
RAG

RAG&KG&LLM&文档智能四大领域技术前沿:老刘说NLP技术社区持续对外纳新

老刘说NLP技术社区围绕大模型&RAG&文档智能&知识图谱四个主题,提供每日早报、线上分享和专题课程等多种形式的技术内容,旨在提升成员的技术深度感。
抛弃 OCR,抛弃文本提取,抛弃分块!提升RAG性能的新方法!
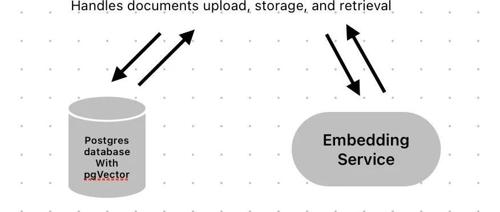
文章介绍了 Col iVara 项目,它通过视觉模型直接处理文档中的图片、表格和布局等视觉元素,以提升 RAG 应用的性能,并提供简洁易用的 API 和 SDK。
专用于RAG以及AI应用的一款高性能图向量数据库:HelixDB
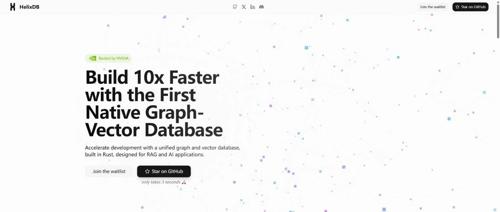
HelixDB是一款高性能图向量数据库,比Neo4j快1000倍,比TigerGraph快100倍,原生支持图形和矢量数据类型,适合RAG和AI应用如知识图谱、语义搜索等。

数据合成方案:知识图谱增强RAG用于难度可控问题生成思路及实现流程

今天继续探讨知识图谱在数据合成上的应用,介绍了一种利用知识图谱结合RAG进行问题生成的方法,《KAQG: A Knowledge-Graph-Enhanced RAG for Difficulty-Controlled Question Generation》(https://arxiv.org/pdf/2505.07618)。论文通过定义多个维度的难度指标来量化难度,使用PageRank算法筛选知识点,并结合大模型生成具体题目。
大模型生成过程可视化开源工具、Zerosearch误读及开源项目中的RAG文档解析问题

文章介绍了大模型生成过程可视化的几个工具,包括OpenMAV、logitloom和ReasonGraph,并讨论了zerosearch的误读以及开源项目中的RAG文档解析问题。
关于人工智能应用场景中前期数据处理的业务场景和技术分析——包括结构化数据和非结构化数据
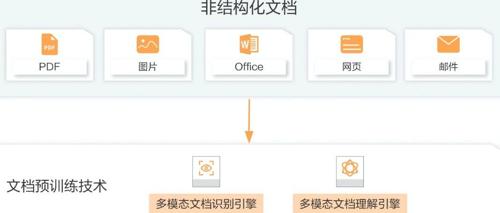
文档处理在人工智能领域中至关重要,涉及复杂的业务场景和技术实现。文章讨论了不同类型文档的处理方法及其技术方案,指出非结构化数据是最具挑战性的类型之一,需要采用多模态模型和特定技术来简化处理过程。
干货满满的斯坦福的Agentic AI研讨会要点总结

最近,斯坦福大学举办了一场关于 Agentic AI 的网络研讨会,探讨了 Agentic 语言模型的应用及其在实际中的应用方式,涵盖反思、规划、工具使用及迭代调用等设计模式。
紧跟技术理论前沿、开源项目实现及行业落地案例:老刘说NLP技术社区持续对外纳新

老刘说NLP技术社区介绍了一个以技术前沿跟踪、项目实现解读和知识分享为核心的技术社区。目标群体包括学生、技术研发者等,提供多种学习资源和活动形式。