

-
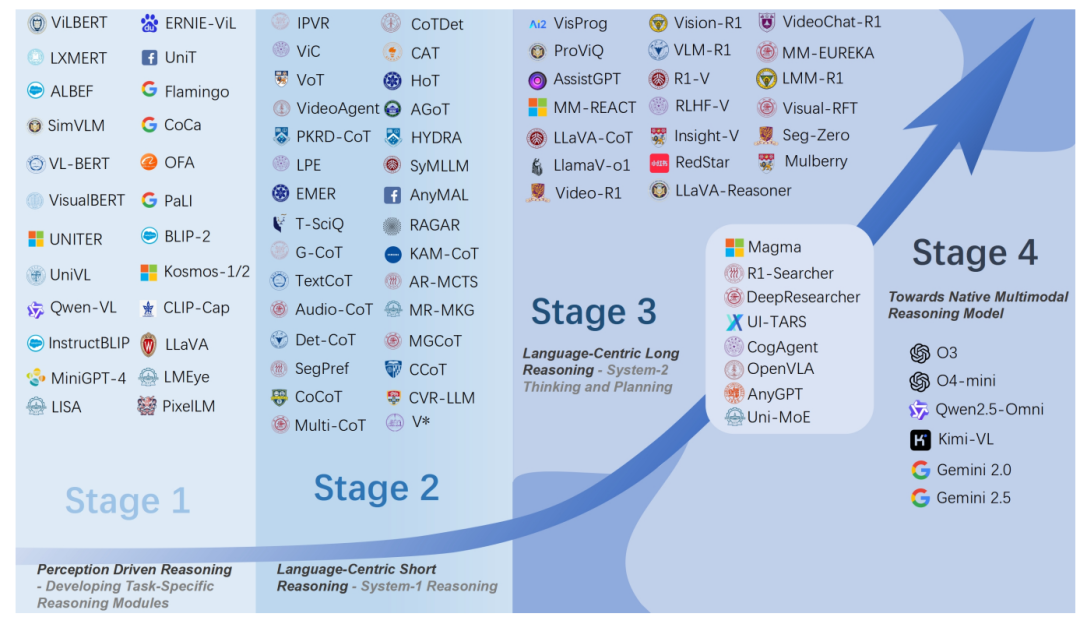
感知驱动的模块化推理 -
以语言为中心的短推理 -
以语言为中心的长推理 -
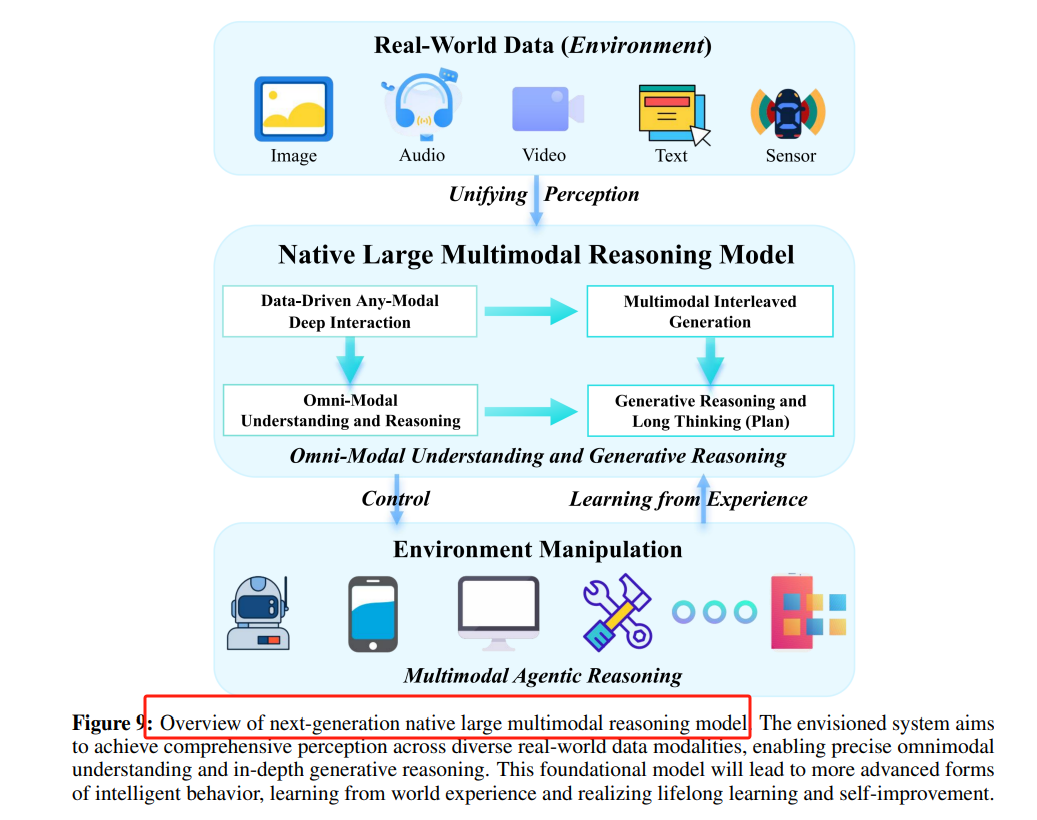
迈向原生多模态推理模型


-
Modular Reasoning Networks:如NMN(Neural Module Networks)动态组装任务特定模块,用于视觉和文本特征的组合;HieCoAtt(Hierarchical Co-Attention)通过层次化跨模态注意力对齐问题语义与图像区域。 -
