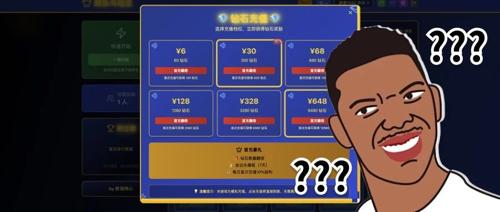
无账号&特殊网络,如何畅跑 Claude Code|附智谱「特别折扣」
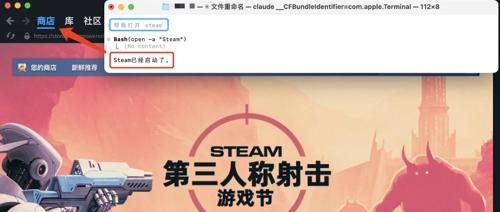
一份简明教程介绍如何在无账号前提下使用Claude Code,通过特定命令行操作实现低成本畅用。详细说明了替代方法和配置步骤,涵盖关键的API访问、资源包购买与套餐选择等内容。
一份简明教程介绍如何在无账号前提下使用Claude Code,通过特定命令行操作实现低成本畅用。详细说明了替代方法和配置步骤,涵盖关键的API访问、资源包购买与套餐选择等内容。

凌晨一点,OpenAI 发布了最强模型 GPT-5,用户可通过 ChatGPT 直接使用,API 用户可访问多种模型,价格低于 GPT-4.1。GPT-5 有多个版本供选择。

Coze 开源后迅速获得5k Star。本文详细介绍了无痛部署教程,包括安装Docker、下载并配置Coze Studio等步骤。此外还分享了如何更换模型和插件的方法。
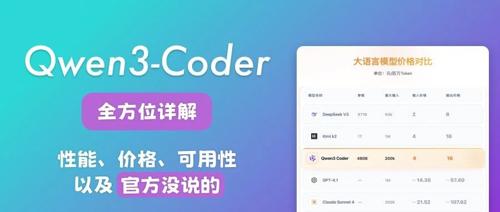
今天凌晨Qwen3-Coder发布最强代码模型,采用MoE架构,开源480B大小。性能上胜过Claude Sonnet4,价格图表对比明确,API及开发方式详述,还有自部署、CLI工具和调用示例等全面信息。

OpenAI 发布了 ChatGPT Agent:一个可以连接到各种 API 并执行复杂任务的新智能体。它能生成报告、设计贴纸,并通过多个基准测试超过了人类专家的表现。

马斯克发布Grok4推理模型,订阅需$30/月。Grok 4进化速度远超人类,在SAT、GRE等考试中表现优异。展示了包括‘人类最终考试’在内的多个测试结果和实际应用能力演示,未来还将推出多种新产品线。