

基于声音的尿流测定是一种新兴的非侵入性检测方法,作为标准尿流测定的替代方案,通过分析尿液冲击马桶中水时产生的声音来估算排尿特征。目前,缺乏标记过的尿流声音数据集限制了用于开发监督式人工智能算法的研究。本研究提供了一个模拟尿流声音记录的数据集,涵盖了从 1 到 50 毫升/秒(以 1 毫升/秒为增量)的流速,这些声音是在真实的马桶中记录的。尿流的产生采用了 L600-1F 精密蠕动泵,同时使用三种设备进行记录:高质量的 Ultramic384k 麦克风、小米 A1 智能手机和 Oppo 智能手表。尿液通过一个直径为 6 毫米的喷嘴(模拟尿道)排出,高度从 73 厘米到 86 厘米不等,模拟成人排尿。该数据集提供了 60 秒的标记过的恒定流速音频记录(WAV 格式)。这一资源旨在通过开发和验证监督式人工智能算法,支持基于声音的尿流估计研究。
背景与概述
人工智能(AI)的快速发展正在变革医疗保健系统,推动其向更加主动和远程的方向发展,这有望在多个层面上重新定义医疗保健。这一技术进步使医疗服务提供者能够通过基于海量且实时健康数据的预测分析来提前预测疾病,显著提高病理的早期检测、治疗的个性化以及慢性病的管理能力。同时,对于患者而言,AI 系统使得获取医疗保健更加便捷和连续,消除了距离的障碍,并通过远程监测和自动提醒提高了治疗的依从性。
从 AI 中显著受益的一项医学检测是基于声音的尿流测定(SU)。这种创新技术旨在通过分析尿液冲击马桶中水面时产生的声音来估算膀胱排空期间的尿流模式。SU 作为一种远程和主动的替代方案,应运而生,以替代尿流测定(UF),这是一种由泌尿科医生进行的标准临床检测,用于检测与泌尿系统症状(LUTS)相关的问题,如阻塞或排尿功能障碍。

尽管 UF 有效,但它是在临床环境中进行的,患者需要在尿流计中排尿,该设备测量尿流率、排尿量以及排尿过程中涉及的时间等关键参数。然而,UF 的有效性可能会受到环境因素的影响,例如患者在不熟悉或不自然的环境中接受检测时可能经历的压力或不适,可能会改变他们正常的排尿模式。此外,仅一次尿流测定测试可能无法充分代表患者通常的排尿方式。因此,SU 提高了患者的依从性,允许基于家庭的干预,并减少了结果的变异性,增加了测试次数。
开发与 SU 相关的基于 AI 的研究的主要挑战在于缺乏带有标记的公开数据集。这一问题对研究人员构成了重大挑战,并限制了相关临床应用的发展。目前,文献中有许多研究涉及 SU 中的流参数估计,但大多数研究人员独立创建自己的数据库,导致实验设计、使用的录音设备、流参数以及受试者的特征方面存在显著差异。这种缺乏标准化的情况使得研究难以比较,阻碍了实验的可重复性,并在应用于 SU 的基于 AI 的算法中造成了不一致性。此外,这些数据集并不公开。
在不同研究中使用的录音设备种类繁多,包括智能手机、专用麦克风和智能手表,它们产生的声音数据具有非常不同的特征,进一步扩大了技术发展与临床应用之间的差距。录音和数据处理协议的异质性限制了开发能够在各种临床条件下验证的稳健且可泛化的算法的能力。

标记数据集的可用性对于训练能够准确预测尿流并更早检测病理状况的 AI 模型至关重要。此外,结合这些基于 AI 的模型的 SU 可用于创建数字排尿日记,该日记在一天中的不同时间和夜间测量多次尿流,这可能对确定任何病理状况更加有用和客观。如果没有经过良好整理的公开数据集,创建能够应用于不同设备和临床场景的模型的可能性就会受到损害,限制了 SU 作为一种易于获取且可靠的诊断工具的潜在影响。创建一个标准化的、公开的、多设备数据集,即使是基于合成流的,也可能是将这项技术民主化并有效地整合到临床实践中的关键一步。
在这项工作中,研究团队承担了创建一个从 1 到 50 毫升/秒(以 1 毫升/秒为增量)的合成流数据集的任务,这些流是针对真实马桶中的水,使用 L600-1F 精密蠕动泵,并用三种设备进行录音:高质量的 Ultramic384k 麦克风、小米 A1 智能手机和 Oppo 智能手表。水通过一个 6 毫米直径的喷嘴排出,该喷嘴模拟成年男性的平均外尿道口,从 73-86 厘米的可变高度排出。这个干净的数据集,除了模拟尿液冲击真实马桶中的水的声音外,没有其他声音,可以作为在真实环境中模拟排尿的基础,在添加背景噪音之前训练基于 AI 的模型。在接下来的部分中,研究团队将详细分析生成数据所使用的步骤和方法。
方法
流生成设备
为了生成数据集,研究团队使用了一款 L600-1F 精密蠕动泵,其能够根据所使用的泵头和管径,在 0.16 微升/分钟至 3000 毫升/分钟(2.67 纳升/秒至 50 毫升/秒)的范围内产生流速。对于研究团队的应用,目标是生成 1 至 50 毫升/秒之间的流速,因为这是国际尿控协会(ICS)在尿流测定测试中观察到的流速范围,对应于 60 毫升/分钟至 3000 毫升/分钟的流速。在研究团队的案例中,使用了 YZII25 泵头和 9.5 毫米内径×2.4 毫米壁厚的生物硅胶管(型号 #36),其覆盖的流速范围为 160 微升/分钟至 3000 毫升/分钟(见图 1)。生物硅胶管的长度为 15 米,研究团队利用这一长度将蠕动泵放置在卫生间外的另一个房间,以隔离录音环境,避免泵产生的噪音干扰。研究团队需要使用量筒对泵进行校准,以确保蠕动泵提供的流速值,这将在第 3 部分中展示,验证流速的准确性。

