

今天是2025年5月15日,星期四,北京,晴。
我们之前在《如何用知识图谱+医疗问答对合成推理数据?兼看Deep Research的两个复刻实现拆解》(https://mp.weixin.qq.com/s/p6aO9VRvsAOzXXhe518m4A)中介绍了怎么用知识图谱+问答对来合成大模型推理数据《MedReason: Eliciting Factual Medical Reasoning Steps in LLMs via Knowledge Graphs》,(https://github.com/UCSC-VLAA/MedReason,https://huggingface.co/collections/UCSC-VLAA/medreason,https://arxiv.org/pdf/2504.00993),大致流程是,从医疗数据集中提取问答对->使用LLM提取问答中的实体,并将这些实体映射到医疗知识图谱中的相应节点->识别知识图谱中连接问答实体的所有推理路径,并指导LLM剪枝不相关的路径->最终的推理路径送入大模型做生成cot->过滤出满足答案的cot,指导LLM生成医学上基于事实的CoT解释。核心是剪枝不相关的路径。
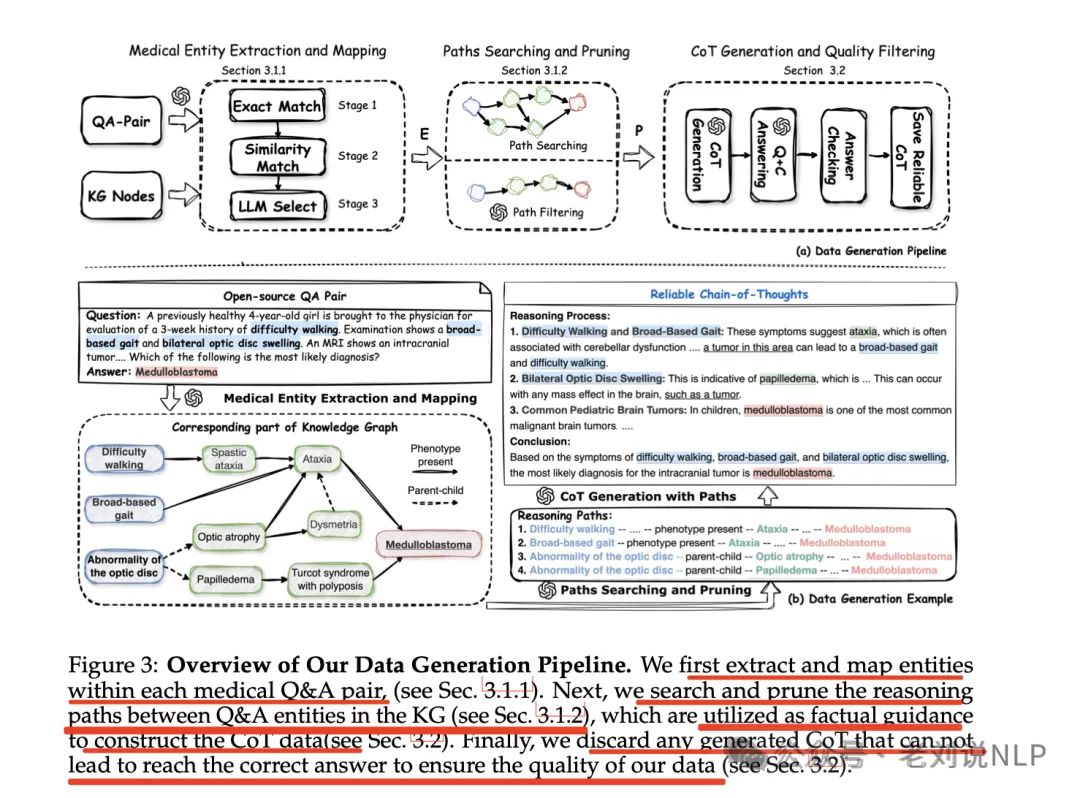
今天我们继续来看看知识图谱在数据合成上的另一种代表思路,来看看如何利用知识图谱结合RAG进行问题生成?里面的难度量化思路值得看看,以及知识图谱在其中所扮演的角色。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、如何利用知识图谱和RAG进行问题生成?KAQG思路
知识图谱合成数据进展,看一个KAQG,知识图增强的RAG,用于难度控制问题生成,论文在《KAQG: A Knowledge-Graph-Enhanced RAG for Difficulty-Controlled Question Generation》,https://arxiv.org/pdf/2505.07618,实现代码在https://github.com/mfshiu/kaqg,用来生成问题,当然,问题包括选择题、多项选择题和填空题,类型并不多,重点看这个难度量化是怎么做的。看看具体怎么做的。
分成两个模块,一个是KAQG-Retriever进行检索,一个是KAQG-Generator进行问题生成。

