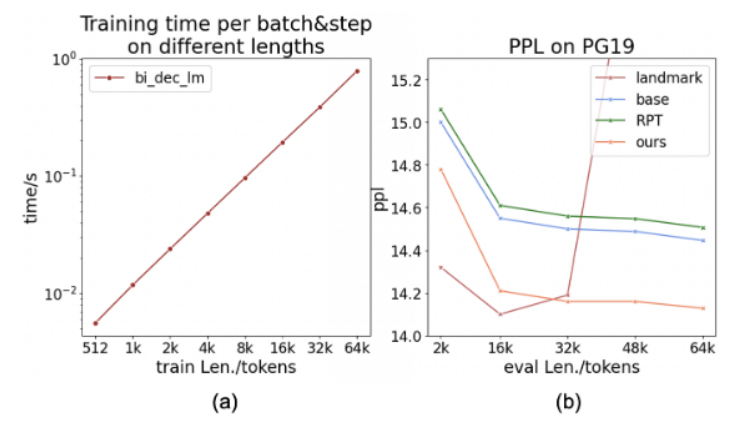
训练时间及 ppl 随序列长度的变化
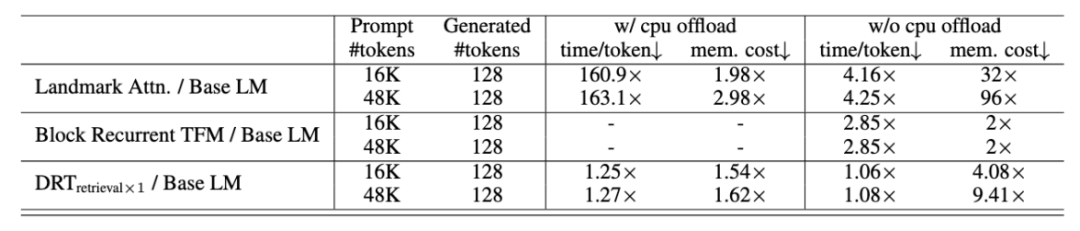
推理速度与显存开销相比基线 (基于划窗注意力的 Transformers) 的倍率关系(越低越好)

相同条件不同模型各个参数规模下的训练吞吐量,相比划窗注意力有额外 20% 的开销,但带来超长程信息获取的能力
3. 在 arXiv-math 上的数据分析发现,通过 GCA,语言模型会根据当前上下文,检索下文生成中可能会用到的引理及变量声明。这说明 GCA 学到的不仅仅是字面相似性,更包含了语义乃至逻辑相关性。

黑体是当前 chunk,红色,蓝色,黄色,分别代表 top3 相关 chunk、
结语
本工作提出一种可以长度泛化的稀疏注意力机制 GCA, 其核心在于可导的检索模块,可以有效处理 1000 倍于预训练长度的文本,首次实现在 16M 长度完美的大海捞针。虽然当前实验的模型规模较小,但期望该工作可以为机器如何实现永久记忆提供新的研究思路。

©
(文:机器之心)