


6 月 6 日,小红书 hi lab(Humane Intelligence Lab,人文智能实验室)团队首次开源了文本大模型 dots.llm1,采用 MIT 许可证。
模型地址:
https://huggingface.co/rednote-hilab
https://github.com/rednote-hilab/dots.llm1
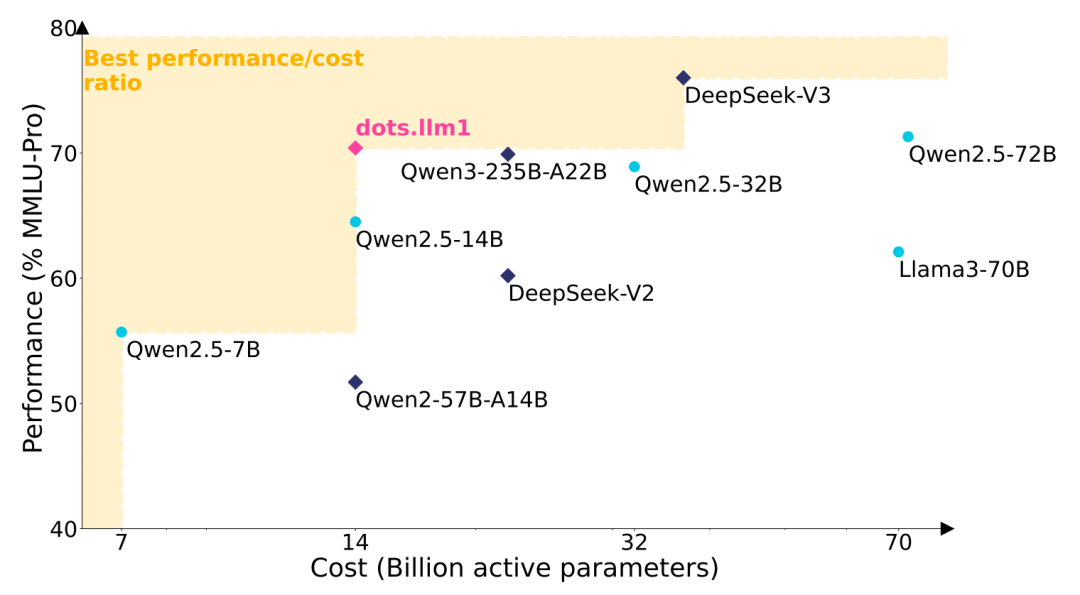
据介绍,dots.llm1 是一个中等规模的文本 MoE 大模型,其激活参数量为 140 亿(14B),总参数量达 1420 亿(142B),上下文长度 32K。通过高效数据处理流程,该模型在预训练阶段仅使用 11.2 万亿(11.2T)高质量真实数据(未采用合成数据)即达到与 Qwen2.5-72B 相当的性能水平。每训练一万亿个 token 后开放中间 checkpoint,用于理解大语言模型的学习动态。
dots.llm1 模型采用了 decoder-only 的 Transformer 架构,每一层都包含一个注意力层和前馈网络(FFN)。与 Llama 或 Qwen 等密集型模型不同,FFN 被替换为 MoE 模块。这种修改使其能够在保持经济成本的同时训练出能力强大的模型。
预训练数据的质量、数量和多样性对于语言模型的性能至关重要。hi lab 采用了三阶段方法:文档准备、基于规则的处理和基于模型的处理,以确保数据的高质量和多样性。
数据处理方面,hi lab 开发了一种轻量级的网页清理模型,以解决网页内容中的杂乱问题,如样板内容和重复性。此外,还训练了一个 200 个类别的 classifier 来平衡网络数据中的比例,增加知识性和事实性内容的比重,例如百科条目和科普文章,同时减少虚构类和高度结构化的网页内容的比例,包括科幻小说和产品描述等。
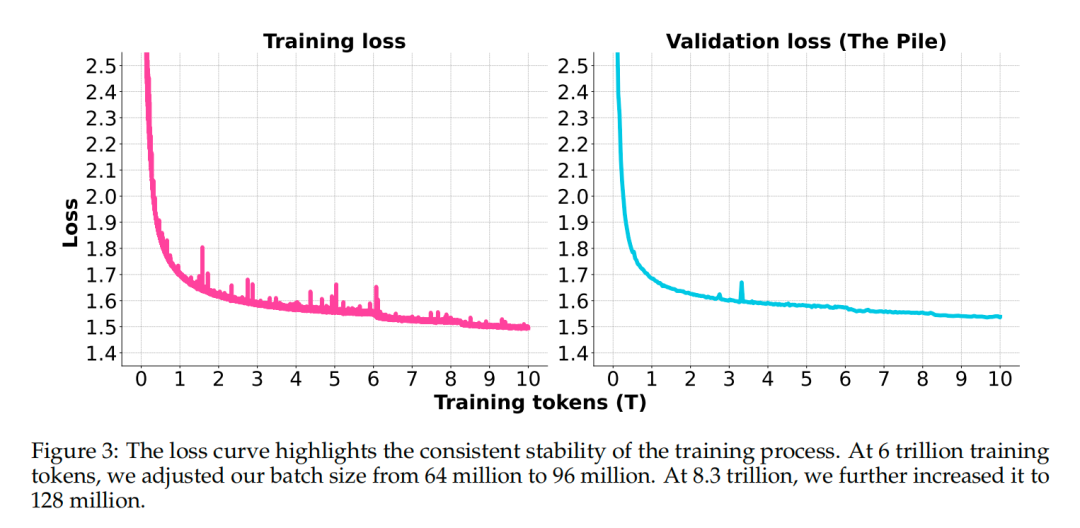
dots.llm1 使用 AdamW 优化器进行训练,采用 warmup-stable-decay 学习率计划。在预训练过程中,逐步增加批量大小,并在训练后期进行两个退火阶段,以调整学习率并增加特定数据类型的比重。
