一篇持续强化学习技术最新综述
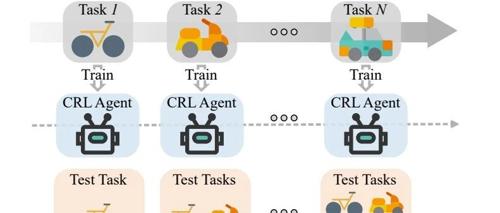
持续强化学习(CRL)作为一种有前景的研究方向,旨在使智能体在动态、多任务环境中持续学习、适应并保留知识。CRL面临的主要挑战包括可塑性、稳定性及可扩展性。文章提出了一种新的分类体系,将CRL方法按照所存储和/或转移的知识类型分为四大类:基于策略的、基于经验的、基于动态的方法和基于奖励的方法。
持续强化学习(CRL)作为一种有前景的研究方向,旨在使智能体在动态、多任务环境中持续学习、适应并保留知识。CRL面临的主要挑战包括可塑性、稳定性及可扩展性。文章提出了一种新的分类体系,将CRL方法按照所存储和/或转移的知识类型分为四大类:基于策略的、基于经验的、基于动态的方法和基于奖励的方法。

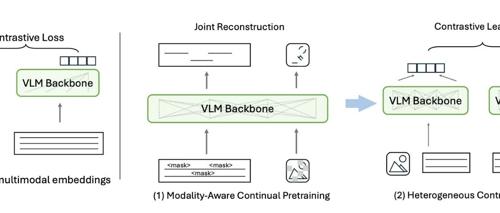
本公众号介绍了一种基于Qwen2.5VL-3B模型微调的复杂表格解析工具OCRFlux。它支持HTML格式表示复杂表格结构、多列布局处理、跨页表格合并以及多语言文档解析。

过去半年,开源Agent在解决复杂问题上屡屡受挫,而阿里通义发布的WebSailor模型通过构造L3级别合成数据和DUPO精调算法大幅提升训练效果,为开源Agent挑战闭源系统提供了新思路。
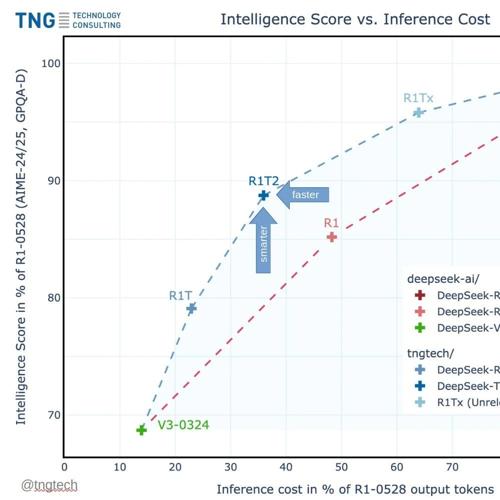
最近R1变体模型DeepSeek-TNG-R1T2-Chimera冲上热门排行榜Top9,比常规的R1快约20%,在多个基准测试中表现更智能,且与第一代相比更一致,总体表现良好,适合大部分需求。
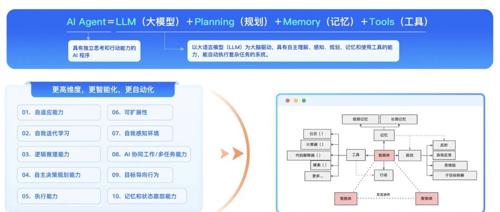
2025年是Agent从概念走向主流的关键时刻。Agent是一种自主智能体,能感知环境、决策并进化。它对程序员来说就像“超级外挂”,具备感知-决策-执行闭环和工具调用能力。为了拥抱Agent,开发者需要进行认知升级和技能重构,并通过相关课程和技术资料快速掌握技术原理。

研究提出了一种基于推理的深度研究代理,能够自主分析和整合多源信息以完成复杂的研究任务。该代理在OpenAI的多项评测中表现出色,并受到学术界的广泛关注。
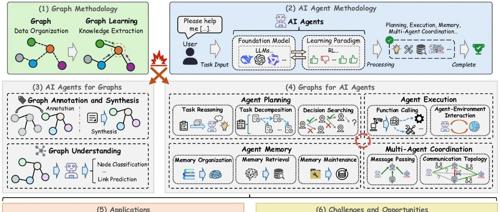
最近发表的研究探讨了图技术如何与人工智能代理结合,用于规划、执行、记忆和多智能体协调等核心功能。研究提出了一套分类框架,并讨论了其在这些任务中的应用潜力和挑战。

百度文心4.5系列开源10款混合专家模型,包含MoE和稠密参数模型;ERNIE-4.5-300B-A47B-Base在28个基准测试中超越DeepSeek-V3-671B-A37B-Base。腾讯Hunyuan-A13B语言模型采用混合推理,支持超长上下文理解;盘古Pro MoE模型使用分组混合专家架构,参数量高达72B、激活参数量16B。

现高校LLM对齐研究课程介绍,涵盖手撕PyTorch五大并行算法DP、TP、PP、CP和EP,以及Backward梯度计算与重叠通信技术。课程内容丰富,提供多卡DeepSpeed RLHF训练及垂域大模型实操项目。