

大模型的 “卷”,是 “肉眼可见的卷”。
这一次是 Meta。
它甚至,破天荒的,选择了在周六这个休息日发布新模型。
面对各个强大竞争对手的“来势汹汹”,很明显,Meta 急了。
DeepSeek 在年初的强势崛起,让全球侧目,也撕下了 Meta 长期以来引以为傲的最后一块遮羞布:“最强开源模型”。

更不用提后来更加强大的闭源模型:OpenAI 的 o3、GPT-4.5;Anthropic 的 Claude 3.7 Sonnet、马斯克 xAI 的 Grok 3 以及 谷歌的 Gemini 2.5 Pro。
大模型排行榜上早已不见 Meta Llama 模型的身影。
而 Meta 旗下最顶级的模型 Llama 3.1 405B,它的发布已经是去年 7 月 23 日的事情了。
相比以往“不痛不痒”的轻量发布,这次 Meta 的动作颇有“不成功 便成仁”的意味。
三款模型,两个已发布并开源,一个预热,表面上是 Meta 给用户、市场、投资人这大半年的答卷,背后是 Meta 重夺“最强开源模型”的明确野心。
这一次,Llama 4 系列真的进入新阶段了吗?

01 三款模型,一个生态的试探
Llama 4 系列包含三个不同参数的模型。
-
Llama 4 Scout:1090 亿参数 + 170 亿活跃参数 + 16 专家,轻量级、小参数通用模型,主打长上下文 + 多模态支持。 -
Llama 4 Maverick:4000 亿参数 + 170 亿活跃参数 + 128 专家,定位旗舰通用模型,主打推理、代码、图像理解。 -
Llama 4 Behemoth:2 万亿参数 + 2880 亿活跃参数 + 16 专家,还在训练中,被 Meta 自称为“史上最强开源教师模型”。

整理成表格,方便小可爱们对比。
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|
| Llama 4 Scout |
|
|
|
|
|
|
| Llama 4 Maverick |
|
|
|
|
|
|
| Llama 4 Behemoth |
|
|
|
|
|
|
其实从 Meta 对 Llama 4 系列模型的命名上就能看出些许端倪。
Scout 是“探索者”,Maverick 是“特立独行者”,Behemoth 则是“巨兽”。
总结来看,Meta 想讲的并不只是“我们有三款模型”,而是:我们正在构建一个生态闭环。
02 Scout:参数不大,上下文很大
先说参数量最小的 Llama 4 Scout。
这个模型参数量不算吓人,170 亿活跃参数,只用 1 张 H100 就能跑起来。
但它的上下文长度,直接拉到了 1000 万 tokens。
是的,你没看错,1000万。从 Llama 3 的 128K,一步跳到 Llama 4 Scout 的 1000 万,几乎等于把“上下文窗口”这条赛道提前打穿了。
不出意外地,这是目前全世界所有 AI 模型里,上下文最长的模型,比谷歌 Gemini 的 200 万 tokens 还要强。

