

如果想左脚踩右脚,一个核心问题是:如何构造合适的prompt,且答案相对比较准确,这样,我们就能不断生成prompt并获取到gold-answer,且用该数据集做rl的训练,提升policy-model的性能。更进一步可以针对当前policy-model的能力评估结果,针对性合成相关的数据,提升policy的能力。(当然,也可以根据测试集针对性构造 测试集的模拟题)。
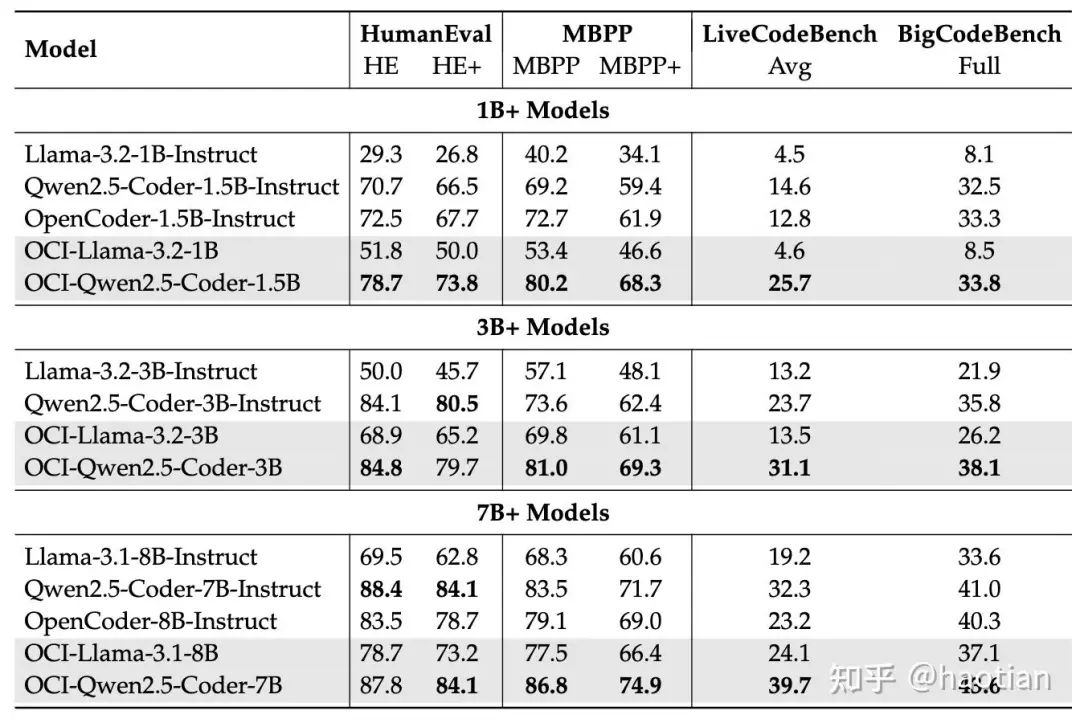
目前,合成prompt的方法有很多如EVOL-INSTRUCT、SELF-INSTRUCT等等。OpenCodeInstruct[1]提出了GENETIC INSTRUCT framework,合成了500万的code-sft-dataset,并在不同的base-model上均取得了不俗的效果:
RL能否左脚踩右脚,很大程度上取决于能否“因材施教”即根据当前policy的性能,自动化合成prompt&gold-answer,针对性提升模型缺失的技能、思维方法等等。
这里,我们选用PromptCoT[2]开源的数据作为rl训练的数据,prompt为合成数据且answer从r1-distill-qwen-7b蒸馏的response里面直接提取。(经验上,用多次采样+投票的机制,可能answer会更准确,但不可能避免引入teacher-model的bias。)
prompt-cot的合成过程如下:
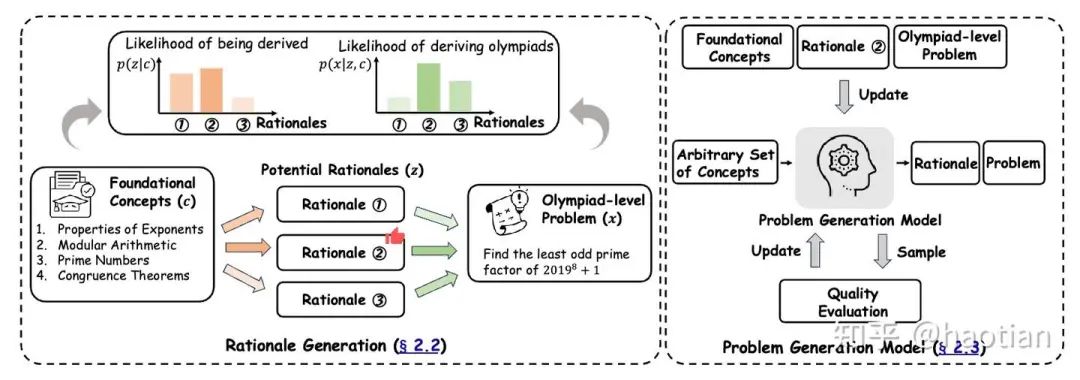
合成过程
基于种子数据,提取concepts和rationales以及难度,并根据concepts/rationales/难度生成prompt。使用额外的评估模型评估prompt的质量如是否清晰/有答案等等。最终,多次拒绝采样后,得到prompt集合。最后一步,则是选择teacher-model获取对应的response。注意:这里,并没有使用复杂的策略保证蒸馏response的答案准确率。在保证种子数据去污染的情况下,prompt-cot算一个‘clean’的dataset。
