

文心4.5开源了10个不同尺寸的MoE/Dense的多模态大模型,提出了一种创新性的多模态异构模型结构,通过跨模态参数共享机制实现模态间知识融合,同时为各单一模态保留专用参数空间。
此架构在保持甚至提升文本任务性能的基础上,能够显著增强多模态理解能力。这里我们不展开架构和预训练范式的讨论,直接看它的后训练部分。
后训练阶段主要是针对模态的单独精调。其中,大语言模型针对通用语言理解和生成进行了优化,多模态大模型侧重于视觉语言理解,支持思考和非思考模式。每个模型采用了SFT、DPO或UPO(Unified Preference Optimization)的多阶段后训练。
LLM的后训练
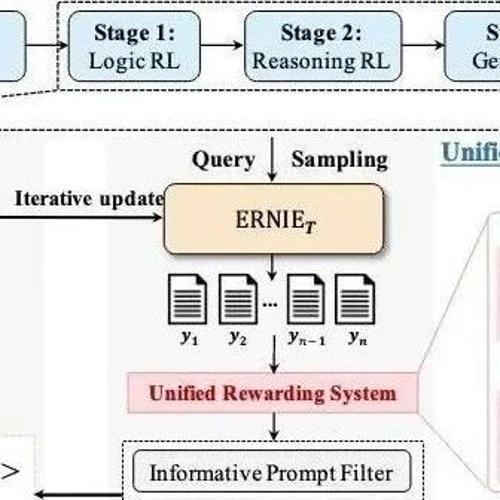
一图以蔽之
SFT阶段
这部分数据涵盖十个领域,包括科学与数学、编码、逻辑、信息处理、创意写作、多语言、知识QA、多轮与角色扮演和安全领域。根据推理和非推理任务,也包括CoT数据和非CoT数据。此外,为了进一步提升SFT数据的多样性,针对推理任务的一些query引入了具有不同推理内容的多个response使得模型具备在RL阶段进行探索的能力。SFT阶段共使用了230w个样本,平均每个模型训练两个epoch。
RL阶段
统一奖励系统Unified Rewarding System
针对推理任务,优先使用基于规则的验证器,但是验证器的泛化性有限,因此额外引入以下三种补充机制:
-
• Sandbox:针对代码任务的独立沙盒,以验证代码的可执行性 -
• Reference-Guided LLM-as-a-Judge (RLLM):给定参考答案作为指导,利用大模型进行评测 -
• Reference-Guided Discriminative Reward Model (RDRM):也是给定参考答案,利用大模型进行评测(报告中没过多说明RDRM和RLLM的差别?)
针对非推理任务:
-
• Checklist-Aware Verifiers:设计一些可以衡量的显式指标,需要明确定义且可客观评估 -
• Generative Reward Models (GRM):基于多维评价指标和动态反馈,进一步训练了一个生成式奖励模型,以给出评价 -
• Discriminative Reward Models (DRM):基于人类反馈训练的判别式奖励模型(BT model)
2. 强化学习训练
在形成奖励系统后,模型基于PPO进行了渐进式的强化训练。第一阶段在逻辑语料库上进行了训练,目的在于构建模型逻辑分析和抽象推理的基础能力;第二阶段在数学和编程语料上进行了训练,目的在于进一步提升抽象推理的能力,以及回复的结构表现力和可执行性;第二三节在通用任务上进行训练,利用早期阶段获得的知识,增强了通用任务的泛化性。
除了PPO loss外,模型训练额外引入了一种 Unified Preference Optimization (UPO) loss ,即DPO loss。而根据成对样本的构造方式,又分为online-UPO和offline-UPO。online-UPO指在PPO过程中,根据当前模型分布使用拒绝采样构造样本对,因此这样的采样过程和loss计算过程是online的。offline-UPO则是在PPO之前,将样本对先offline采好。报告称这样的方式可以有效地缓解reward hacking现象,稳定训练过程。
此外,还对强化训练的输入数据集进行了一系列过滤。首先,剔除模型无法提供有效学习信号的样本(如完全错误或完全正确prompt),尤其针对验证器相关的奖励信号。此外,剔除奖励信号方差过小的样本组(即组内样本奖励差异不显著),保留具有判别性的样本。为了减少不同领域/来源奖励的分布差异,将训练数据按主题领域分层后,对每类子集的验证器与奖励模型的奖励输出独立进行奖励标准化,消除领域间量纲差异,也避免了不同来源奖励的相互干扰。
VLM的后训练
同样一图概括
SFT阶段
首先,高质量的image-caption对是非常稀缺的,因此报告表明首先通过描述合成的方式在真实STEM(科学/技术/工程/数学)图像中来获取sft训练集。因此,将描述合成作一个约束优化问题:使用一个VLM生成字幕,然后使用一个text-only的推理模型在无图像输入仅描述输入的前提下,解决相关问题,仅保留能够正确解决问题的描述。
接下来则是一个三阶段的渐进式训练框架。
1. Text-only Reasoning Cold Start
基于各种纯文本的图像推理数据,涵盖数学、科学、代码生成、指令跟随和对话任务,对模型进行微调,报告称模型虽未见过图像数据,但仍涌现出了一些推理行为,例如“let me take another look at the image”,为后续训练奠定基础
2. Reject Sampling for Multimodal Enhancement
基于第一步得到的模型,通过拒绝采样生成视觉相关推理数据(STEM、图表分析、创意写作等任务),扩展能力边界,同时也会持续丰富多模sft训练集。
3. Thinking and Non-Thinking Fusion
使用两种方式实现推理和非推理模式的融合,第一种方法是将上一步生成的推理数据与常规非推理数据联合训练,非推理数据响应前添加空思考标签 <think>\n\n</think>,标签部分参与前向传播但屏蔽梯度更新。第二种沿用DeepSeek-R1T-Chimera的方法,将非推理模型的多模态专家参数迁移至推理模型。
RL阶段
参考RLVR的方式,针对不同的任务,报告提出了不同的verifier-based奖励机制。
Visual STEM任务
这一类问题通常有对应的开源数据集和标准答案,因此直接根据标准答案给出奖励即可,在训练前会筛除模型始终正确或错误的数据,另外多选题会重新组织为开放式问题。
Visual Puzzles任务
收集了包含10k个Visual Puzzles题目的数据集,预处理步骤和Visual STEM任务相同。采用两个LLM来判断模型输出答案正确与否,一个 LLM 用于评估答案是否包含任何内部不一致或冲突的部分,而另一个 LLM 用于验证最终答案的正确性。只有当两个 LLM 都返回正面评估时,响应才被视为正确。
UI2code任务
收集了 UI2Code 和 Image2Struct数据集,都是针对从 UI 设计图像生成 HTML 代码。部署了一个 UI2Code 验证器环境,该环境评估用户提供的参考图像与从 VLM 生成的 HTML 代码呈现的 UI 之间的视觉保真度。
在进行RL训练时,最终的的reward由一个预先训练的BT model和上述提到的verifier-based reward共同组成,使用GRPO结合DAPO的诸多trick进行了训练。
评测结果
预训练模型
300B-A47B 后训练模型
21B-A3B 后训练模型
多模态后训练模型(支持思考)
(文:机器学习算法与自然语言处理)