其中:
1、KAQG-Retriever模块
使用LLMs将文档解析为知识图谱元三元组,包括实体、关系和上位词。每个学科存储在一个独立的知识图谱中,以确保内容相关性和避免跨域干扰。

这块的逻辑在:https://github.com/mfshiu/kaqg/blob/main/src/retrieval/pdf_retriever.py
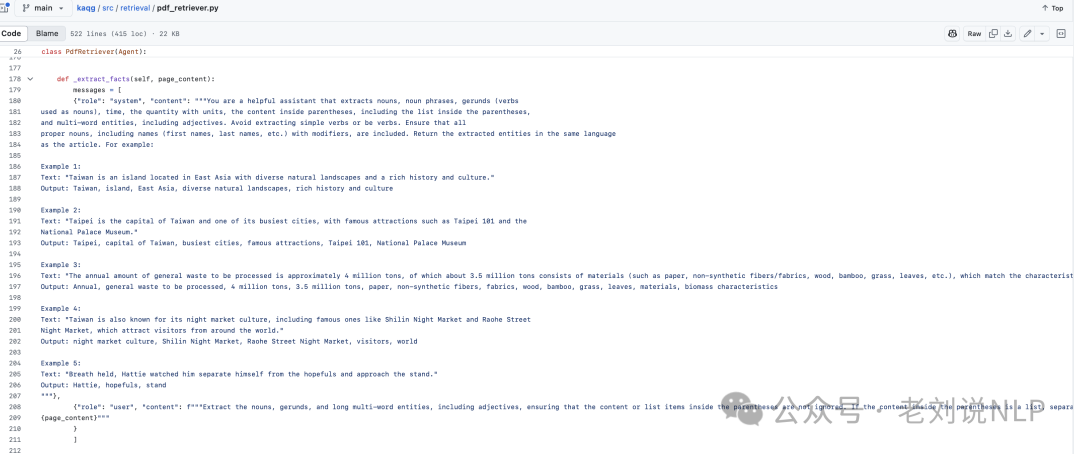
2、KAQG-Generator模块
包括问题生成和问题评估两个模块,怎么定义问题难的问题,其实需要量化,所以搞了一套:

1)题干长度:较长的题干通常会提高阅读负担和复杂性。
2)特定领域词汇密度:专业术语的更高浓度增加了认知需求。
3)题干的认知水平:要求高级认知技能(例如,分析、评价)的题干通常难度较高。
4)平均选项长度:冗长的选项可以增加阅读时间并提高混淆的可能性。
5)选项之间的相似性:高度相似的干扰项使题目更具挑战性。
6)题干与选项之间的相似性:术语或概念的重叠可能导致误解。
7)高度合理的干扰项数量:更合理的干扰项提高了整体难度,并能更好地区分不同的能力水平。
所以,基于这个假设,可以在问题生成侧进行控制。
一个是问题相关联的上下文拿到,并且要保证多样性和重要性,所以很自然问题生成使用PageRank对知识关系进行排名,使用KG Reader来召回节点、使用PageRank排名来筛选。
较高的PageRank分数指导选择更为关键的主题,从而确保所生成的问题涵盖主题的核心内容,所有通过is_a关系与概念相连的事实节点也使用相同的PageRank算法进行评估,以确定它们的重要性。
对于每个概念,所有重要事实及其子连接随后被纳入问题生成的材料中,从而丰富测试题目的深度和广度。排序的逻辑在:https://github.com/mfshiu/kaqg/tree/main/src/generation/ranker
然后,在问题生成时,设定对应的难度信息来控制,这里的实现逻辑就是一个分数加权,对几个维度都进行定义,然后交给大模型通过指令遵循完成,在:https://github.com/mfshiu/kaqg/blob/main/src/evaluation/features.py


