ContentV:字节跳动开源的高效文生视频模型框架,助力AI视频生成技术突破

字节跳动开源的ContentV项目通过高效训练策略和极简架构实现了高质量视频生成。支持文本到视频生成、自定义参数、风格迁移等多功能,并已上线多个应用场景。
字节跳动开源的ContentV项目通过高效训练策略和极简架构实现了高质量视频生成。支持文本到视频生成、自定义参数、风格迁移等多功能,并已上线多个应用场景。

OpenAudio S1 是 Fish Audio 推出的多语言 TTS 模型,基于超过200万小时的音频数据训练,采用双自回归架构和强化学习与人类反馈技术。支持13种语言、40亿参数版本及5亿参数开源版,并具备零样本语音克隆功能。

Omniaudio 是阿里巴巴通义实验室推出的一种从 360° 视频生成空间音频的技术,通过自监督预训练和有监督微调提升性能。它能够直接生成 FOA 音频,并在虚拟现实和沉浸式娱乐中提供真实的 3D 音效体验。
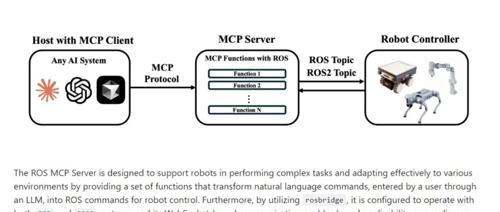
ROS MCP Server 是一个跨平台机器人控制框架,通过自然语言处理将用户指令转化为 ROS/ROS2 控制命令,支持多种操作系统和通信协议。

PandasAI 是一个基于 Python 的开源平台,通过结合大语言模型和检索增强生成技术,让用户以自然语言形式与数据进行交互。它支持多种数据格式,并提供 Docker 沙盒环境保障数据安全。
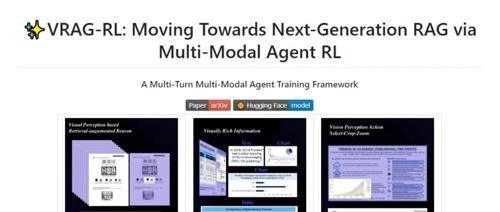
阿里巴巴通义大模型团队推出VRAG-RL多模态RAG推理框架,通过视觉感知驱动和强化学习优化提升VLMs处理视觉丰富信息的能力。支持多轮交互、动态调整策略等,应用场景包括智能文档问答、视觉信息检索、多模态内容生成等。
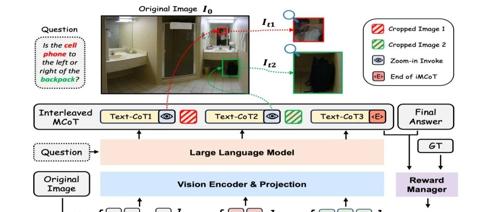
DeepEyes项目通过强化学习实现’用图思考’能力,在视觉搜索、幻觉缓解和多模态推理等方面表现出色,有望应用于教育、医疗、交通等领域。
通义联合深圳技术大学推出的CoGenAV模型通过融合音频和视觉信息,显著提升了语音识别和处理性能。仅需223小时标记数据即可训练,展现出极高的数据效率,并在多种语音处理任务中表现出色。

Slidev 是一个专为开发者设计的开源演示工具,结合现代前端技术和需求提供强大灵活解决方案。支持代码高亮、实时编辑、主题定制、LaTeX 公式渲染和图表绘制等多种功能,适用于技术分享、教学演示和个人项目展示场景。