当然,1000 万这个数字听起来虽然炫酷,但它到底意味着什么?
简单讲,你可以直接把全套《三体》、一堆合同、十几个 PRD + 代码全部塞进 Scout 的大脑里。
这让它天然适合:
-
多文档检索 + 总结; -
超长代码库的“调试”型推理; -
高密度用户行为数据的个性化处理。
03 Maverick:对标 GPT-4o、DeepSeek-V3
Meta 给 Llama 4 Maverick 的定位很清晰,就是:面向对话场景的旗舰多模态模型。
Maverick 的技术参数和前面的 Scout 相同,也是 170 亿活跃参数,但专家数量翻了几倍,达到 128 个,总参数量 4000亿。作为对比,DeepSeek-V3 的参数量是 6710 亿,活跃参数为 370 亿。
不难看出,相比 Scout 的 “卷长”,Maverick 更强调 “卷强”。
换句话说,它不追求极限的上下文长度,而追求更高的单次推理质量和更好的图文理解。
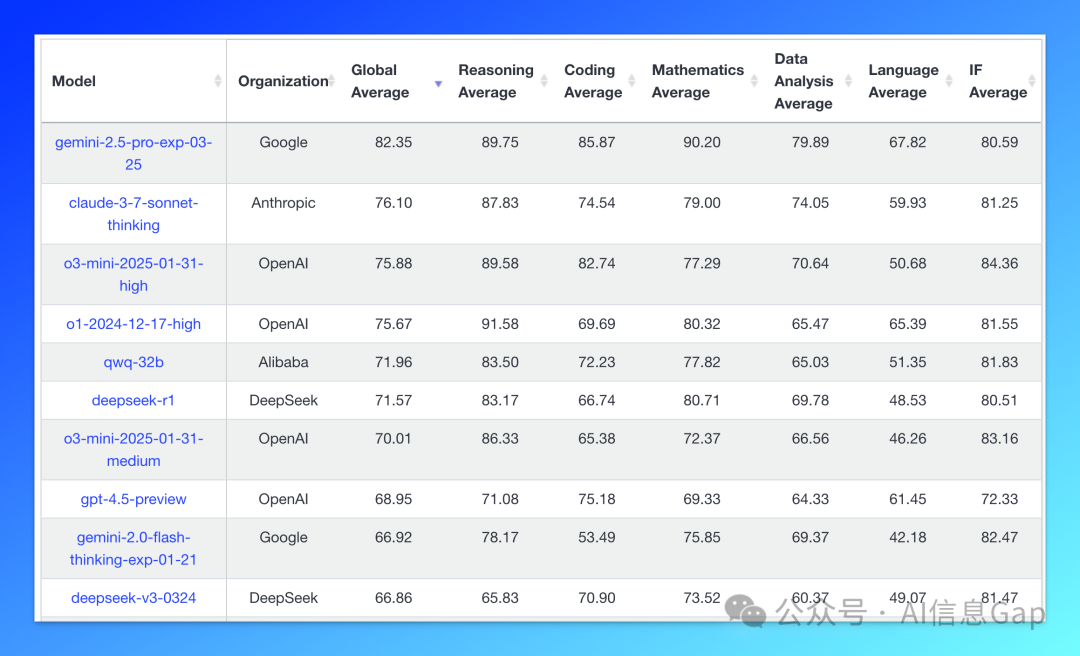
从 Meta 官方给出的 Llama 4 Maverick 模型基准测试结果来看,它无疑是第一梯队的。
以仅二分之一的活跃参数,Llama 4 Maverick 就取得了超过 DeepSeek-V3 0324 的成绩,并且,多模态上明显“更胜一筹”,因为 DeepSeek 的模型还没有支持多模态类型(如图像、文件)的输入。
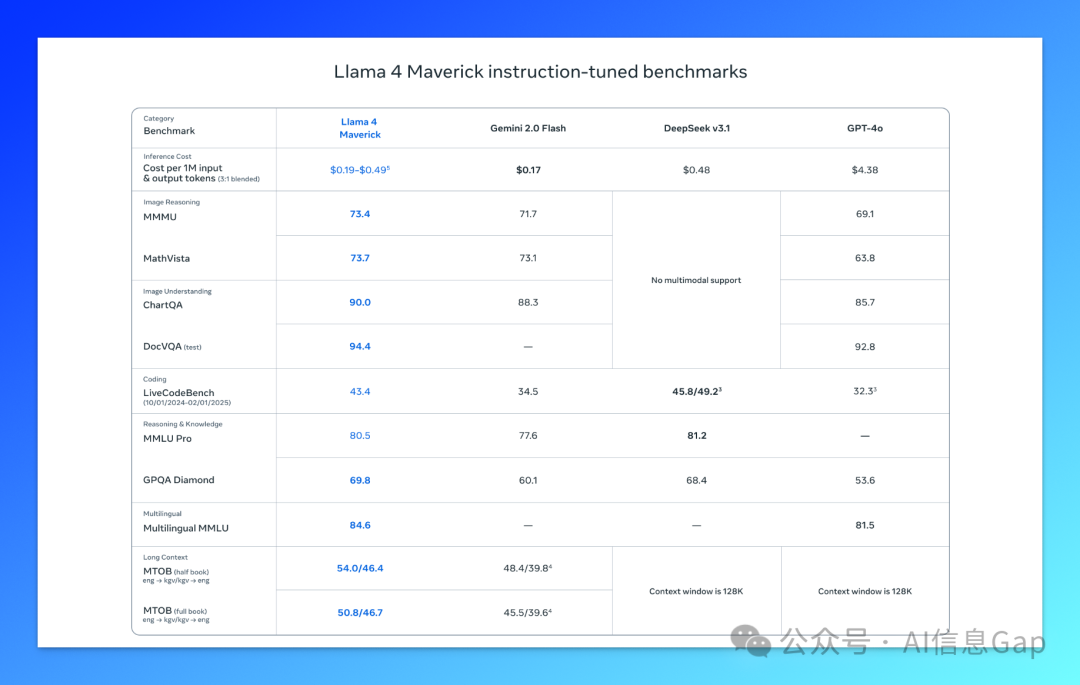
新模型发布前先上 LMSYS 大模型竞技场跑一跑分几乎成了一个必然,这次的 Llama 4 也不例外。
而在最新的 LMSYS 排行榜上,Llama 4 Maverick 刚发布就占据了第二名的宝座,仅次于谷歌的 Gemini 2.5 Pro,超越了之前的老牌强者,如 GPT-4o、Grok 3 等。
虽然 LMSYS 排行榜的打分和排名带有很强的客观性,但也能从侧面反映一些东西的。
另外,让我们期待一波 Llama 4 在 LiveBench 上的排名。
04 Behemoth:2T 参数的“巨兽”,不是给你用的
Behemoth,发音为 /bɪˈhiː.mɑːθ/(比赫马),是英文中 “巨兽” 的意思。
Behemoth 的存在更像是 Meta 给自己留的一手。
虽然目前尚未开源,只是预宣传,但 Meta 官方已经明确表示:Maverick 和 Scout,都是它蒸馏出来的。
换句话说,它是一个 “教师模型”。
在大模型训练中,教师模型通常指的是一个能力更强、体量更大的模型,用于指导或“传授知识”给较小模型。