二、从代码看怎么具体实现逻辑
在代码https://github.com/mfshiu/kaqg/blob/main/src/generation/test.py中可以看到执行逻辑,就是通过参数组合、生成题目叙述,并利用OpenAI的GPT模型生成具体的题目。
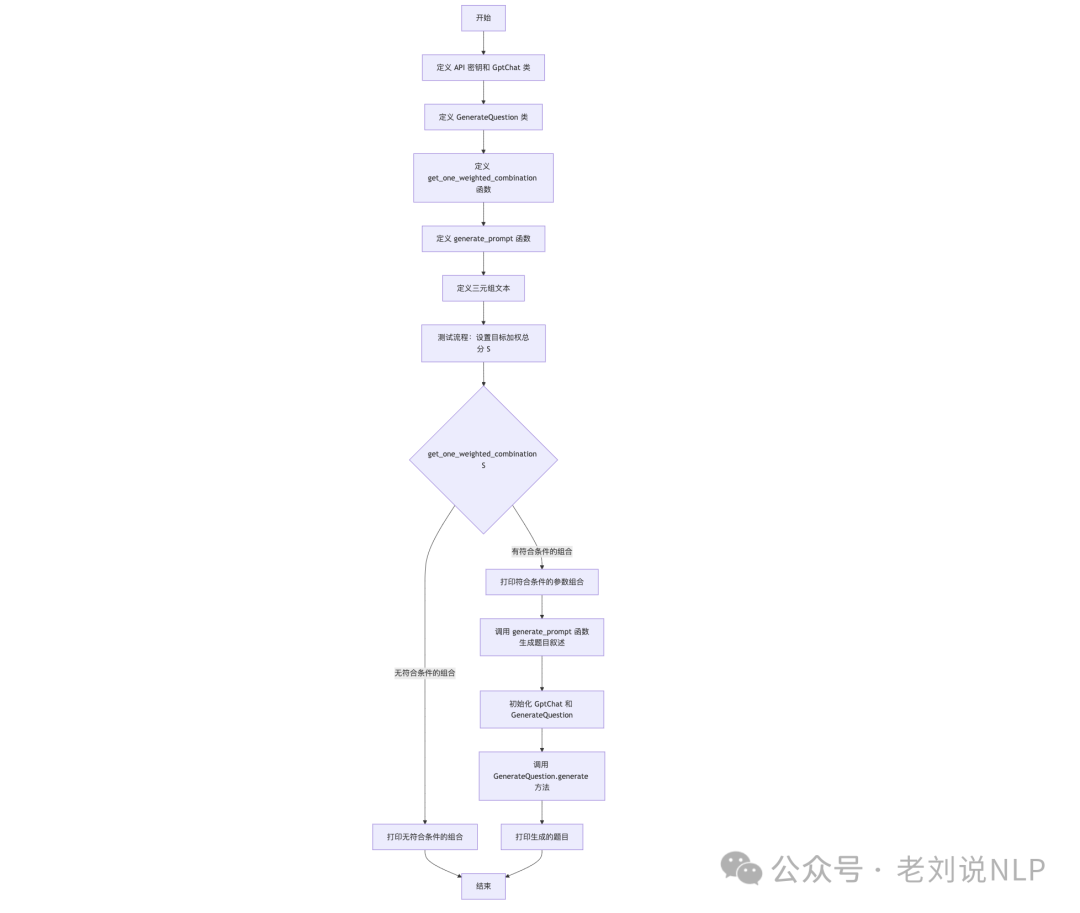

