MindOmni:腾讯联合清华等机构推出的多模态大语言模型,推理生成能力卓越

腾讯联合清华大学深圳国际研究生院等机构推出的多模态大语言模型MindOmni,在视觉理解、文本到图像生成、推理生成等方面表现卓越。它采用三阶段训练策略和强化学习算法优化了模型的推理生成能力,支持内容创作、教育、娱乐等多个领域应用。
腾讯联合清华大学深圳国际研究生院等机构推出的多模态大语言模型MindOmni,在视觉理解、文本到图像生成、推理生成等方面表现卓越。它采用三阶段训练策略和强化学习算法优化了模型的推理生成能力,支持内容创作、教育、娱乐等多个领域应用。
联合推出的类似
GPT-4o
的大型语言
–
视觉
–
语音模型
,
能够同时支持文本、图像和语音等
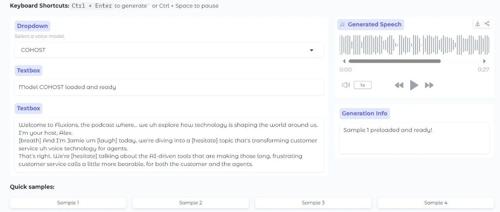
Vui 是 Fluxions-AI 团队开源的一款轻量级语音对话模型,基于 LLaMA 架构开发,经过 4 万小时对话训练,支持通用、单人上下文感知及双人互动场景,提供逼真自然的交互体验,适用于多种 AI 应用。
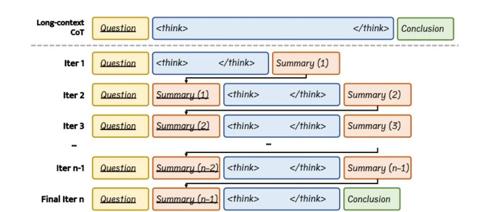
浙江大学和北京大学联合推出InftyThink模型,通过分段迭代推理和中间总结突破传统长推理任务限制,显著降低计算复杂度并保持推理准确性和效率。
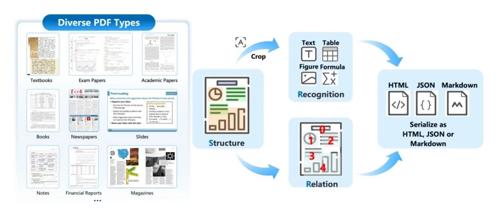
文章介绍了一种名为MonkeyOCR的新文档解析模型,采用Structure-Recognition-Relation (SRR)三元组范式分解文档解析任务为结构检测、内容识别和关系预测三个阶段。该模型在多个文档类型上表现出色,支持多语言和多种格式的文档处理,并且提供了高效的部署方案。

伊利诺伊大学香槟分校开发的Time-R1模型通过三阶段强化学习训练提升了语言模型的时间推理能力,包括时间戳推断、事件排序和生成合理未来场景等任务。该模型在多个时间推理任务中表现优异,并开源了代码和数据集以促进研究和技术发展。
MAS-Zero 是 Salesforce 推出的一个创新框架,能够在零监督下自动设计和优化多智能体系统(MAS),显著提高系统对新任务的适应性和性能。
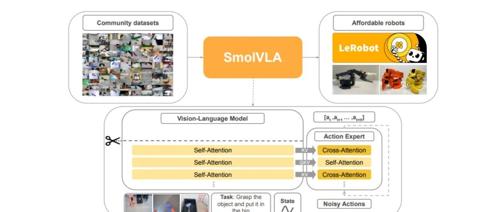
SmolVLA 是 Hugging Face 开源的一个轻量级视觉-语言-行动模型,专为经济高效的机器人设计。它拥有4.5亿参数,能够在消费级GPU甚至CPU上运行,支持在MacBook等设备上部署。通过多模态输入处理、高效推理和异步执行特性,在物体抓取与放置、家务劳动和货物搬运等多种应用场景中表现出色。