图 1:精密实验室蠕动泵(L600-1F)0.16 微升/分钟 – 3000 毫升/分钟:(a)侧视图和(b)正视图。
表 1 显示了制造商为 L600-1F 泵型号提供的规格。
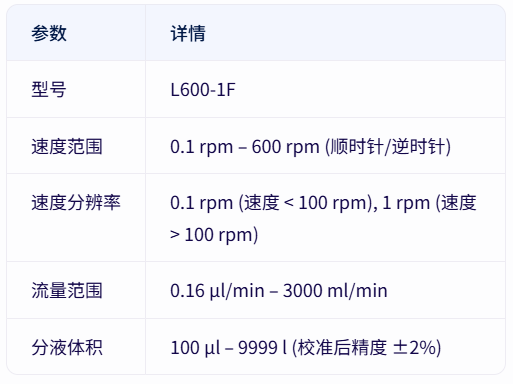
表 1 L600-1F 泵型号规格表
音频录音设备
基于先前基于声音的尿流测定(SU)研究中报告的多样化录音设备,研究团队选择了三种代表性类型,以反映常见实践并支持方法的一致性。由于智能手机的普及性、内置麦克风以及易于使用的特点,它们被广泛用于此类研究。专用麦克风则用于需要高保真度或注重隐私的声音数据的研究。而智能手表则能够实现免提、固定在身体上的录音,并且越来越多地被用于长期的家庭监测。特别是,研究团队数据集中使用的智能手表型号的选择得到了文献 [13] 中的比较评估的支持,该评估评估了多种智能手表设备,并证明了 Oppo 智能手表因其录音性能和适用于非侵入性 SU 测试的特点而被选用。

因此,研究团队的数据集包括了每种类别(智能手机、智能手表和专业麦克风)的一个代表性设备。这一选择旨在捕捉广泛的现实声音场景,同时支持可重复性和跨设备算法开发。所选设备如上图所示,具体描述如下:
-
Ultramic384K(UM):一款高质量的外部 USB 麦克风(Dodotronic 的 Ultramic384k),采用 Knowles FG23629 MEMS 传感器。它能够实现最高 384 千赫兹的采样率(SR),从而可以详细分析广泛的频率范围。在研究团队的测试中,使用了 192 千赫兹的采样率,足以分析高达 96 千赫兹的频率,同时尽量减少数据量。麦克风连接到笔记本电脑,通过带有预设参数的自定义 Python 脚本触发录音。
-
Mi A1 智能手机(Phone):一款小米 Mi A1 智能手机,配备有集成的 Knowles SPU0410LR5H-QB MEMS 麦克风,这种麦克风通常用于移动消费设备。该麦克风以 48 千赫兹的采样率运行,能够捕捉高达 24 千赫兹的频率。由于其易于获取、内置麦克风以及软件集成的便利性,智能手机已在先前的 SU 研究中得到了广泛使用。在研究团队的设置中,录音通过带有固定参数的自定义 Android 应用程序进行管理。
-
Oppo 智能手表(Watch):一款 Oppo 智能手表,内置中等质量的麦克风(具体芯片组未公开披露),在先前的 SU 研究中经过验证。该手表以 44.1 千赫兹的采样率录制音频,因其在排尿过程中的实用性而被选中,它在手腕上提供了一个固定的录音位置,且不会干扰排尿动作。录音通过配套的 Android 移动应用程序启动。
实验设置
图 3 展示了在卫生间进行流速录音测试时录音设备的位置。UM、Phone 和 Watch 距离地面的高度分别为 84 厘米、95 厘米和 86 厘米。UM 和 Phone 的高度和位置的选择标准是基于马桶水箱的平均位置和高度。对于 Watch,其位置和高度模拟了一个人自然垂臂站立时手腕的平均高度。

