


本文工作由清华大学电子系医工交叉平台吴及教授和刘喜恩助理研究员所领导的医学自然语言处理团队,联合北邮、科大讯飞、无问芯穹等单位共同完成。第一作者周宇轩为清华大学电子工程系博士生,其研究方向聚焦于大模型的医疗垂类能力评估与优化,此前已提出 MultifacetEval(IJCAI 2024)与 PretexEval(ICLR 2025)等医学知识掌握的多面动态评估框架体系。吴及教授和刘喜恩助理研究员所领导的医学自然语言处理团队长期致力于面向真实需求驱动的医工交叉前沿技术研究与产业变革,曾在 2017 年联合科大讯飞研发了首个以 456 分高分通过国家临床执业医师资格考试综合笔试测试 AI 引擎 Med3R(Nature Communications 2018)并在全国 400 多个区县服务于基层医疗;2021 年联合惠及智医研发了首个基于全病历内容分析的智慧医保 AI 审核引擎,获得国家医保局智慧医保大赛一等奖,并在全国多个省市进行示范应用。
大语言模型(Large Language Models,LLMs)技术的迅猛发展,正在深刻重塑医疗行业。医疗领域正成为这一前沿技术的 “新战场” 之一。大模型具备强大的文本理解与生成能力,能够快速读取医学文献、解读病历记录,甚至基于患者表述生成初步诊断建议,有效辅助医生提升诊断的准确性与效率。
该技术有望在缓解医生工作负担、提升就诊效率、优化医疗管理水平等多个方面发挥重要作用。
虽然当前主流大语言模型在 MedQA 等医疗问答基准数据集上已取得 90% 以上的准确率,显示出强大的语言理解与推理能力,但临床一线的实际反馈表明,其在真实医疗场景中的应用效果仍不理想,普遍存在 “高分低能” 的问题。
在当前大语言模型不断取得评测突破的背景下,一个关键问题亟需回答:为何其在真实临床问题中仍难以发挥预期效能?
究其根本,是由于医学知识覆盖尚不充分,还是因缺乏有效的临床应用能力?亦或是在面对复杂、动态的真实场景时,模型在临床推理与决策层面存在显著短板?抑或三者皆为限制其实际落地的关键因素?
近日,清华大学电子系医工交叉平台刘喜恩助理研究员领衔的医学自然语言处理团队,联合多家单位在 ICML 2025 会议上发布最新研究成果,首次提出从医学知识掌握到临床问题解决的 “全周期” 大语言模型医学能力评测框架 ——MultiCogEval。
该框架覆盖大模型在不同认知层次下的医学能力评测,为全面理解大语言模型在医疗领域的能力边界并洞察其在真实临床场景中面临的核心短板,提供了全新视角与分析工具。

-
论文标题:Evaluating LLMs Across Multi-Cognitive Levels: From Medical Knowledge Mastery to Scenario-Based Problem Solving
-
论文链接:https://openreview.net/pdf?id=sgrJs7dbWC
-
项目主页:https://github.com/THUMLP/MultiCogEval
如何构建一个 “全周期” 医学评测框架?