这种过程叫做“蒸馏”,本质上是让小模型模仿大模型的思维方式、判断逻辑和回答风格,从而在保持高质量输出的同时,大幅减少推理成本。
一些 Llama 4 Behemoth 值得注意的参数:
-
活跃参数:2880亿。 -
总参数量:近 2 万亿。 -
使用 FP8 精度训练。 -
每 GPU 实现 390 TFLOPs 计算效率。 -
数据量:30 万亿 tokens(是 Llama 3 的 2 倍)。
参数量如此庞大的模型,它的成本将会是一个恐怖的数字,你看 OpenAI 的 GPT-4.5 有多贵就知道了。
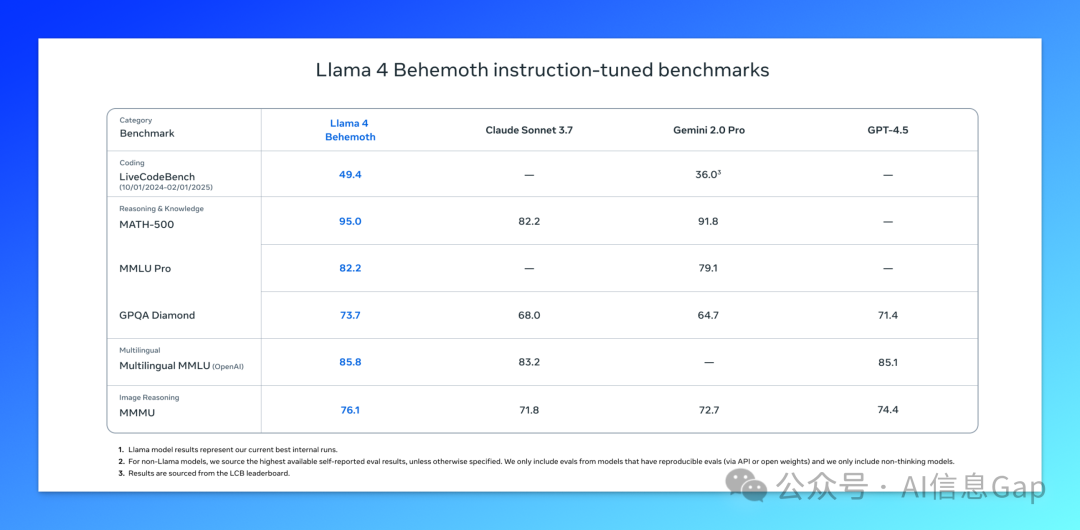
而这个用“算力”堆出来的模型,也确实值得有这样的基准测试表现:全面超越了 GPT-4.5、Claude 3.7 Sonnet 和 Gemini 2.0 Pro。
05 Llama 4 哪里用?
Llama 4 Scout 和 Llama 4 Maverick 已完全发布并开源。这意味着你可以像部署 DeepSeek 模型一样在本地部署这两个模型。
Llama 4 Behemoth 则还在训练中,不开放下载。
https://www.llama.com/llama-downloads/ https://huggingface.co/meta-llama
这里再说几个针对个人用户的使用方案。
首先,Meta 官方不提供任何 API 服务,只能通过其他渠道使用官方的 Llama 4。
比如 官网(meta.ai),WhatsApp,Messenger,和 Instagram Direct。但弊端是 Meta 官方并没有明确说明这些官方渠道集成的模型是 Scout 还是 Maverick。
如果想要调用 Llama 4 的 API,那就只有使用第三方 API 服务了。
这里当然首推我们的老伙计 OpenRouter,它已经第一时间上线了 Llama 4 Scout 和 Llama 4 Maverick 的 API,并且,完全免费。

06 结语:是起点,但不是终点
我们当然可以说:Llama 4 是 Meta 有史以来最重磅、最用力的一次模型发布。
无论是模型性能、参数配置、基准测试结果,还是开源的诚意,都展现出一种“全力一搏”的姿态。
然而,不得不承认,Llama 4 的核心路径依然是熟悉的那一套 —— 用参数、数据和算力堆出领先,用蒸馏和 MoE 拉平成本。
创新也有,但不多。
甚至像业界已经完全采纳的推理模型、内置思维链,在这次的 Llama 4 发布中也缺席了。
所以我说,Llama 4 只是一个起点,不是终点。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)