
小红书hi lab首次开源文本大模型,训练资源不到Qwen2.5 72B 的四分之一

小红书 hi lab 发布开源文本大模型 dots.llm1,参数量为 1420亿(142B),上下文长度32K。采用轻量级数据处理流程和MoE架构训练,相比Qwen2.5-72B在预训练阶段仅需13万GPU小时。支持多轮对话、知识理解与问答等任务,在多个测试中表现突出。
小红书 hi lab 发布开源文本大模型 dots.llm1,参数量为 1420亿(142B),上下文长度32K。采用轻量级数据处理流程和MoE架构训练,相比Qwen2.5-72B在预训练阶段仅需13万GPU小时。支持多轮对话、知识理解与问答等任务,在多个测试中表现突出。

微软宣布VS Code即将成为一个开源AI代码编辑器,并将GitHub Copilot Chat扩展代码开源。此举旨在增强VS Code的可扩展性,让其他开发者能集成复杂的AI功能。
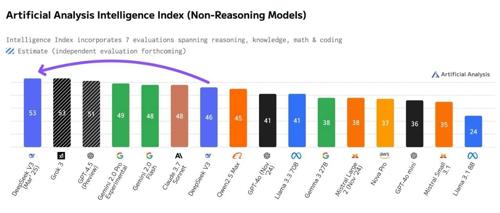
DeepSeek V3-0324 成为首个领先的开源非推理模型,领先于包括 DeepSeek R1 在内的所有专有非推理和推理模型。

DeepSeek团队发布创新型多模态框架Janus-Pro,支持384×384图像输入,表现超越现有统一模型,在GenEval和DPG-Bench测试中胜过DALL-E 3和Stable Diffusion。

DeepSeek应用登顶苹果中国和美国地区应用商店免费APP下载排行榜,成为首个在美区超越ChatGPT并登上榜首的中国企业研发大模型产品。其特性包括低成本、开源及高性能等,展示了技术民主化与用户信任的重要性。
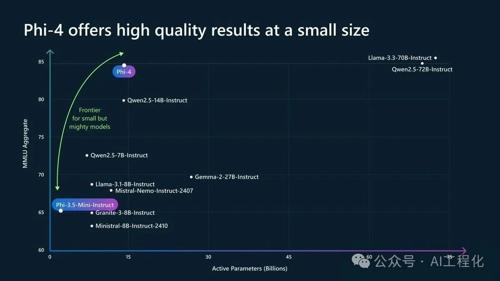
微软开源 phi-4 模型,仅 14B 参数但性能媲美 GPT-4;Huggingface、Ollama 等已同步支持使用;技术报告和量化版本信息提供。