在大多数国家,医学生通常需依次完成基础医学知识学习、临床见习以及住院医师规范化培训,方可成为一名合格医生。这一培养路径契合人类认知能力的发展规律:先通过记忆与理解掌握基础医学知识,继而在典型病例中运用所学进行具体分析,最终具备在真实临床场景中进行规划与问题求解的能力。与此相对应,针对临床能力的评估体系也呈现出分层递进的结构:从基础课程考试,到临床技能测评,再到住培阶段的综合结业考核,逐步覆盖不同认知层次。
然而,现有医学大模型评测集的任务设计多聚焦于单一类型(如问答、诊断等),尽管这类评估有助于比较不同模型间的性能差异,但通常仅覆盖某一特定认知层次,难以全面反映大模型在医学应用中所需的多层次、全流程能力。部分评测工作尝试通过引入多种任务来覆盖不同认知层次,但仍存在两方面问题:其一,不同任务与认知层次之间缺乏明确对应关系;其二,各任务所涉及医学知识点的覆盖范围、评测指标差异较大,导致跨任务的评估结果缺乏可比性与解释力。
为应对上述挑战,研究人员提出了多认知层次医学评测框架 MultiCogEval。该框架设计了一系列覆盖医学生培养全流程、对应不同认知层次的医学任务,并结合医学知识点对齐与评测指标统一等方法,实现了跨认知层次的评估可比性与结果可解释性,为大模型医学能力的系统性评估提供了有效支撑。
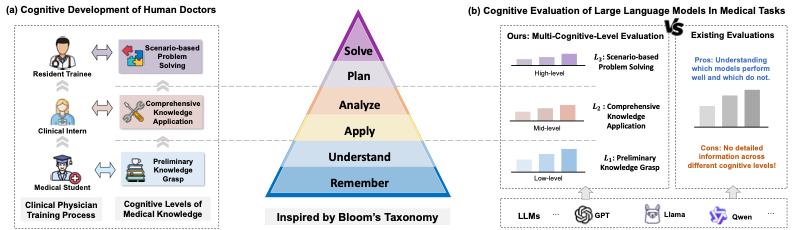
(图 1):人类医师医学认知能力发展流程与大模型医学能力评测的对应关系
MultiCogEval:多认知层次医学评测框架
受现有医师培养流程启发,MultiCogEval 从三个认知层次考察大语言模型的临床能力:
-
基础知识掌握:评测模型对基础医学知识的记忆与理解程度。在这一层次上,MultiCogEval 采用现有 LLM Benchmarks 中最常用的多项选择题(Multiple-choice Questions)进行评测;
-
综合知识应用:评测模型综合运用所学知识解决临床任务的能力。与多项选择题相比,真实临床场景往往可用信息更少、决策空间更大,同时依赖多步推理才能得到结果。为了进一步逼近这些真实临床场景的应用需求,MultiCogEval 从这三个维度出发,分别设计了三种任务进行评测;
-
场景问题求解:评测模型在真实临床场景中主动规划求解的能力。尽管现有的一些医学评测集(如 MedQA)涉及对医学案例的分析与诊断,但这些评测集往往是将所有诊断信息一次性通过题干的形式提供的。与之相比,真实临床场景则依赖医师基于已有的诊断信息进行主动决策,通过查体、实验室检查、影像学等方式收集诊断信息,最终综合已有的诊断信息做出诊断。在这一层次上,MultiCogEval 采用一种模拟诊断任务,考察大模型在信息不足条件下主动规划检查检验,并完成诊断的能力。
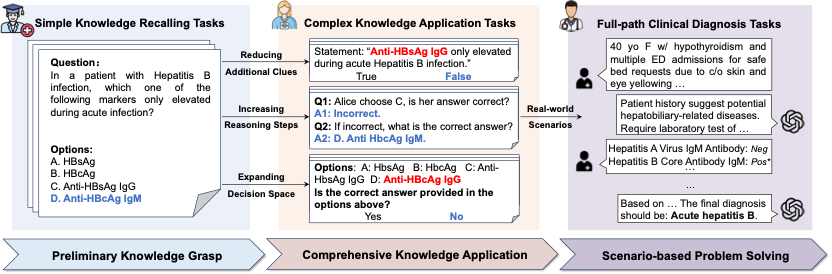
(图 2):多认知层次医学评测框架 MultiCogEval
实验结果:当前大模型的临床场景问题求解能力仍待加强