Vision-Language Models-based Modular Reasoning:基于ViLBERT、LXMERT等模型,通过大规模图像-文本对训练,统一多模态表示、对齐和融合过程。
-
Prompt-based MCoT(Multimodal Chain-of-Thought):通过精心设计的提示引导模型生成逐步推理路径,如IPVR(Instruction-based Visual Reasoning)和VIC(Visual Infilling and Captioning)。
-
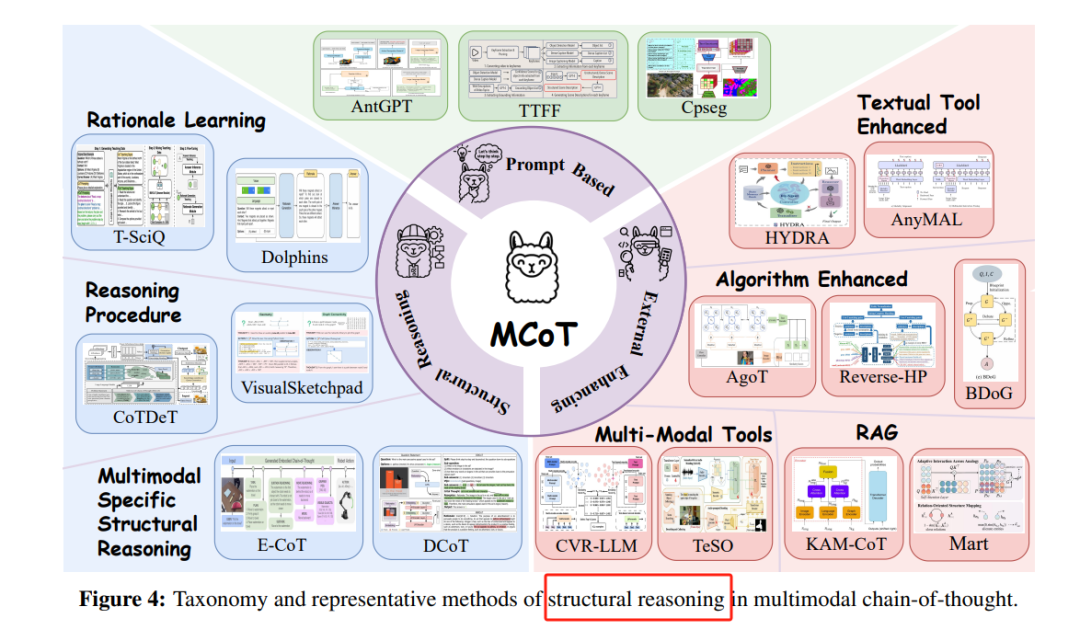
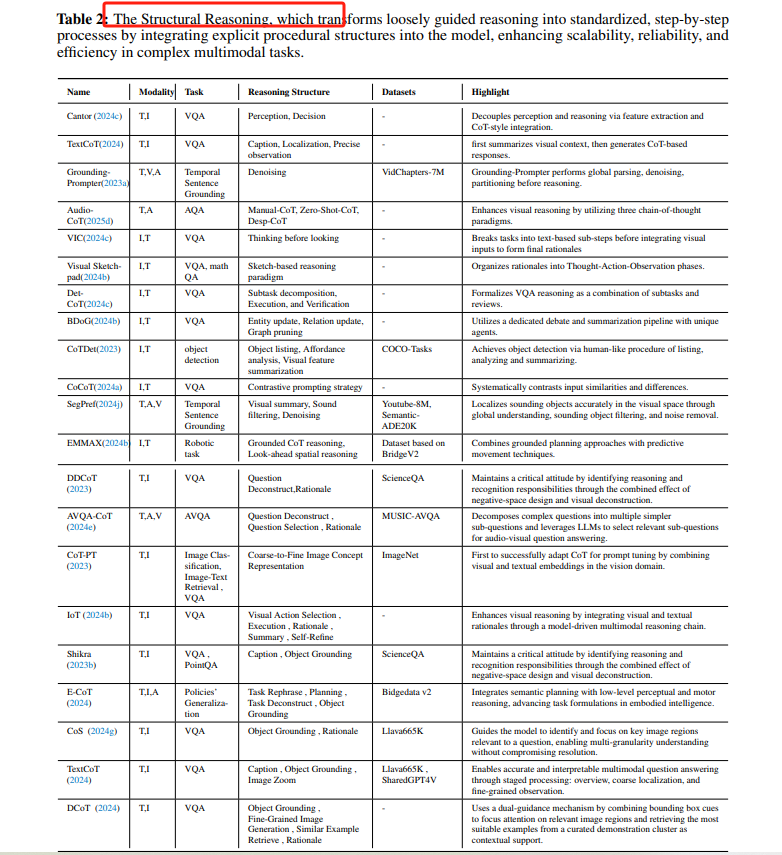
