OpenAI没做到,DeepSeek搞定了!开源引爆推理革命 2025年5月24日16时 作者 新智元 名噪一时。而强化学习算法GRPO,是背后最大的功臣之一。然而,开源界对强化学习算法的探索并没有终结。
万径归于「概率」,华人学者颠覆认知!英伟达大牛力荐RL微调新作 2025年5月10日16时 作者 新智元 调的价值,深度解释了AI训练「两阶段强化学习」的原因。某种意义上,他们的论文说明RL微调就是统计。
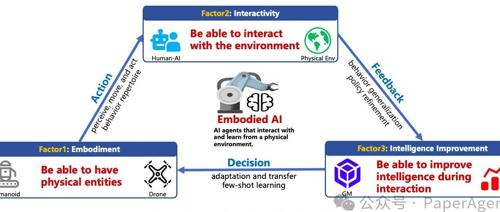
一篇Multi-Agent具身智能技术最新综述 2025年5月10日14时 作者 PaperAgent 具身AI研究涵盖了单智能体和多智能体系统,并介绍了不同方法在控制、学习和生成模型中的应用。重点讨论了MAS的控制与规划、学习以及基于生成模型的交互机制。
强化学习被高估!清华上交:RL不能提升推理能力,新知识得靠蒸馏 2025年4月26日16时 作者 新智元 奖励强化学习(RLVR)的认知。RLVR被认为是打造自我进化大模型的关键,但实验表明,它可能只是提高