
在最近的文章中,笔者介绍了影响 Context 高质量供给的关键因素有记忆的存用和记忆的连贯性。
mem0推出王炸mcp工具OpenMemory,打造用户私有、跨应用的共享记忆层
而对记忆源信息(尤其是复杂文档)的深度理解是高质量Conext供给的又一大关键。传统的文本提取和分块方法,在面对图文混排、表格遍布的文档时,往往力不从心,生成的 Context 质量堪忧,这已成为提升 RAG 应用性能的一大瓶颈。
我们都曾经历过这样的“噩梦”:精心构建的 RAG 系统,因为 OCR 识别错误、表格内容丢失、或者图片信息被忽略,导致 LLM 的回答驴唇不对马嘴。PDF、Word 文档、PPT 演示稿中那些精心设计的布局、关键的图表数据、甚至是字体样式的强调,这些丰富的视觉信息在传统处理流程中几乎被完全抛弃,只留下一堆可能支离破碎的文本。
今天介绍一个项目 ColiVara ,正试图从根本上解决这个问题,它带来的不是对现有流程的修修补补,而是一场针对文档检索的“视觉革命”。
ColiVara 的“杀手锏”:用视觉模型“看懂”文档
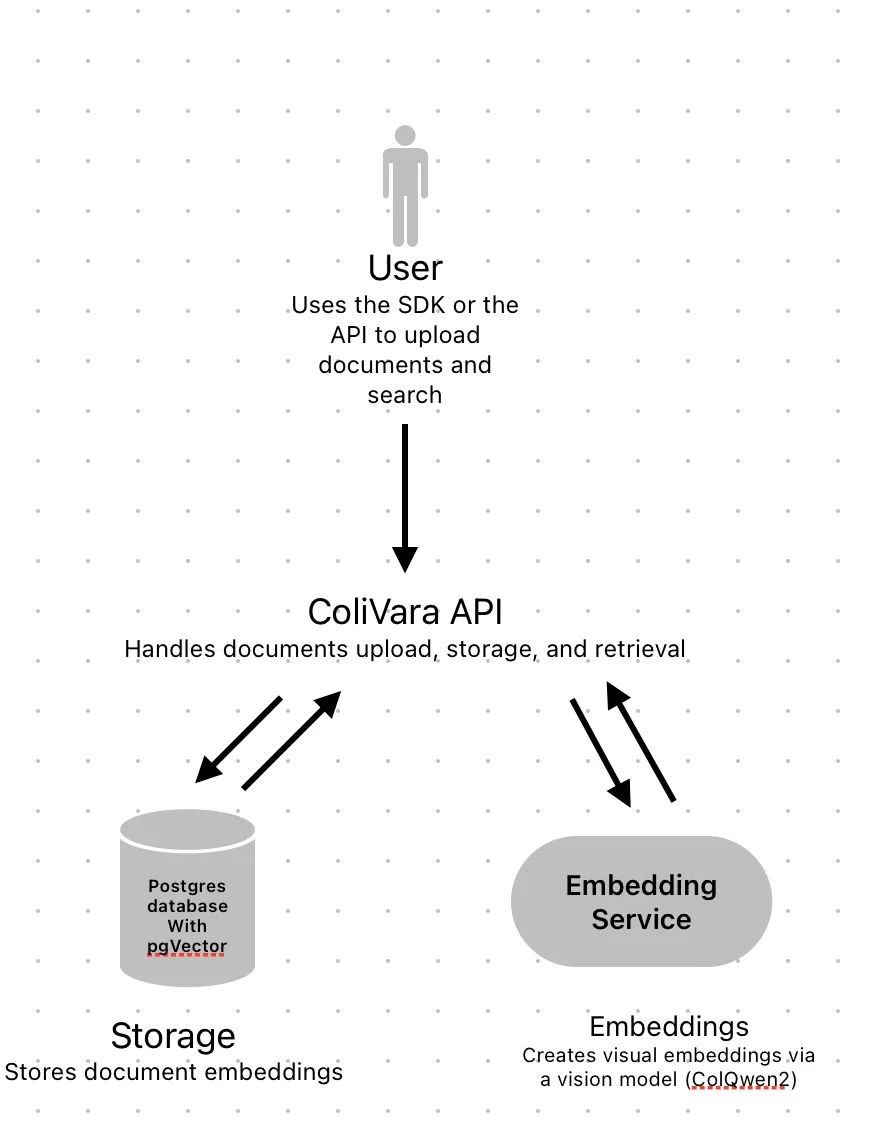
ColiVara 的核心理念十分大胆:抛弃 OCR,抛弃文本提取,抛弃分块! 它直接将文档(支持 PDF, DOCX, PPTX 等超过100种格式)的每一页都视为一张图像,利用先进的视觉语言模型(基于“ColPali: Efficient Document Retrieval with Vision Language Models” 论文[1])来生成文档的“视觉嵌入”。这意味着,ColiVara 不再仅仅“阅读”文本,它更能“看见”并理解文档的整体布局、图片内容、表格结构等视觉元素。
这种方法的优势是颠覆性的:
-
