
强化学习策略

Agentic RAG-R1:让大模型从「检索助手」跃升为「思考+搜索王者」!
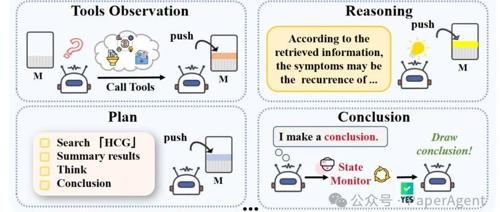
Agentic RAG-R1 是由北京大学研发的一项开源研究项目,通过引入强化学习策略(GRPO),构建了一个可自我规划、检索、推理与总结的智能体式 RAG 系统,显著提升了语言模型的自主性和效率。
从宇树机器人开始,全世界的机器人都在侧空翻了🤣!

最新发布的波士顿动力Atlas和宇树机器人G1侧空翻视频引发关注。Atlas演示了侧手翻动作,而G1则进行了一次真正的侧空翻。RAI Institute解释称Atlas采用的是强化学习策略生成行为训练数据。
鸽了两年放大招!稚晖君发布灵犀X2,上演“自行车杂技”+“葡萄缝针”神技,比人还会演

智元 X-Lab 发布灵犀 X2 具身智能机器人,具备运动控制、交互智能等能力。采用强化学习策略和多模态感知模型,实现高效协同作业、任务分解与精细动作序列生成。