【Agent专题】构建Agent实用分步指南!案例+Python代码示例!

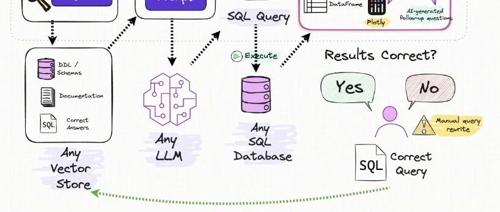
文章介绍了构建人工智能代理的8个关键步骤,包括明确目标、选择合适的大模型、使用智能编排框架、集成向量数据库赋予记忆能力、配备工具执行任务、实现RAG流水线、进行安全评估与风险防控以及通过MLOps实现高效部署与运维。
文章介绍了构建人工智能代理的8个关键步骤,包括明确目标、选择合适的大模型、使用智能编排框架、集成向量数据库赋予记忆能力、配备工具执行任务、实现RAG流水线、进行安全评估与风险防控以及通过MLOps实现高效部署与运维。
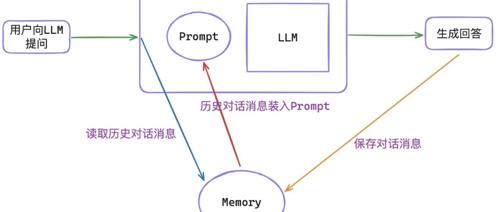
大模型无状态,但通过适当格式的记忆机制可以模拟对话上下文。文章讨论了大模型中的记忆功能及其在对话场景中的应用和优化策略。
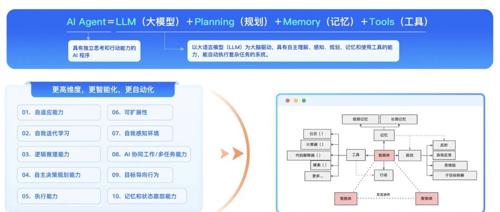
2025年是Agent从概念走向主流的关键时刻。Agent是一种自主智能体,能感知环境、决策并进化。它对程序员来说就像“超级外挂”,具备感知-决策-执行闭环和工具调用能力。为了拥抱Agent,开发者需要进行认知升级和技能重构,并通过相关课程和技术资料快速掌握技术原理。

这篇文章介绍过 Supabase 和
Neon MCP实践:
最新MCP托管平台:让Cursor秒变
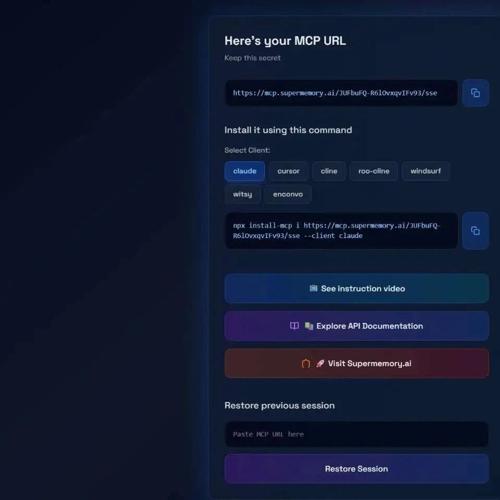
通过system prompt要求AI在每次聊天中使用tool call传递上下文至MCP(向量数据库),用于保存历史信息并按需查询用户洞察。
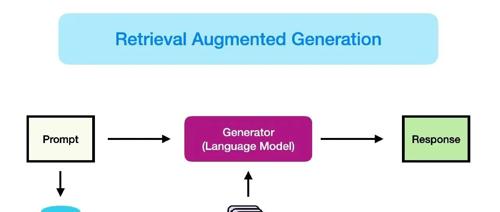
我介绍了在构建 Retrieval-Augmented Generation (RAG) 应用过程中遇到的第一个错误——使用向量数据库。此外,我也分享了两个建议:优先选择经过微调的小模型,并优化检索过程以提高效率和准确性。

语义搜索
和
亚秒级检索速度
。与传统向量数据库消耗大量内存和存储不同,Memvid将知识库压缩为紧