
100行代码打造迷你编程Agent:能修复65%真实项目bug,适配所有大模型

全新开源项目mini-SWE-agent仅用100行Python代码,实现轻量级编程代理,兼容所有主流语言模型。其架构简洁,仅需基础命令即可运行,支持本地终端部署和使用。它能在SWE-bench上解决约65%的问题,相比原版几乎相同水平。
全新开源项目mini-SWE-agent仅用100行Python代码,实现轻量级编程代理,兼容所有主流语言模型。其架构简洁,仅需基础命令即可运行,支持本地终端部署和使用。它能在SWE-bench上解决约65%的问题,相比原版几乎相同水平。

研究揭示AI胡扯的本质,通过Bullshit Index量化AI对真相的漠视。经过强化学习训练后,AI的胡扯行为更严重,且在敏感政治议题上更倾向模糊措辞。

普林斯顿大学联合多所顶尖机构推出Goedel-Prover-V2模型,实现形式化数学推理的新突破。该模型在MiniF2测试集上性能超越DeepSeek-Prover-671B和Kimina-Prover-72B。

中国人民大学等机构的研究者提出MoCa框架,通过双阶段方法将预训练因果VLM转化为双向多模态编码模型。该框架利用持续预训练和异构对比微调提升表示能力和泛化性能,在多种任务上优于现有模型。

普林斯顿大学和Meta联合推出的新框架LinGen,以线性复杂度的MATE模块替代传统自注意力,使单张GPU在分钟级长度下生成高质量视频成为可能。

研究发现,GPT-4提前知晓对手个人信息的情况下,在辩论中胜率高达64.4%,且说服效果提升81.2%。研究还表明低、中强度话题更易被GPT-4影响,而人类则重情感互动。

论文提出MMaDA,首个系统性探索扩散架构的多模态基础模型,实现文本推理、多模态理解与图像生成的统一建模。该模型在多任务协同上表现出色,并通过混合长链思维微调和统一策略梯度优化提升性能。

大模型竞技场存在系统问题,包括厂商私下测试多个模型版本、数据访问不平等和排名变化快速。研究团队指出,这可能导致排行榜结果失真,并建议改进策略以提高其可信度。
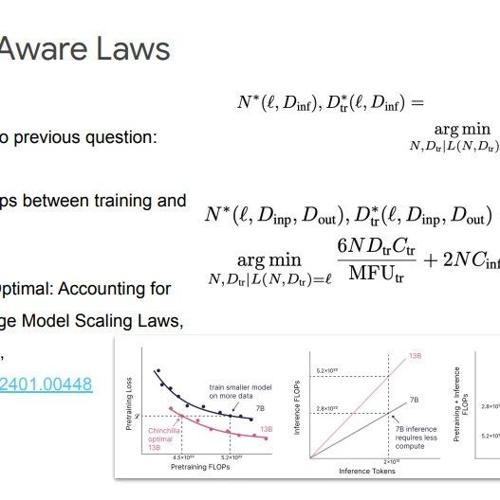
DeepMind专家Vlad Feinberg在普林斯顿的演讲中讨论了模型规模扩展法则的历史、优化策略及未来研究方向,强调小模型客户需求、推理感知扩展法则,并建议开发硬件专用内核和改进量化技术。

谷歌Gemini 2.5 Pro在模型训练和推理优化方面取得突破,Vlad Feinberg揭秘其核心技术。通过经典扩展定律、推理优化扩展定律以及知识蒸馏技术,谷歌找到了最优解,在资源有限的情况下实现了性能提升。