基于该评测框架,研究人员对一系列知名大模型进行了系统的评测,观察到多种 SOTA 大语言模型(如 GPT-4o、DeepSeek-V3 和 Llama3-70B)在低阶任务(基础知识掌握)上表现出色,准确率超过了 60%。然而,当在中阶任务(综合知识应用)上进行评估时,这些模型的性能均出现了显著下降(约 20%)。此外,在高阶任务(场景问题求解)中,所有模型的表现进一步下滑,其中表现最好的 DeepSeek-V3 的全链条诊断准确率也仅为 19.4%。这表明,尽管当前的大语言模型在基础医学知识方面已经具备较强的掌握能力,但在更高认知层级上,尤其是在应对真实医疗场景中的复杂问题时,仍面临巨大挑战。
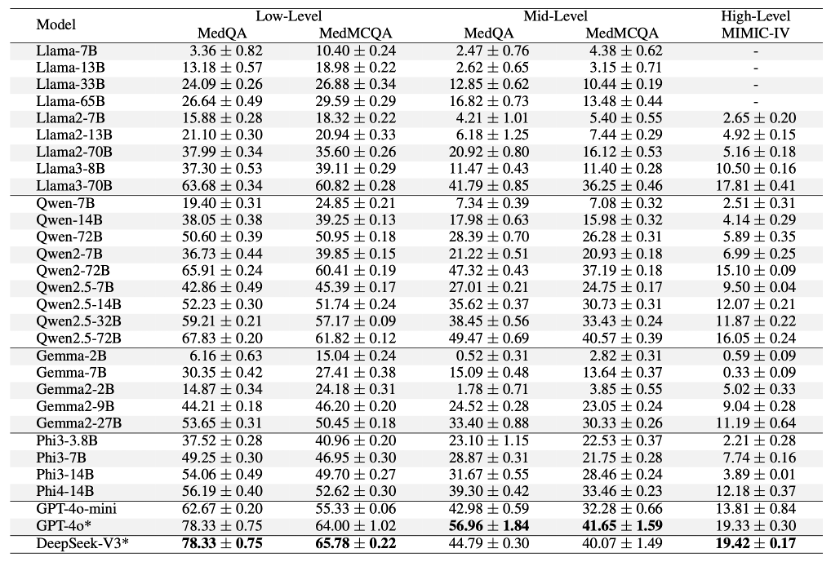
(表 1):来自多个系列的通用大模型在 MultiCogEval 不同层次上的评测表现
为研究医学领域 SFT 对大语言模型在不同认知层级上的影响,研究人员进一步对比了医学大模型与对应基座模型,发现医学领域 SFT 可以有效提升大模型的低阶(基础知识掌握)与中阶(综合知识应用)临床能力(最高可达 15%)。然而,在高阶任务(场景问题求解)上,它们未能取得显著进步,有些甚至表现不如基座模型。
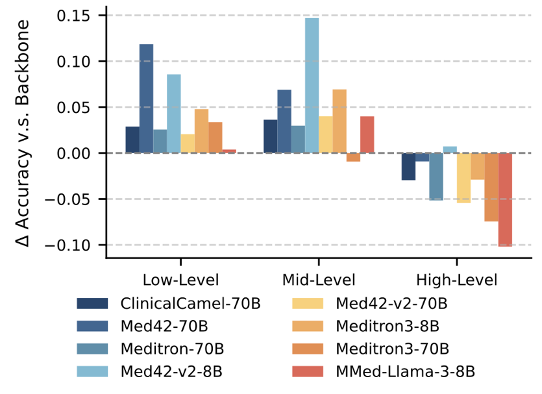
(图 3):多个医学专用大模型在 MultiCogEval 不同层次上的评测表现
最后,研究人员进一步研究了推理时扩展(inference-time scaling)在提升大语言模型医学能力方面的效果。如表 2 所示,推理增强模型在所有认知层级上均优于对应的指令微调模型,且在中阶任务上的提升更为显著(例如 DeepSeek-R1 在中阶任务上提升了 23.1%,而在低阶任务上仅提升了 9.8%)。然而,当前的推理增强模型仍然没有完全解决高阶任务,说明现有的模型在真实临床场景中主动规划、获取决策信息进行推理的能力仍然有待进一步提升。
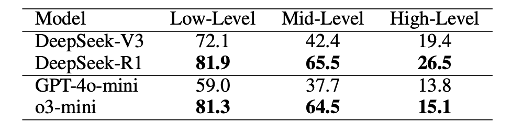
(表 2):推理增强模型与指令微调模型在不同层次任务上的性能对比
结语
本研究首次提出了多认知层次医学能力评测框架 MultiCogEval,系统性地对大语言模型在基础知识掌握、综合知识应用和场景问题求解三大认知层级上的医学能力进行评估。通过构建面向全流程医学任务的评测体系,并在多个主流通用大模型与医学专用模型上进行评测与分析,研究团队发现:
-
当前大模型在低层级医学任务表现较为出色,具备较强的医学知识记忆与理解能力。但随着任务认知复杂度的提升,模型在中高层级任务上的能力出现明显下降,尤其是在高阶临床场景下的主动信息获取与推理决策能力仍显不足;
-
医学领域微调在提升基础与中阶能力方面效果显著,但对高阶任务性能提升有限;
-
推理时扩展方法能够显著增强模型在各个层次医学任务上的表现,特别是在复杂任务中,但仍不足以完全弥补模型在高阶能力方面的短板。
MultiCogEval 的发布为后续的医学大模型研发与评测奠定了坚实基础。我们期待该框架能促进大模型在医学领域的更加稳健、可信、实用的落地,真正助力构建 “可信赖的 AI 医生”。

©
(文:机器之心)