辛顿上海演讲全文

MLNLP社区致力于推动国内外机器学习与自然语言处理领域的交流合作。作为知名社区,其愿景是促进学术界、产业界和爱好者之间的进步。近日WAIC大会上,Geoffrey Hinton发表了开幕演讲,讨论了数字智能与生物智能的关系,并分享了他早期模型如何结合两种理论的观点。该文章还提到了大模型的发展以及它们在语言理解方面的应用,强调了人类理解和AI系统之间的一些相似之处。最后讨论了全球合作对于解决AI安全问题的重要性。
MLNLP社区致力于推动国内外机器学习与自然语言处理领域的交流合作。作为知名社区,其愿景是促进学术界、产业界和爱好者之间的进步。近日WAIC大会上,Geoffrey Hinton发表了开幕演讲,讨论了数字智能与生物智能的关系,并分享了他早期模型如何结合两种理论的观点。该文章还提到了大模型的发展以及它们在语言理解方面的应用,强调了人类理解和AI系统之间的一些相似之处。最后讨论了全球合作对于解决AI安全问题的重要性。

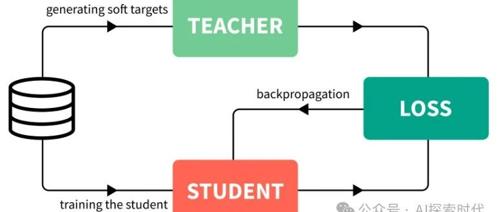
本文研究知识蒸馏中FKLD和RKLD的次优表现,提出α-β散度框架ABKD来平衡难度集中与置信集中效应。通过实验验证了ABKD的有效性,并提出了敏感性分析以进一步优化模型性能。

谷歌Gemini 2.5 Pro在模型训练和推理优化方面取得突破,Vlad Feinberg揭秘其核心技术。通过经典扩展定律、推理优化扩展定律以及知识蒸馏技术,谷歌找到了最优解,在资源有限的情况下实现了性能提升。

MLNLP社区是国内外知名的人工智能社区,致力于促进学术交流。该领域内的三篇论文讨论了强化学习在大模型训练中的作用,并指出模型的推理能力大部分已在预训练阶段形成,RL更多起到优化选择路径的作用。
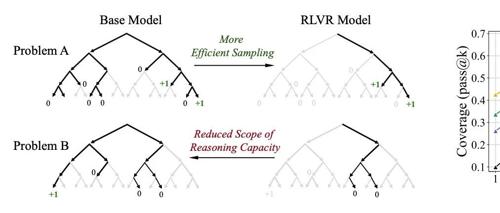
清华大学研究指出,强化学习虽能提升大模型在特定任务上的表现,但可能并未拓展其整体推理能力边界。研究通过pass@k评估发现基础模型在高尝试机会下也能追上甚至超越经过强化学习训练的模型。这表明当前RL技术主要提升的是采样效率而非新解法生成。
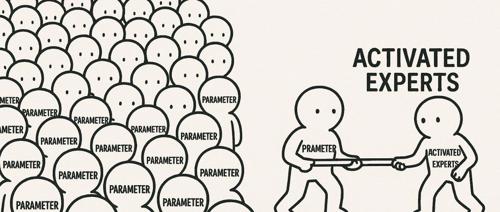
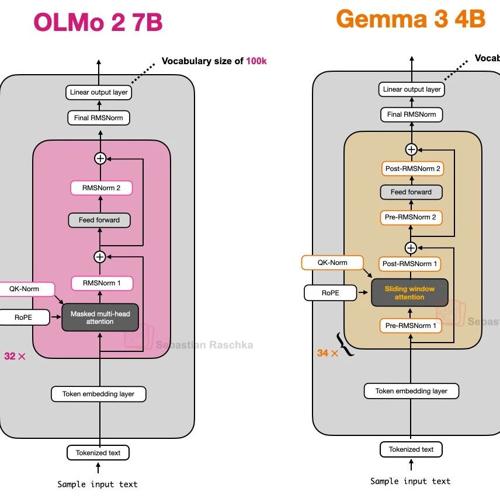
文章介绍了Gemma-3和DeepSeek V3在参数量上的对比,并指出模型效果不仅仅取决于参数大小。通过详细解释Dense和MoE架构的区别及其实际应用效果,强调了参数数量并不能直接反映模型性能优劣的观点。同时讨论了知识蒸馏技术如何让小模型继承大模型的能力,而不仅仅是关注模型的规模大小。

OpenAI的o1和DeepSeek的R1模型在复杂领域达到人类专家水平,AlphaDrive提出一种强化学习和推理训练框架用于自动驾驶规划,显著提升规划准确率并降低成本。