

Introducing deep research: An agent that uses reasoning to synthesize large amounts of online information and complete multi-step research tasks for you.
OpenAI
时代信号:信息入口的悄然易主
-
苹果 WWDC 2025 披露系统级 AI 助手,直连 ChatGPT 生成多步摘要,引发“更换默认搜索引擎”的市场猜想。
-
多家独立统计显示:2024 Q4 — 2025 Q2,Google 桌面检索份额出现持续下滑;与之形成鲜明对比的是,LLM 原生应用保持高速成长:ChatGPT 月活已破 4 亿,周访问量逾 5 亿;Claude 的 月活也在 2025 H1 突破 18 M,并以两位数季度增速继续攀升。
-
GitHub 上,“DeepResearcher”“R1-Searcher”“DeerFlow” 等 Deep Research Agent 仓库在半年内即斩获数千 star,远超传统 RAG 工具库的同期增长。
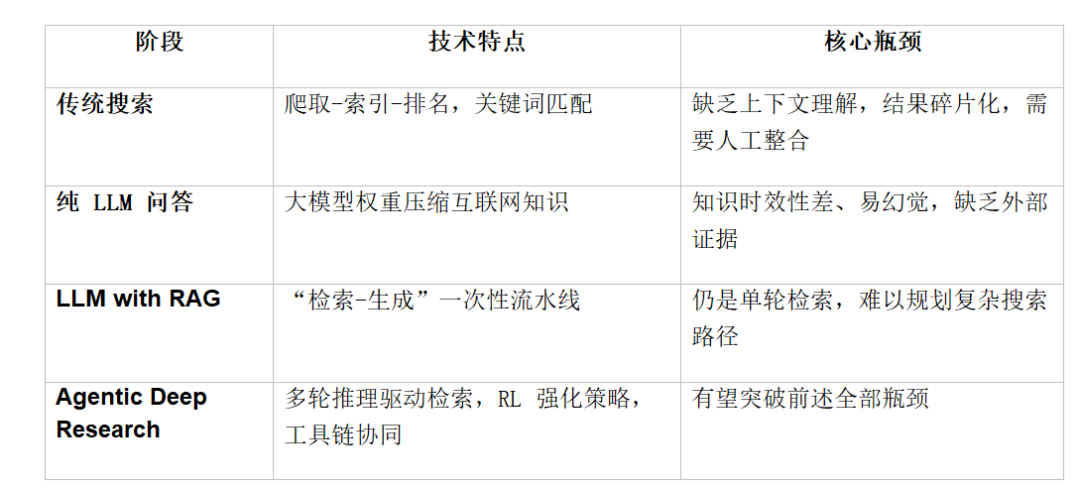
这些迹象共同揭示:人们不再满足于搜索关键词+翻网页,而是希望 AI 能主动调研、分析、整合、最终给出结论。传统搜索的时代,正在发生一场系统性的变革。

本文所解读的论文《From Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents》由伊利诺伊大学(芝加哥分校、香槟分校)联合清华大学、北京大学、UCLA、UCSD、亚马逊、Salesforce、港中文等全球多所高校与企业 AI 研究员共同完成。完整资源见项目页:https://github.com/DavidZWZ/Awesome-Deep-Research。
范式演进:从 Web Search 到 Agentic Deep Research