图 3:录音阶段:(a)正视图和(b)俯视图。
为了确保尿流在所有流速条件下都能一致地冲击马桶中的水面,喷嘴高度根据流速强度在 73 厘米到 86 厘米之间进行调整。在较低流速下,需要更水平的射流轨迹,因此出口管的倾斜角度也相应进行了调整。这些变化保持在现实的解剖学范围内,预计不会显著影响记录声音的声学特性。
数据采集
研究团队的目标是为每个录音设备获取持续时间为 60 秒的标记过的恒定流速音频样本。数据是在控制条件下收集的,以尽量减少背景噪音和外部干扰。蠕动泵被编程为从 1 到 50 毫升/秒(以 1 毫升/秒为增量)的每个流速,持续时间为 90 秒。一旦泵被激活(图 4,步骤 1:泵工作),每个麦克风的录音过程就开始了,激活 UM、Phone 和 Watch。录音开始过程如下:对于 UM,在笔记本电脑键盘上按下“Enter”键;对于 Phone 和 Watch,在它们各自的基于 Android 的移动应用程序中按下触摸按钮。所有设备在启动后都被配置为录制 80 秒(图 4,步骤 2:设备录音)。不同流速音频的录音文件名格式如下:“[设备]f[流速].wav”(其中设备是 UM、Phone 或 Watch,流速是 1 到 50 毫升/秒之间的流速)。一旦为每个设备获取了带有相应流速标签的所有音频文件,它们就被修剪为 60 秒的纯排尿声音及其对应的流速。为此,研究团队修剪了每个音频的前 15 秒,以去除与录音开始相关的初始噪音,以及最后 5 秒,最终获得了标记过的 60 秒音频文件(图 4,步骤 3:干净的音频)。图 4 展示了从步骤 1 到步骤 3 获取数据集音频录音的流程图。修剪后的音频“[设备]f[流速]_[时长]s.wav”,其中在时长标签下添加了音频中的秒数。图 5 展示了音频采集过程的流程图。

图 4:流程图
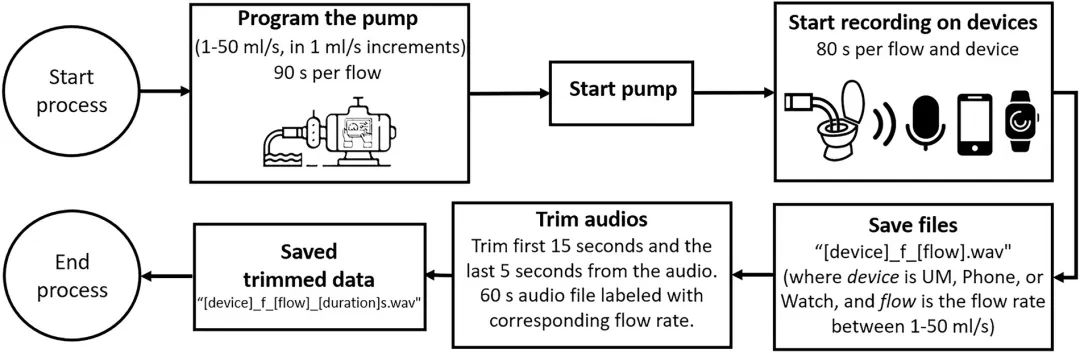
图 5:描述音频采集过程的流程图
研究团队还在记录所有流速数据的同一环境中,为三种设备分别录制了 30 秒的完全静音音频,并将其标记为流速值为 0。
数据记录
-
本文描述的音频数据集已存放在 Figshare 仓库中,并按以下方式组织:
-
三个文件夹分别命名为 Ultramic_1min、Phone_1min 和 Oppo_1min,分别对应录音设备 UM、Phone 和 Watch。
-
每个文件夹内包含 51 个 WAV 格式的音频文件,分别对应每个流速(1-50 毫升/秒,以 1 毫升/秒为增量),以及一个额外的文件,代表 30 秒的静音。
-
每个文件都包含指定流速、录音设备、采样率(SR)和持续时间(以秒为单位)的元数据,作为监督学习任务的注释。除了这些流速标签外,没有应用其他注释或手动分类。
技术验证
为了验证数据集的质量,研究团队进行了多次试验,以确保录音的一致性。蠕动泵提供的流速验证是使用一个 1000 毫升体积、精度为 ±10 毫升的量筒进行的(见图 6)。获得的结果如表 2 所示。它包含了编程流速、编程运行时间、预期体积(毫升)以及泵实际排出的体积。