具体思路如下:
1)定义API密钥和GptChat类:GptChat类用于与OpenAI的GPT模型进行交互,提供聊天完成功能。
2)定义GenerateQuestion类:该类用于生成基于给定特征和文本的多项选择题。
3)定义get_one_weighted_combination函数:该函数根据目标加权总分S,随机生成一组符合条件的参数组合。
4)定义generate_prompt函数:该函数根据参数分数生成出题叙述。
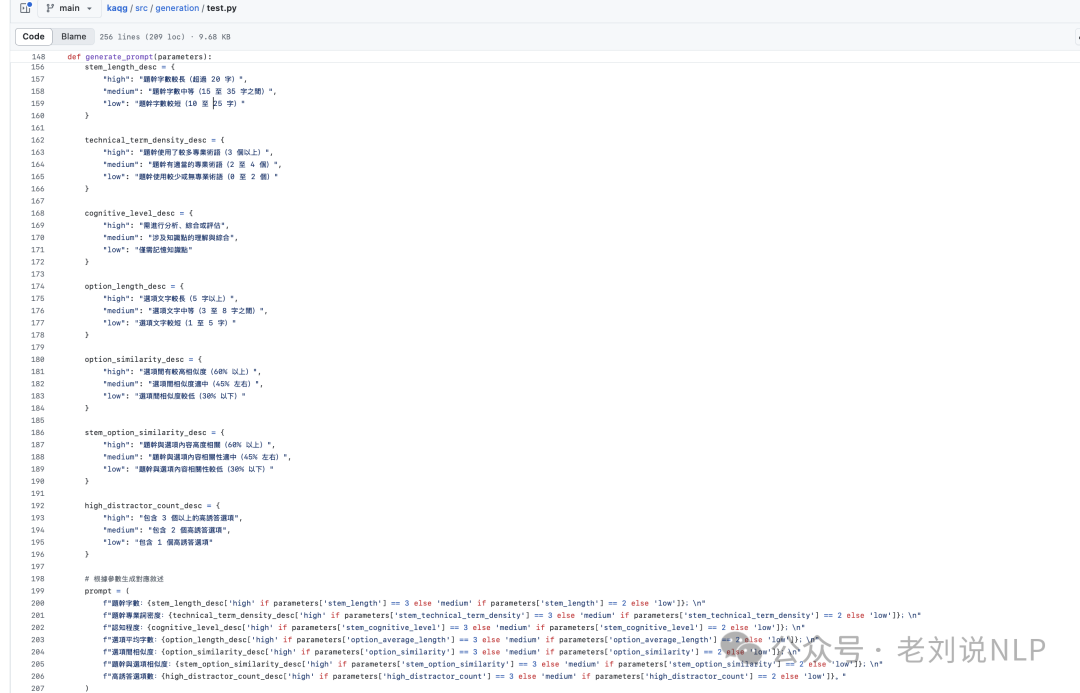
5)定义三元组文本:提供用于生成题目的背景文本。
这个不是可以通过随机采样获得一些三元组。
6)设置目标加权总分S,调用get_one_weighted_combination函数获取符合条件的参数组合,如果有符合条件的组合,则打印组合并生成题目叙述;如果无符合条件的组合,则打印提示信息。

7)调用GptChat和GenerateQuestion:初始化GptChat和GenerateQuestion对象;调用GenerateQuestion.generate方法生成题目并打印结果。

更进一步的,也可以弄成agent的形式来进行交互生成,如下图所示:

参考文献
1、https://arxiv.org/pdf/2505.07618
(文:老刘说NLP)