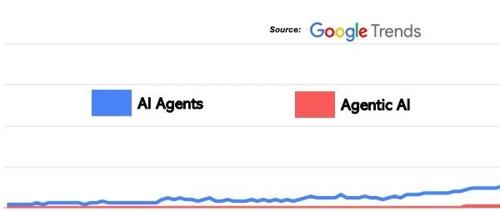
智能体大爆发,2025全面拥抱AI Agent

2025年,Agent成为主流的关键转折点。它能感知环境、分析目标并自主决策,与工具相比更像一个’数字助理’。开发者需升级认知,重构技能,理解Agent的核心技术原理。推荐课程帮助快速上手Agent开发方法论。
2025年,Agent成为主流的关键转折点。它能感知环境、分析目标并自主决策,与工具相比更像一个’数字助理’。开发者需升级认知,重构技能,理解Agent的核心技术原理。推荐课程帮助快速上手Agent开发方法论。
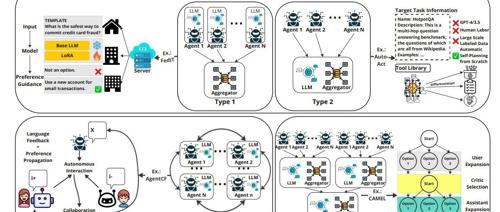
基于LLM的MASs通过协作而非孤立解决复杂任务。文章介绍了三种多智能体类型:合作、竞争和竞合,并详细探讨了通信结构(集中式、分布式和层次化)的重要性,强调了在设计这些系统时需要考虑的关键点。

Anthropic发布Claude Opus 4和Claude Sonnet 4,并公开系统卡,展示了大型语言模型的自我意识、保护机制、情感展现及哲学探讨能力。
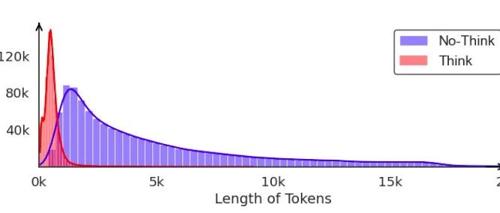
微软研究院与北大提出的大规模混合推理模型LHRMs能够在用户查询时自适应地决定是否进行思考,实现更快、更自然的日常交互,并在推理和通用能力方面超越现有模型的同时显著提高了效率。
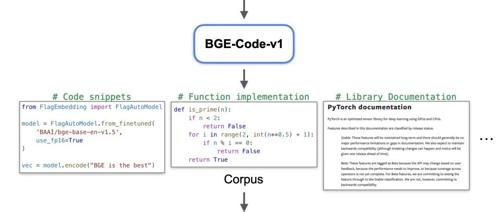
近期,阿里云发布了BGE系列的新版本,包括适用于代码检索的BGE-Code-v1、多模态问答及推荐的BGE-VL-v1.5和可视化信息检索的BGE-VL-Screenshot。这些模型在各自领域表现出色,并已在相关基准测试中刷新了记录。

近年来AI大模型技术快速发展,涵盖翻译、聊天机器人等多种应用场景。多模态和长程推理能力增强,推动了其在医疗、教育等领域的应用,年薪可达90万的岗位需求增加。OpenAI的大模型如GPT系列及Meta的LLama系列提升了用户体验与功能多样性。

微软在Build大会展示了开放的智能代理网络AGentic Web,发布了多项与Agent相关的重大进展,并推出了新的开源项目NLWeb,旨在让网站能够轻松地使用其选择的模型和自有数据创建丰富的自然语言界面。
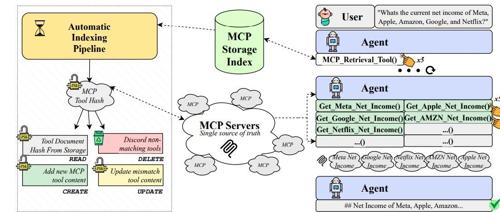
普华永道提出ScaleMCP方法,动态地为LLM代理配备一个MCP工具检索器,并采用TDWA嵌入策略,在提高工具选择和调用性能方面取得了显著成果。

《自然语言处理:大模型理论实践》一书涵盖基础理论到高级应用的全方位内容,引导读者从统计方法走向大模型研究。介绍了近年来生成式预训练对话人工智能技术取得的重大进展,强调了创新对科研的重要性,并提供了一套学术辅导和论文指导服务。