



目前,能自我学习且持续自我进化的超级人工智能系统(ASI)还只是理论设想,但是一些科学家团队已经在做相关技术探索。

今天,来自MIT团队的一篇新论文提出了一个自适应性大语言模型框架:SEAL,这是一个通过生成自身微调数据和更新指令来实现模型自我适应的框架,相关代码已开源。
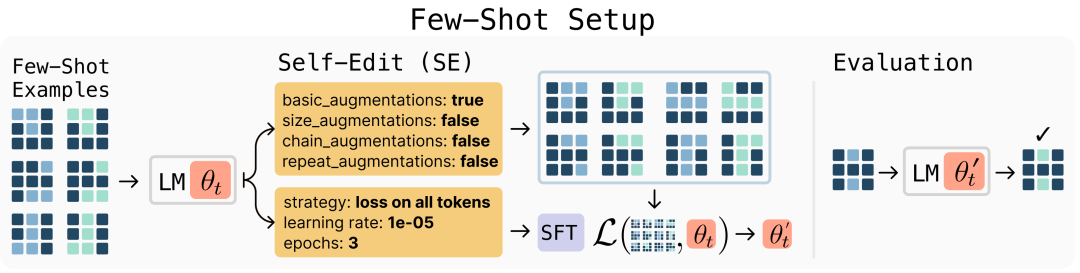
给定新输入时,模型会产生自我编辑结果——这种生成内容可能以不同方式重组信息、指定优化超参数,或调用工具进行数据增强与基于梯度的更新。通过监督微调(SFT),这些自我编辑会带来持久的权重更新,实现长效适应能力。

研究人员表示,在知识融入和小样本泛化任务上的实验表明,SEAL朝着实现针对新数据进行自主适应的语言模型迈出了有前景的一步。

在海量文本语料库上预训练的大型语言模型(LLMs)在语言理解和生成方面展现出显著能力。然而,由于特定任务数据的可用性有限,将这些强大的模型适配于特定任务、整合新信息或掌握新型推理技能仍然具有挑战。
于是一个新的课题诞生了:LLM能否通过转换或生成自身的训练数据及学习流程来实现自我适应?
类比来说,这就像是一个学生为考试做准备,许多学生会依赖笔记复习,这些笔记通常源自课堂内容、教科书或互联网上的信息。相较于直接依赖原始内容,学生通过吸收信息并以笔记形式重新书写,往往能提升对内容的理解能力和答题水平。
以更易理解的方式重新诠释和扩充外部知识的现象,并非仅存在于考试准备中,而是人类跨任务学习的普遍特征。
这种将数据同化、重组或重写作为学习过程一部分的方式,与大型语言模型(LLM)的典型训练和部署方式形成鲜明对比。

为实现语言模型的高效可扩展适应,研究人员试图赋予LLM生成自身训练数据及利用这些数据的微调指令的能力。
具体而言,SEAL通过强化学习(RL)学习生成这些自我编辑内容,将模型更新后的下游任务表现作为奖励信号。
每次训练迭代包括:模型基于任务上下文生成自我编辑内容,通过监督微调应用该编辑,评估更新后的模型,并对提升性能的编辑进行强化。这一过程通过名为ReSTEM的轻量级强化学习算法实现,该算法通过拒绝采样选择高奖励样本,并通过监督微调进行强化。
最终,预期的效果出现了。
研究人员在两个领域测试了SEAL:
1、知识整合,其任务是微调模型,将给定段落中的新事实信息内化,以便它无需访问原始上下文即可回答相关问题;

2、在ARC上进行小样本学习,模型必须通过生成自己的数据增强和训练配置,从少量演示中进行泛化,以解决抽象推理任务。
结果显示:
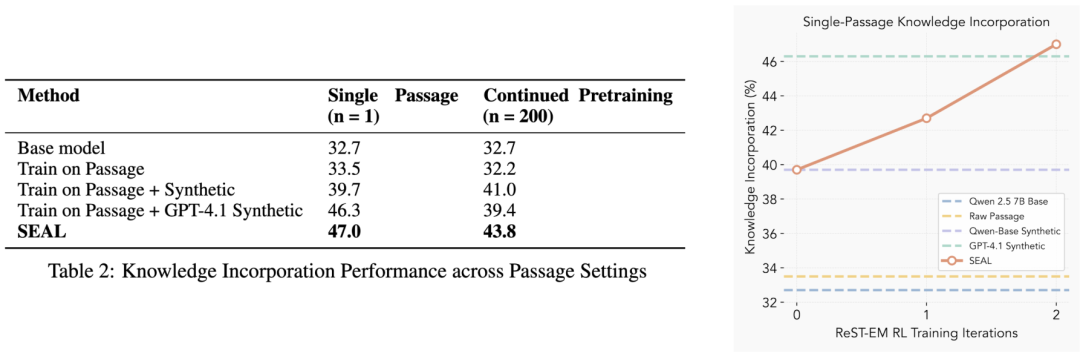
1、关于知识整合任务:在从文本段落中吸收事实性知识的任务上评估SEAL。
在单段落场景中,经过两轮ReST-EM算法优化后,SEAL将问答准确率从32.7%(未适应)提升至47.0%,性能超过直接基于原始段落或GPT-4.1生成的合成数据进行微调的模型。
在包含200个段落的持续预训练场景中,SEAL仍以43.8%的准确率达到最优表现,这表明其学习到的编辑策略可扩展至超出RL训练时的单段落场景,凸显了SEAL将非结构化文本转化为微调数据的能力。
2、关于小样本学习任务:在ARC基准的简化子集上,SEAL实现了72.5%的成功率,显著优于上下文学习(0%)和使用未经训练的自我编辑进行测试时训练(20%)的表现。