退火阶段后,hi lab 使用 UtK 策略在 1280 亿 tokens 上进行训练,将上下文长度扩展至 32K。与直接修改数据集不同,UtK 通过将训练文档切分为更小的片段,并打乱顺序后训练模型重构相关片段。通过学习如何“解开”这些打乱的片段,模型不仅能够有效处理更长的输入序列,同时也维持了在短上下文任务上的表现。
dots.llm1 的训练基于内部的 Cybertron 框架,该框架是建立在 Megatron-Core 之上的轻量级训练框架。hi lab 利用 Megatron-Core,为模型的预训练和后训练构建了一整套工具包。对于预训练、监督式微调(SFT)和强化学习(RL)等不同的训练阶段,hi lab 封装了独立的训练器,以确保训练过程的连贯性和高效率。
期间,hi lab 提出了一种基于 1F1B 的交错式通信和计算重叠方案,并与英伟达合作将其集成到 Megatron-Core 中。在稳态 1F1B 阶段,通过有效重叠前向和后向步骤对中的通信和计算,该方法在内存消耗方面展现了显著优势。同时,hi lab 团队还优化了 Grouped GEMM 的实现。
在其优化框架下,Qwen2.5 72B 训练每万亿 tokens 所需的 GPU 小时数为 34 万 GPU 小时,而 dots.llm1 仅需 13 万 GPU 小时。若考虑整个预训练过程,dots.llm1 共需 146 万 GPU 小时,而 Qwen2.5 72B 则消耗 612 万 GPU 小时,计算资源是 dots.llm1 的 4 倍。这一显著差距证明了 dots.llm1 的成本效益和可扩展性,使其成为大规模预训练更经济的选择。
在后训练阶段,hi lab 收集了约 40 万个指令调优实例,重点关注多语言(主要是中文和英语)多轮对话、知识理解和问答、复杂指令遵循以及数学和编码推理任务。
dots.llm1.inst 的微调过程分为两个阶段:
-
第一阶段,对这 40 万条指令样本进行重采样与多轮对话拼接处理,然后对模型进行 2 个 epoch 的微调。
-
第二阶段,通过拒绝采样微调(RFT)进一步增强模型在特定领域(如数学和编程)中的能力,并引入验证器系统以提升在这些专精任务中的表现。
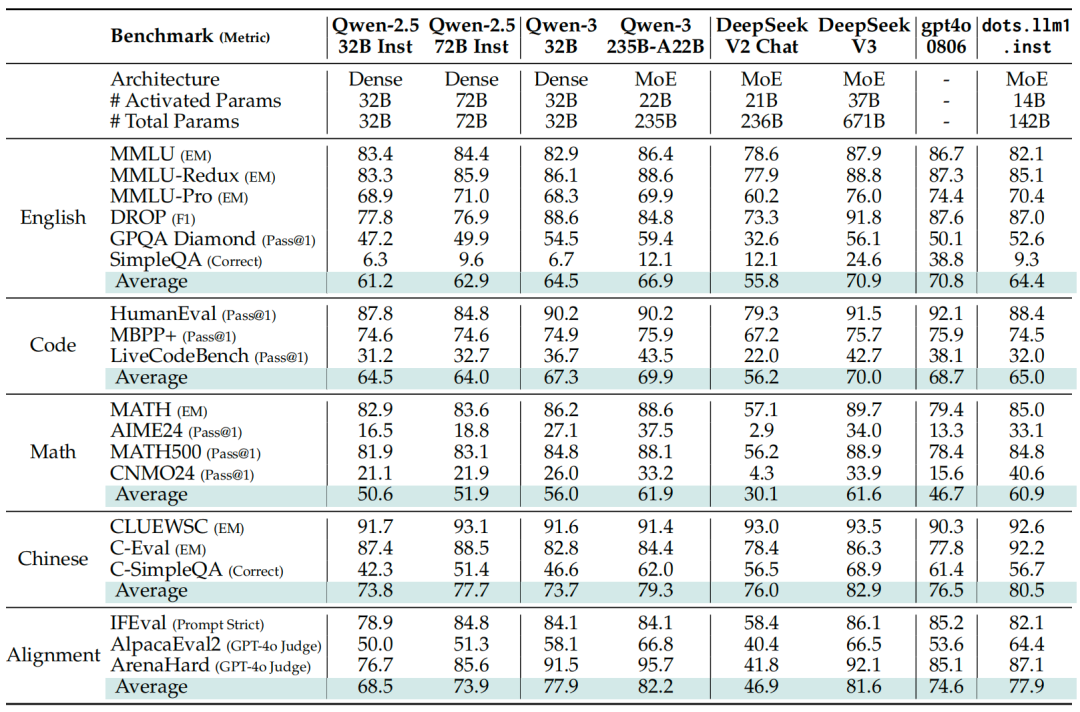