图 6:蠕动泵的流速验证场景:(a,b)校准测试设置和(c)量筒
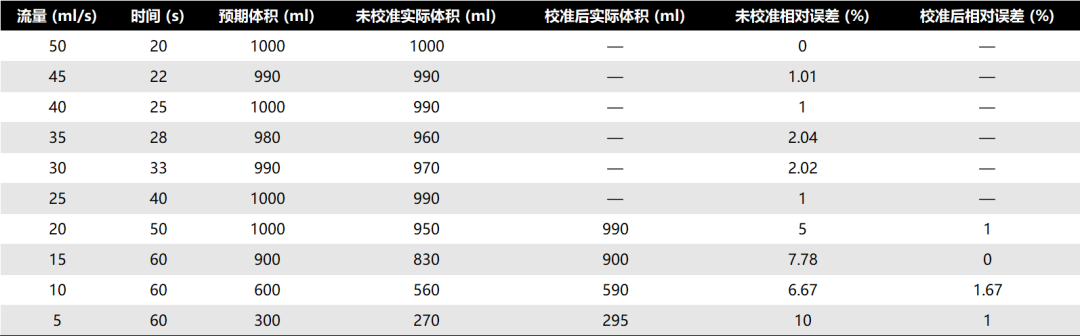
表 2:蠕动泵的验证,包括时间(秒)、预期体积和实际排出体积。
验证结果确认,蠕动泵在大多数编程流速下具有很高的准确性,预期体积和实际排出体积之间的差异很小。对于较高的流速,如 50 毫升/秒到 25 毫升/秒,相对误差百分比相当低,保持在 2.1% 以下。然而,对于较低的流速,特别是 20 毫升/秒到 5 毫升/秒之间,相对误差显著增加,达到 10%。这些偏差可以归因于使用了 15 米长的软管,因为较小的压力损失和内部摩擦对降低流速的影响更大。在较高的流速下,泵能够更好地补偿这些损失,保持更稳定的流速。
为了减少低流速相关的误差,研究团队对 5 到 20 毫升/秒(以 5 毫升/秒为增量)的低流速进行了泵的校准。表 2 显示了 5 到 20 毫升/秒的实际校准体积及其对应的校准绝对误差的结果。总之,结果是一致的,适合本研究的目的,为创建标记准确的流速数据集提供了坚实的基础。
使用 UM 麦克风提供了高分辨率的声音数据,而 Phone 和 Watch 的录音则代表了更易于获取的替代方案,这些方案在实际应用中可能更常见。
使用说明
研究人员可以使用这个数据集来开发和评估基于声音录音估算尿流速的基于人工智能的模型。可能的应用包括训练回归模型,以从声音特征(例如,梅尔频率倒谱系数(MFCC))预测连续的流速,或者训练分类模型,将流速轮廓分类为具有临床相关性的组别(例如,低、正常、高)。录音的标记结构支持监督学习、模型验证和可重复的基准测试。
为了支持数据集的可重复性和实际应用,数据集仓库中提供了一个与 Google Colab 兼容的示例 Python 笔记本(sound_dataset_processing.ipynb)。该脚本实现了推荐的预处理步骤,包括添加背景噪音以模拟真实环境、通过高通滤波进行降噪、音频分割、基于 MFCC 的特征提取、跨设备归一化以解决麦克风变异性问题以及带有 10 折交叉验证的监督建模。此外,UM 的高采样率允许在频域进行详细分析,这可能为与不同流速相关的声音特性提供更深入的见解。
需要注意的是,该数据集是在模拟站立的成年男性(手臂放松)的受控条件下创建的,其固定高度约为 85 厘米。马桶结构的变化或解剖因素(包括性别差异)以及排尿姿势(坐或站)可能会影响真实排尿事件的声音特性。研究人员在将研究结果推广到临床环境中时应考虑这些因素。
代码可用性
Python笔记本 sound_dataset_processing.ipynb 已开发用于支持数据集的预处理和建模。该笔记本可在数据集仓库中找到,并以可重复的方式展示了预处理、特征提取、跨设备归一化和监督建模。
随着AI音频技术的不断发展,在医学领域已经成为不可或缺的新力量,除了与听力有关的范畴,在各种病情的诊断与监测方面展现出巨大的潜力。
更多相关内容可见:
-
Nature:生成式 AI 与结构化音频数据用于公共卫生
-
AI 助听器每小时进行 8000 万次实时声音调整,模拟人脑功能
-
Sonos推出AI语音增强应用帮助听力障碍人士
-
AI音频技术帮助人们清晰听见,来自腾讯
-
全球首个 AI 肺音套件:TytoCare 获得 FDA 批准
(文:AI音频时代)