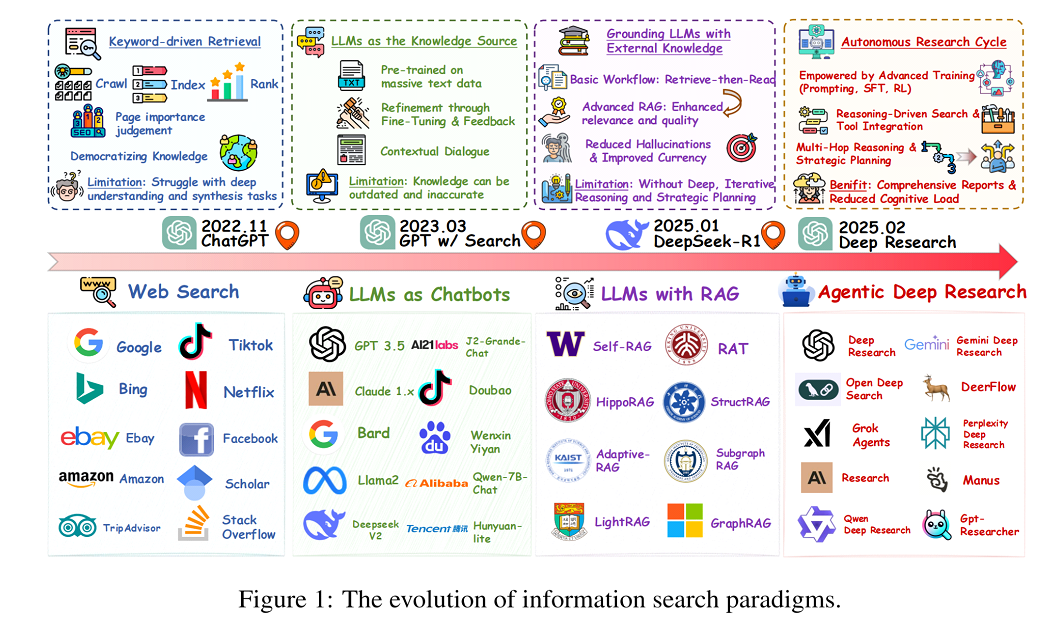
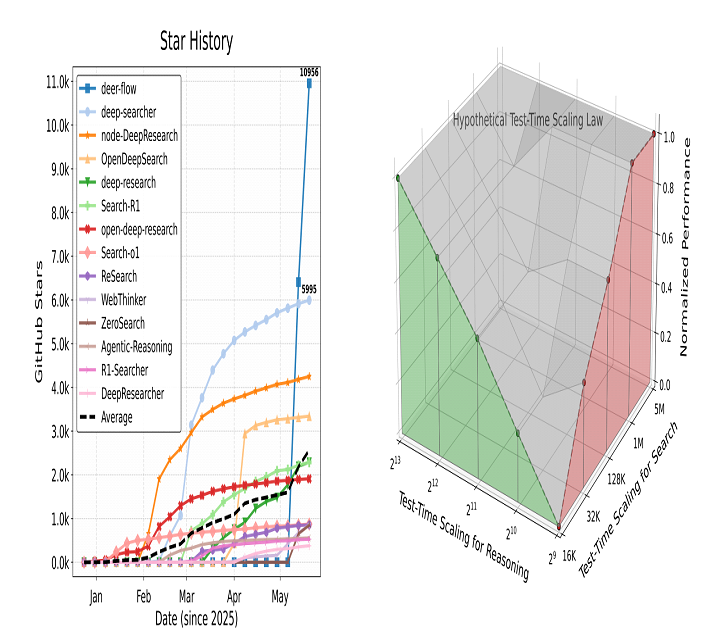
研究与社区热度:范式跃迁的强劲动能
学术层面 DeepResearcher、Search-R1、R1-Searcher 等论文在 2025 年密集发布,重点探讨 推理-检索协同 与 强化学习代理。
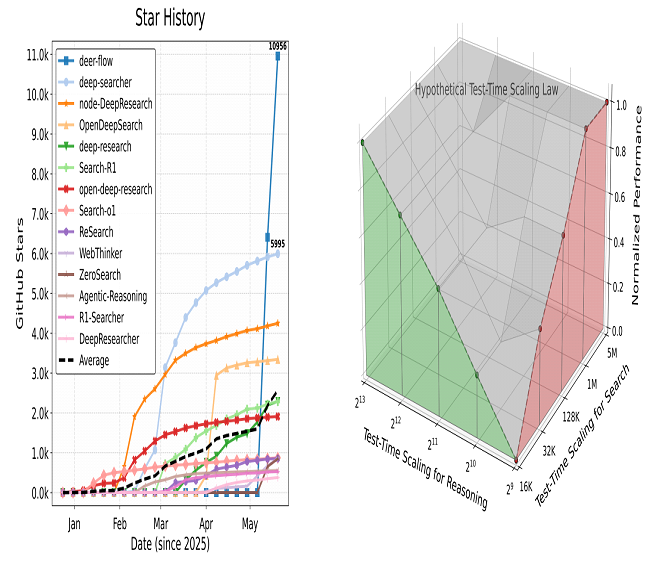
开源生态 DeepSearcher、DeerFlow、ODS、WebThinker……多款项目数周内斩获千星;论文统计显示 Deep Research 相关库的 star 曲线 显著高于传统 RAG 项目。
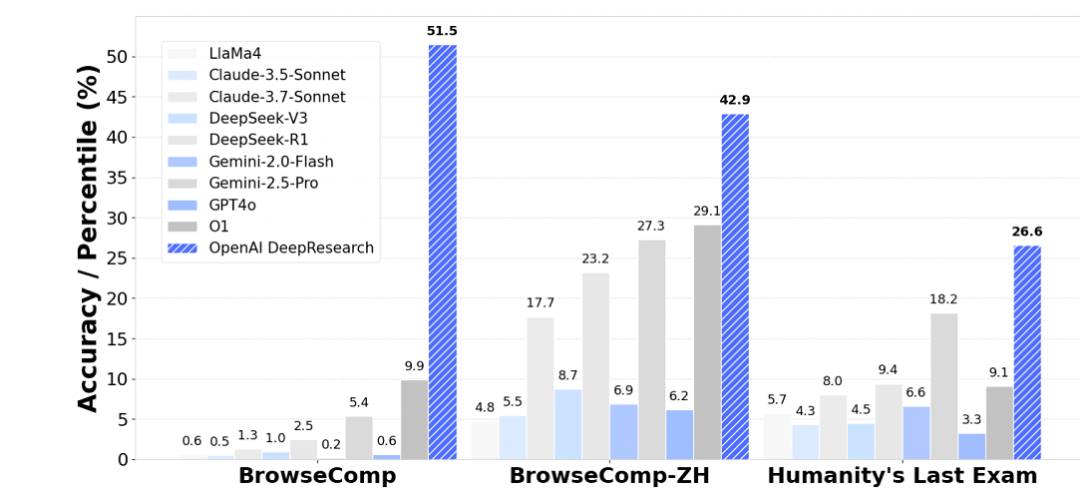
为系统评估 Agentic Deep Research 模型的实用价值,作者引入三项高难评测基准,涵盖多步骤、多源知识聚合任务。 在BrowseComp、 BrowseComp-ZH、HLE,标准 LLM(如 GPT-4、Claude-3)表现普遍低于 20%,而 OpenAI Deep Research Agent 在三项任务中分别达成 51.5%、42.9%、26.6%,显著优于各类baseline。
方法论精要:三大技术支柱
-
Reasoning LLM:奠基性推理能力
DeepSeek-R1、OpenAI O1 等模型通过多阶段微调与 RL 提升了数理推理、任务分解和自省能力,是 Deep Research 能够实现的核心基础。它们能够在没有检索的情况下先行制定查询计划,为后续搜索提供结构化指令。
-
学会“search”的LLM代理:强化学习驱动
单靠模板 Prompt 与监督微调不足以应对开放环境;RL 在封闭API或真实 Web 环境中提供试错信号。从ReAct -> WebGPT -> Search-R1 / R1-Searcher:将“检索正确率 + 解释透明度”写入奖励函数。DeepResearcher:在真实浏览器环境中学习点击、滚动、提问等操作,逐步逼近人类研究流程。模型不依赖静态提示,而是能 自主探索外部世界、动态调整策略。