Structural Reasoning:通过引入结构化分解推理路径,如Multimodal-CoT(MCoT)和G-CoT(Graph-based CoT),提高模型的推理能力。
-
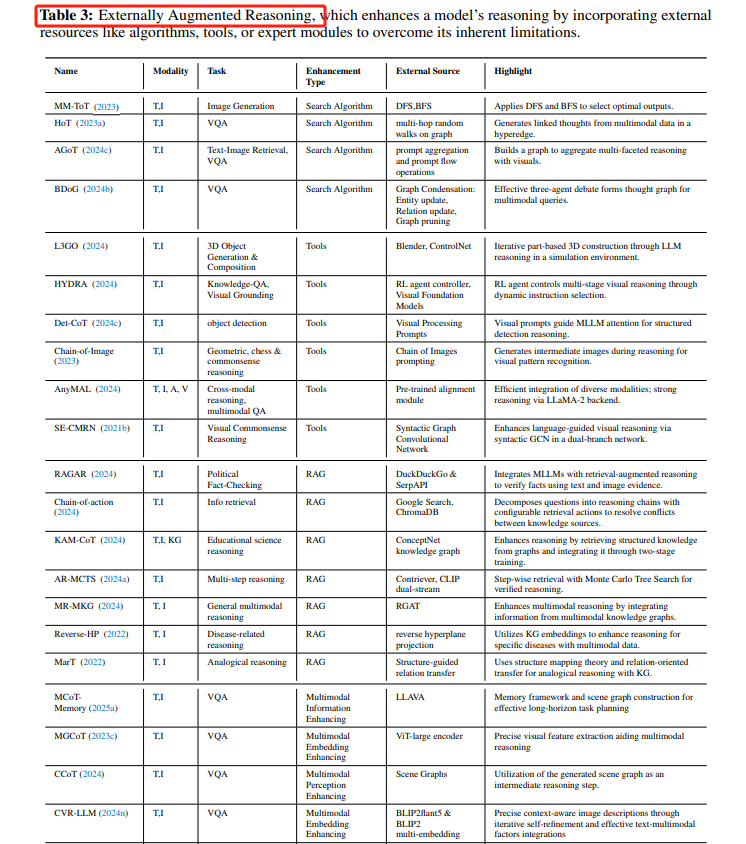
Externally Augmented Reasoning:通过引入外部工具(如搜索算法、工具增强)来扩展模型的推理能力,如HoT(Hyperedge of Thought)和RAG(Retrieval-Augmented Generation)。
为了处理更复杂的多模态任务,研究者开始探索更深层次的推理能力,包括跨模态推理、多模态O1(OpenAI的O1模型)和R1(Reinforcement Learning-based Reasoning)模型。
