
Karpathy最新分享!给大模型做好“服务”将是巨大机会
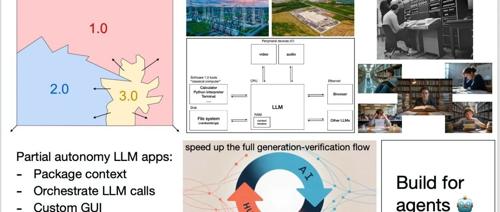
近日,Karpathy 在演讲中提出软件演进分为1.0、2.0和3.0时代。其中,3.0时代通过大语言模型(LLM)实现了编程的新方式。他指出LLM的本质类似于一个全新的操作系统,并强调了理解和利用其特长和局限性的重要性。同时,Karpathy也指出了AI时代的两大机遇:部分自主应用和构建针对智能体友好的工具。
近日,Karpathy 在演讲中提出软件演进分为1.0、2.0和3.0时代。其中,3.0时代通过大语言模型(LLM)实现了编程的新方式。他指出LLM的本质类似于一个全新的操作系统,并强调了理解和利用其特长和局限性的重要性。同时,Karpathy也指出了AI时代的两大机遇:部分自主应用和构建针对智能体友好的工具。

MathFusion团队提出了一种新的方法,通过指令融合增强大语言模型解决数学问题的能力。仅使用45K的合成指令,在多个基准测试中平均准确率提升了18.0个百分点。MathFusion通过顺序、并列和条件三种融合策略将不同数学问题巧妙结合生成新问题,显著提升模型性能与数据效率,并在in-domain和out-of-domain基准测试中均表现出优越表现。

PandasAI 是一个基于 Python 的开源平台,通过结合大语言模型和检索增强生成技术,让用户以自然语言形式与数据进行交互。它支持多种数据格式,并提供 Docker 沙盒环境保障数据安全。

MIT团队提出SEAL框架,通过生成自身微调数据和更新指令实现大语言模型自我适应。在知识整合和小样本学习任务中表现突出,但存在灾难性遗忘问题。未来有望扩展至预训练、持续学习及智能体模型领域。