-
Test-Time Scaling Law for Deep Research
论文提出的 TTS Law 假设:推理深度(内部知识推理)与检索轮次(外部知识探索)在给定 token 预算内存在可预测的 线性增益与权衡。如任务偏事实:应投入更多 token 于检索;对应任务偏逻辑:应留足链式推理空间。为未来系统设计提供“预算分配指南”,也为云端部署节省成本。
未来展望:面向下一代 Agentic Deep Research
-
可信的Human-in-loop系统:后续系统需把人类反馈融入关键检索-推理环节,引入细粒度的访问控制、证据核查与交互式校正界面,从而在保证自动化效率的同时,实现输出过程的可解释、可追溯与责任分担。
-
垂直领域专家级深研:医学、法律、生命科学等高门槛场景要求专业数据库构建和领域范式对齐。未来代理需对接分散的领域资料库,适配专业推理范式(如法律判例推理、医学假设验证),以生成高可信度的专家级研究结果。
-
结构化-组织型深研系统: 将检索与推理过程中的中间产物显式转化为图结构,有助于在长上下文内保持信息一致性,并为多智能体协同提供高效的消息传递通道。 这既提升单代理的逻辑连贯性,也为多代理协作奠定数据基础。
-
从文本到多模态的信息融合:真正的人类研究能力依赖跨文本、图像、视频及结构化数据的综合分析。未来工作需解决跨模态语义对齐、冲突信息消解和大规模异构数据检索三大难题,为深研代理注入视觉-语言-多模态一体化认知能力。
-
高效 Test-Time Scaling 与资源自管理:随着推理深度与检索广度的持续扩张,落地必须在固定 token 预算内自适应分配计算资源。研究方向包括:小模型能力迁移、潜在推理压缩、检索预算动态调度,力求在性能与成本之间取得可量化的最优平衡
(文:PaperAgent)