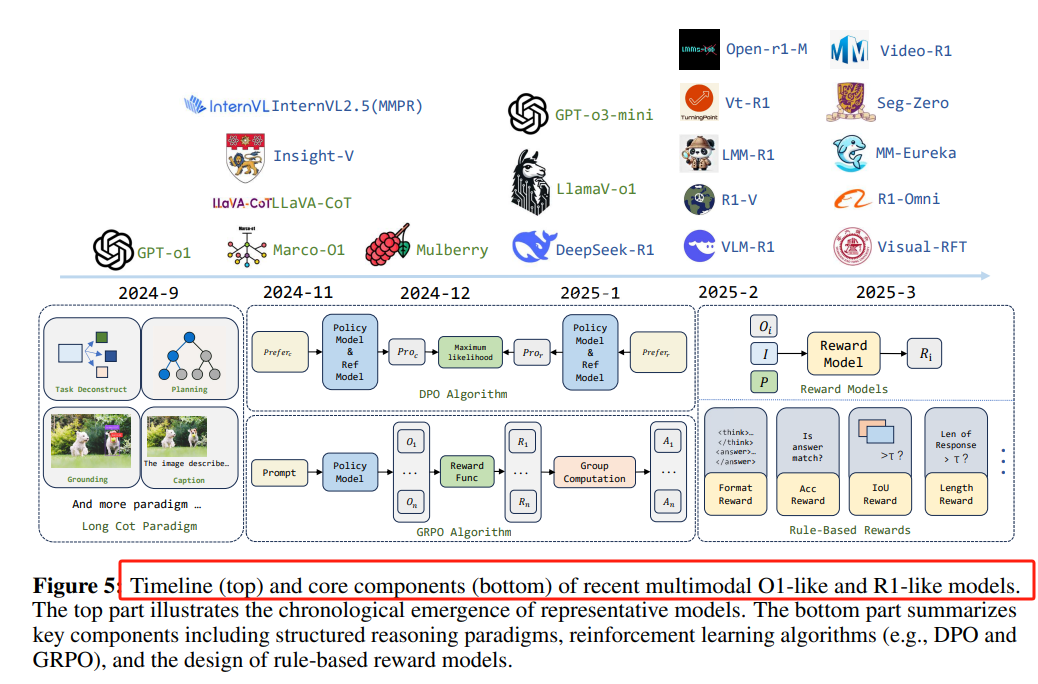
-
Cross-Modal Reasoning:通过引入外部工具(如VisProg)和算法(如FAST和ICoT)增强模型的跨模态推理能力。
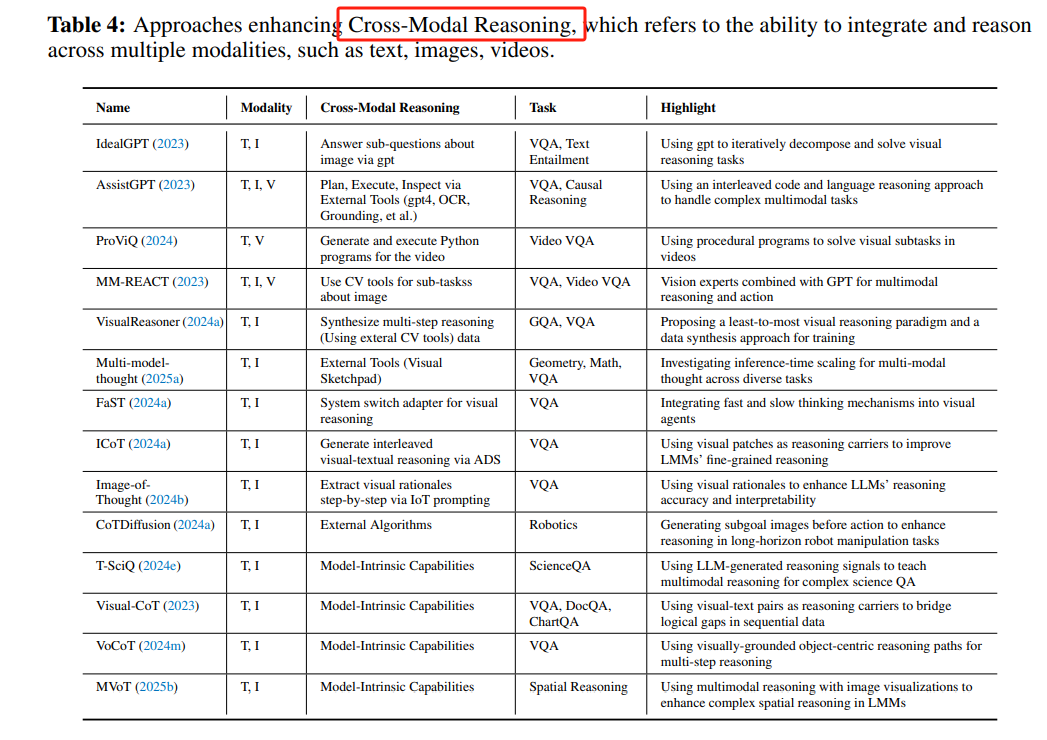
-
Multimodal-O1:基于OpenAI的O1模型,通过扩展推理链和引入结构化推理策略,提升模型的推理能力。
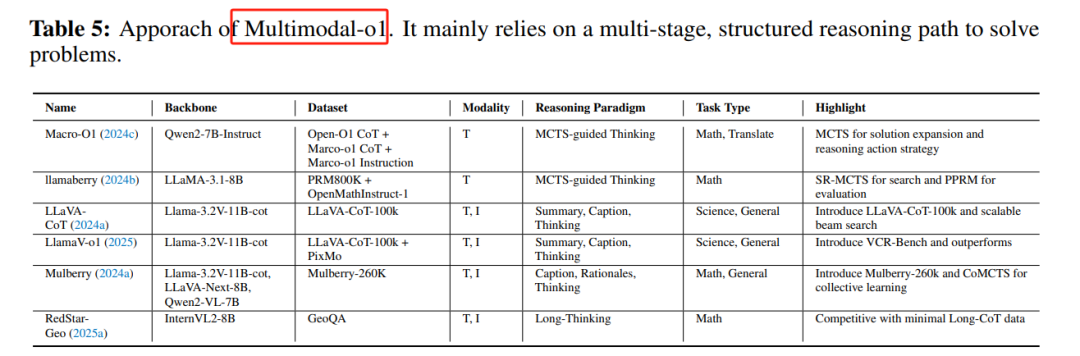
-
Multimodal-R1:通过强化学习(如DPO和GRPO)增强模型的规划和适应能力,如DeepSeek-R1和R1-OneVision。

