
小扎开9位数薪酬新建AI团队!砸千亿收购华人初创公司,Llama 4太拉胯急坏了

Meta CEO扎克伯格因Llama 4表现不佳,急召顶尖人才组建新AI实验室,并斥巨资收购初创公司Scale AI的49%股份。新实验室目标为研究“超级智能”,预计规模约50人。
Meta CEO扎克伯格因Llama 4表现不佳,急召顶尖人才组建新AI实验室,并斥巨资收购初创公司Scale AI的49%股份。新实验室目标为研究“超级智能”,预计规模约50人。

Meta 新发布的Llama 4模型在实战中表现不佳,引发了广泛质疑。尽管其在大模型竞技场上的排名不错,但在实际应用中的效果却不如人意。部分用户反馈称该模型存在多方面的问题,如生成代码、抽象推理等能力不足。为了澄清疑虑,Meta 发布了Llama 4的相关测试数据,并承认之前的宣传策略可能存在问题。

Meta针对Llama 4训练作弊的爆料迅速反击,但模型的实际表现却频频被吐槽。Ahmad Al-Dahle澄清不同平台间质量差异是因为开源行为,Yann LeCun力挺模型。尽管存在争议,Llama 4在某些测试中的表现令人失望。

Meta发布首个原生多模态Llama 4系列模型,性能超越GPT-4。包含Maverick、Scout和Behemoth三个模型,支持1000万token上下文。不过其开源模式存在争议,包括登录Hugging Face账户限制、严格再分发要求及命名要求等。
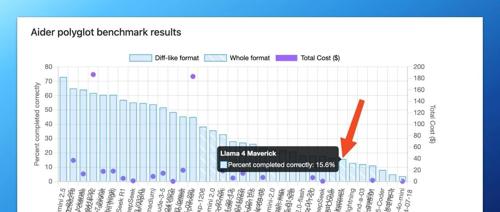
Meta 新发布的Llama 4因基准测试成绩亮眼但遭用户质疑,称其实际表现不佳。Meta 因疑似数据污染技术而受到批评。此外,Meta的Llama 4 Maverick模型在多个任务如前端开发、逻辑推理等方面的表现也不尽人意。

Meta最新基础模型Llama 4发布后遭遇差评如潮。代码能力受质疑,尤其是经典‘氛围编程’小球测试表现不佳。竞技场排名成绩参差不齐,且存在数据泄露和版权问题的疑虑。