这表明SEAL能够自主学习如何配置数据增强方法和训练策略,从而在有限样本演示下实现稳健的泛化能力。
不过SEAL目前并非完美的框架。
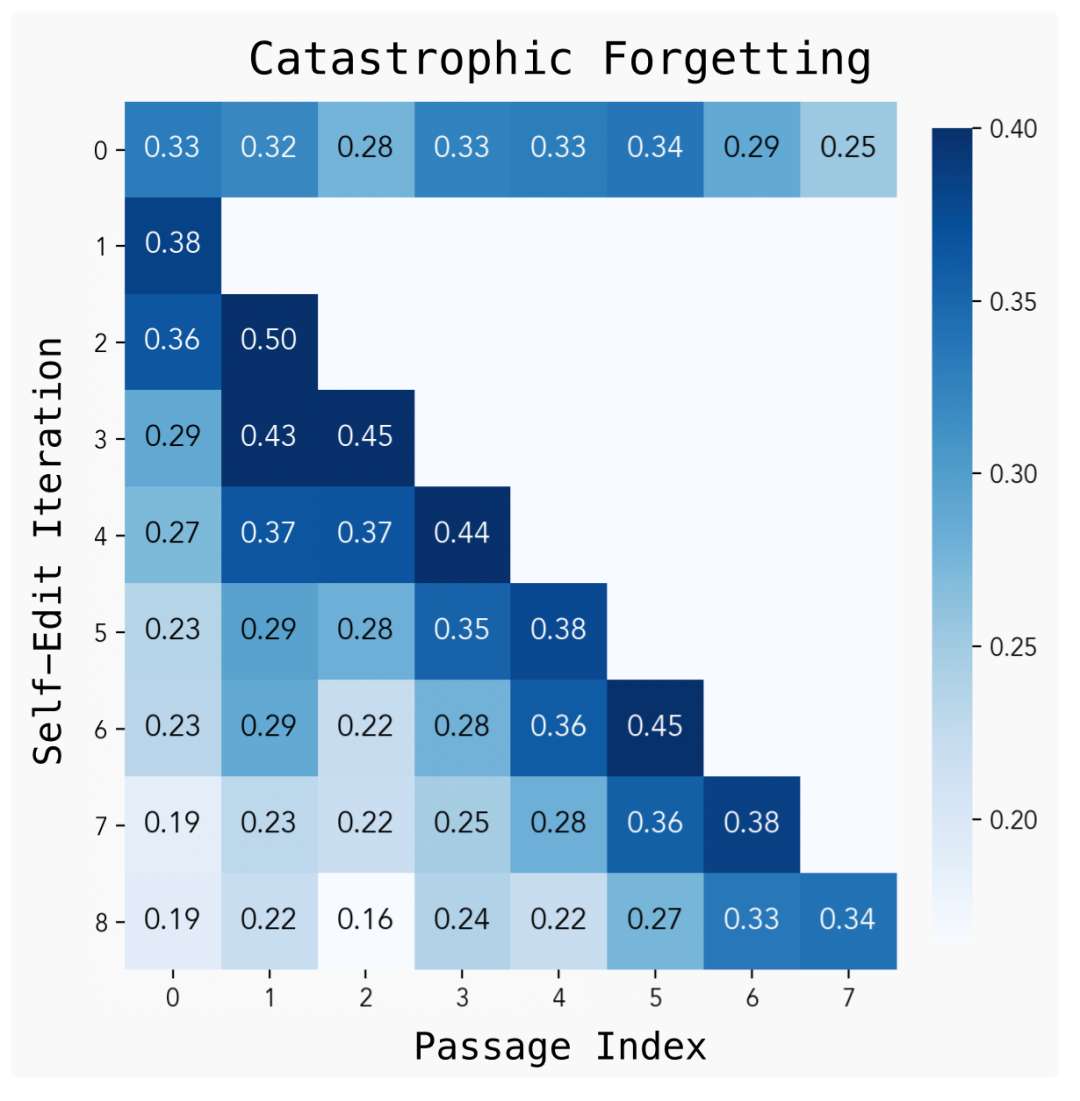
研究人员表示,尽管SEAL通过自我生成的权重更新实现了长效适应,但持续学习实验表明,重复的自我编辑可能导致灾难性遗忘——随着新更新的应用,模型在早期任务上的性能会下降。
这表明,若缺乏明确的知识保留机制,自我修改可能会覆盖有价值的先验信息,解决这一问题仍是一个开放性挑战,潜在的解决方案包括经验回放、约束更新或表征叠加。
下一步,该研究团队设想开发不仅能自适应权重,还能推理“何时”及“如何”适应的模型——在推理过程中判断是否需要进行自我编辑。
这类系统可将思维链轨迹迭代提炼为权重,将短暂的推理能力转化为永久能力,为通过交互与反思持续进化的智能体模型奠定基础。
业内预测,到2028年前沿大型语言模型(LLM)将完成对所有公开的人类生成文本学习训练,最终迎来 “数据墙” 问题,这将促使模型必须更多采用合成数据增强技术。
预期的下一步是通过元训练构建专用的合成数据生成模型,以产出全新的预训练语料库,使未来模型无需依赖额外人类文本即可实现规模扩展与更高数据效率。
SEAL证明,大型语言模型无需在预训练后保持静态——通过学习生成自身合成自我编辑数据并通过轻量级权重更新应用数据,模型可自主整合新知识并适应新任务。
展望未来,该研究团队设想将SEAL框架扩展至预训练、持续学习和智能体模型,最终使语言模型能在数据受限的世界中实现自我学习与规模扩展。
-END-

(文:头部科技)