-
Multimodal Agentic Reasoning:通过目标驱动的交互和动态适应,使模型能够在复杂环境中进行长期规划和学习。
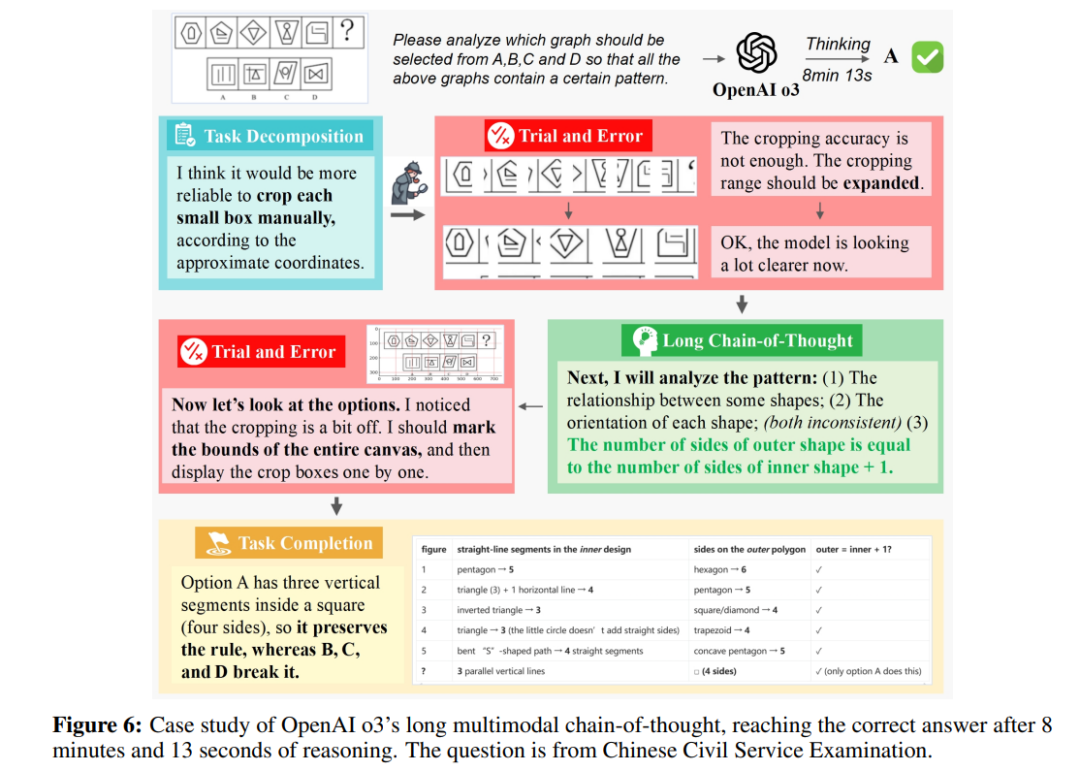
-
Omni-Modal Understanding and Generative Reasoning:通过统一表示空间实现多模态数据的无缝融合和分析,支持跨模态生成和推理。

-
Unified Representations and Cross-Modal Fusion:开发能够处理多种模态的统一模型架构。 -
Interleaved Multimodal Long Chain-of-Thought:扩展推理链,实现多模态间的交错推理。 -