hi lab 对 dots.llm1 进行了系列测评,其在多个通用英文基准测试中表现稳定且全面。在问答类任务中,dots.llm1.inst 与 Qwen2.5 / Qwen3 系列模型相比具有竞争力。
中文任务中,dots.llm1.inst 表现出显著优势。在 CLUEWSC 语义理解测试中得分 92.6,达到了行业领先水平;在 C-Eval 上取得 92.2 分,超越了包括 DeepSeek-V3 在内的所有模型;数学能力上,dots.llm1.inst 在 MATH500 数据集上得分 84.8,超越了 Qwen2.5 系列,接近当前最先进的水平;代码能力方面, 与 Qwen2.5 系列相比,能力相当;但与更先进的模型如 Qwen3 和 DeepSeek-V3 相比,仍有一定提升空间。
据悉,小红书 hi lab 是在今年年初,由原来内部的大模型技术与应用产品团队升级组成。
与此同时,小红书开始组建“AI 人文训练师”团队,邀请有深厚人文背景的研究者与 AI 领域的算法工程师、科学家共同完成对 AI 的后训练,以训练 AI 具有更好的人文素养以及表现上的一致性。“AI 人文训练师”团队也隶属于 hi lab。
小红书称,hi lab 希望通过创造更多样的智能形式——包括人际智能、空间智能、音乐智能等,进一步拓展人工智能和人机交互的边界。筹建“AI 人文训练师”的最终目标是“让 AI 成为人类自然且有益的伙伴”。
后续我将通过微信视频号,以视频的形式持续更新技术话题、未来发展趋势、创业经验、商业踩坑教训等精彩内容,和大家一同成长,开启知识交流之旅欢迎扫码关注我的微信视频号~

今日荐文
天塌了,Claude 全面断供Windsurf!CEO喊冤控诉也挡不住开发者退订,祸起OpenAI收购?
0粉丝狂卷数十亿播放,靠AI流量欺诈获利近亿!网友:这“刑”得离谱
被高薪吸引却遭愚弄!科学家怒曝AI科研黑幕:多为个人“捞金”,DeepMind百万成果是“垃圾”
新存1000万,为客户子女提供实习机会?字节等回应;宇树更名,王兴兴曾称或赴港上市;韦神新成果正式命名“韦东奕定律” | AI周报
Redis 之父:哪怕被喷我也得说,AI 远远落后于人类程序员!开发者跟评:用大模型气得我自己写代码都有劲儿了

你也「在看」吗?👇
(文:AI前线)