告别信息损失:再也不会有无法识别的表格、丢失的图片、或因分块不当导致的上下文割裂。文档的完整性得到了前所未有的保留。 -
卓越的检索性能:通过整合文本与视觉特征,ColiVara 在文本和视觉文档检索上均展现出业界领先的性能。其采用的“后期交互 (Late-Interaction)”风格嵌入,即便在纯文本文档上,也比传统池化嵌入更为精准。 -
开发者体验友好:提供简洁易用的 Python/Typescript SDK 和 REST API,让开发者可以快速集成。
ColiVara 为何与众不同?
你可能会问,如果我的文档主要是文本,我还需要 ColiVara 吗?答案是肯定的。正如其文档所言,即使是纯文本文档,ColiVara 的后期交互式嵌入也能提供更准确的检索。更重要的是,它为你打开了处理混合内容文档(这才是现实世界中的常态)的全新大门。
-
无需自建向量数据库(大部分情况):ColiVara 使用 Postgres 和 pgVector 为你处理向量存储,极大地简化了部署和维护。当然,如果你坚持,它也提供了单独的嵌入生成端点,让你自由选择存储方案(但需注意其对多向量和后期交互特性的支持)。 -
广泛的格式支持:从 PDF 到 Office 全家桶,再到各种图片格式,基本覆盖了日常工作中的所有文档类型。 -
强大的元数据过滤:不仅能进行语义搜索,还能结合文档或集合的元数据(如作者、日期、标签)进行精确筛选,完美融合非结构化与结构化数据的检索优势。 -
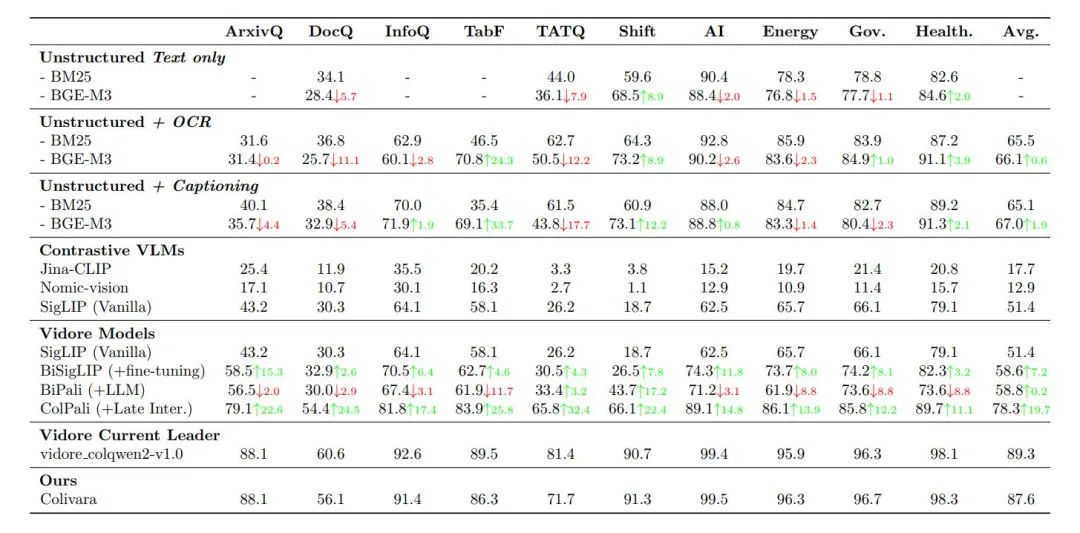
透明的评估体系:基于 Vidore 数据集进行可复现的性能评估,其 Release 1.5.0 版本在多个基准测试中取得了平均 86.8 的高分。 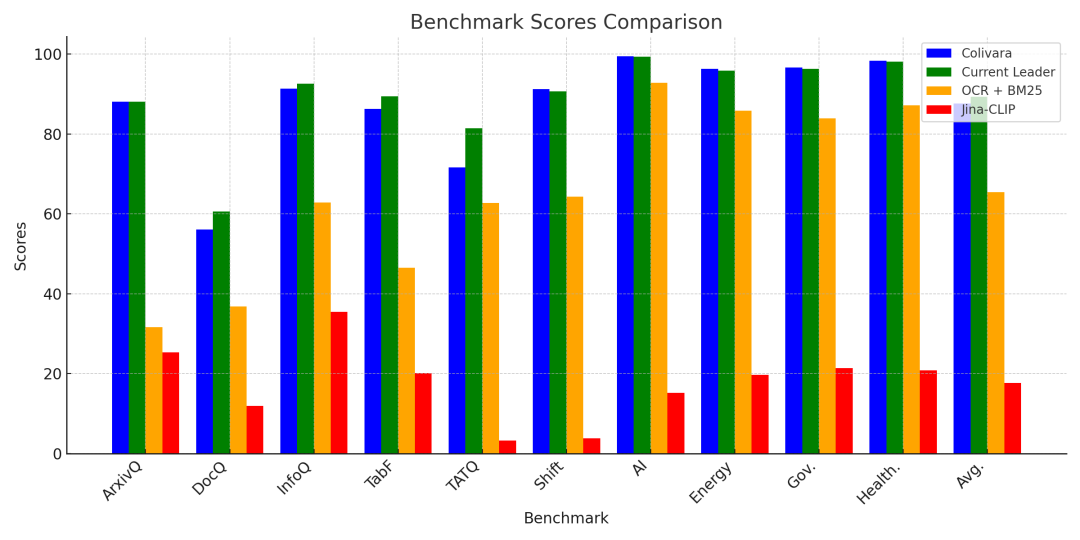
快速上手 ColiVara
上手 ColiVara 非常简单:
-
从 ColiVara 官网(或其指定渠道)获取免费 API Key。
-
安装 SDK (
pip install colivara-py或npm install colivara-ts)。 -
几行代码即可索引和搜索文档:
# Python 示例
from colivara_py import ColiVara
client = ColiVara(api_key="YOUR_API_KEY")
# 索引文档 (URL, base64 或本地路径)
client.upsert_document(
name="annual_report_2023",
document_url="https://example.com/report.pdf",
metadata={"year": 2023, "category": "finance"}
)
# 搜索
results = client.search("what were the key financial highlights of 2023?")
print(results)
本地部署方法:https://docs.colivara.com/getting-started/self-hosting
小结
在 RAG 应用成为主流的当下,如何从原始文档中高效、准确地提取高质量 Context,已经成为决定应用成败的关键。
传统的解析、分块、嵌入的分阶段过程,带来的是每一个阶段的信息损失,ColiVara的方案让文档处理更加简单和完整,它的新颖思路会给更多人启发,也将趋势更多人在这一新的技术方向探索。
github地址:https://github.com/tjmlabs/ColiVara
参考:
ColPali 论文: https://arxiv.org/abs/2407.01449
(文:AI工程化)