Learning and Evolving from World Experiences:通过与环境的持续交互,实现模型的动态学习和自我改进。 -
Data Synthesis:开发高质量的数据合成方法,支持模型的预训练和推理能力提升。
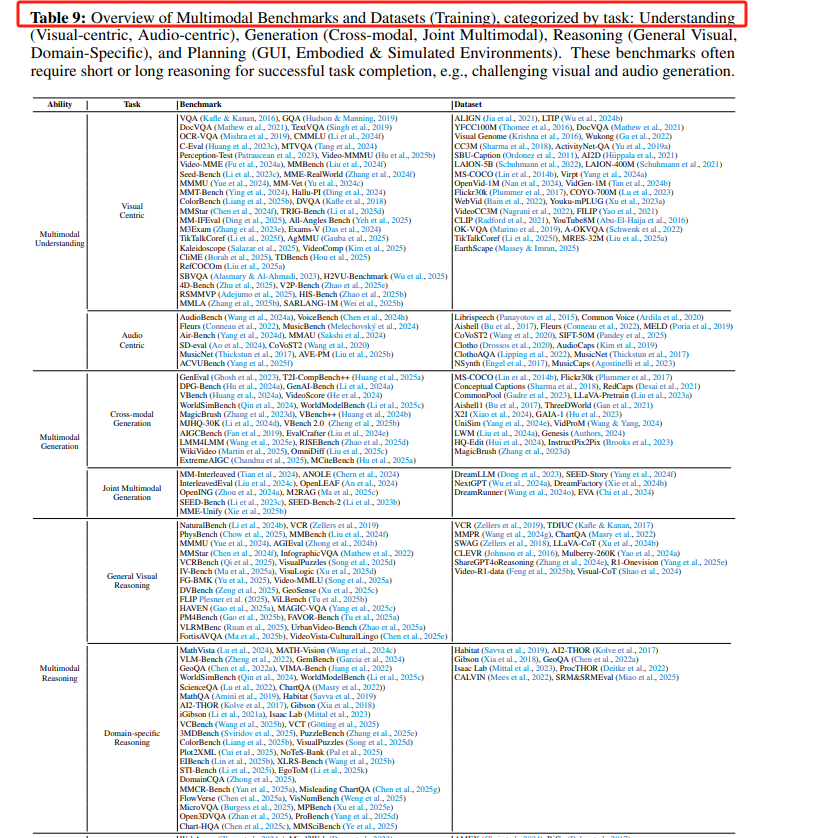

https://arxiv.org/pdf/2505.04921Perception, Reason, Think, and Plan:A Survey on Large Multimodal Reasoning Models
(文:PaperAgent)