PromptCoT已验证蒸馏数据的sft效果:在1.5b/7b-r1-distill上面,均有较大幅度的提升。
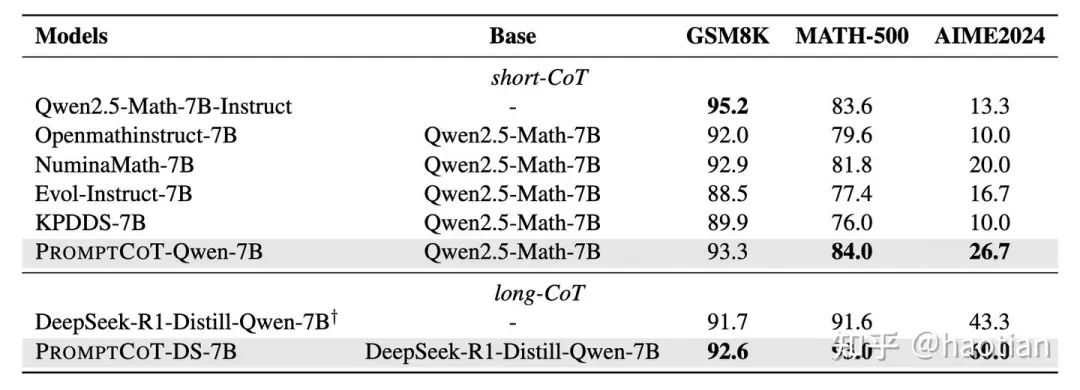
我们这里,主要验证zero-rl上使用这份合成数据是否有提升:
-
• 如果合成数据质量差(prompt没答案/蒸馏数据的答案错误等等),道理上,base上的rl结果会比较惨淡 -
• 如果合成数据质量较好,道理上,可以达到如orz/dapo/vapo的效果。
出于实验成本考虑,我们目前主要在qwen25-7b-base上进行了初步实验(还没有跑完训练)
实验设置
base-model:qwen25-7b-base,rollout-num=16, learning-rate=1e-6
训练配置:clip-higher(clip-ratio非对称)/acc-filter(0.1-0.8之间)/response_length-filter/repeatness-filter/token-level-loss(目前RL训练的基础配置)
结果如下

目前,只跑到550-step,但从上表可以看出,大部分数据集指标均接近orz-ppo的效果。orz-ppo为官方release的模型(使用57k数据训练)。
不管使用grpo还是reinforce++_baseline,基于prompt-cot的数据,zero-rl的效果可以和使用人工数据orz-57k达到相当的效果。初步表明PromptCoT的合成数据的质量确实有一定保障,以及使用7b-r1-distill作为teacher生成的response的答案准确率较高(虽然还没加复杂的答案投票机制)。
近期,Text to RL[3]提出了一个textbook合成rl数据的方法,且在instruct-model上做rl也有一定的正向收益:
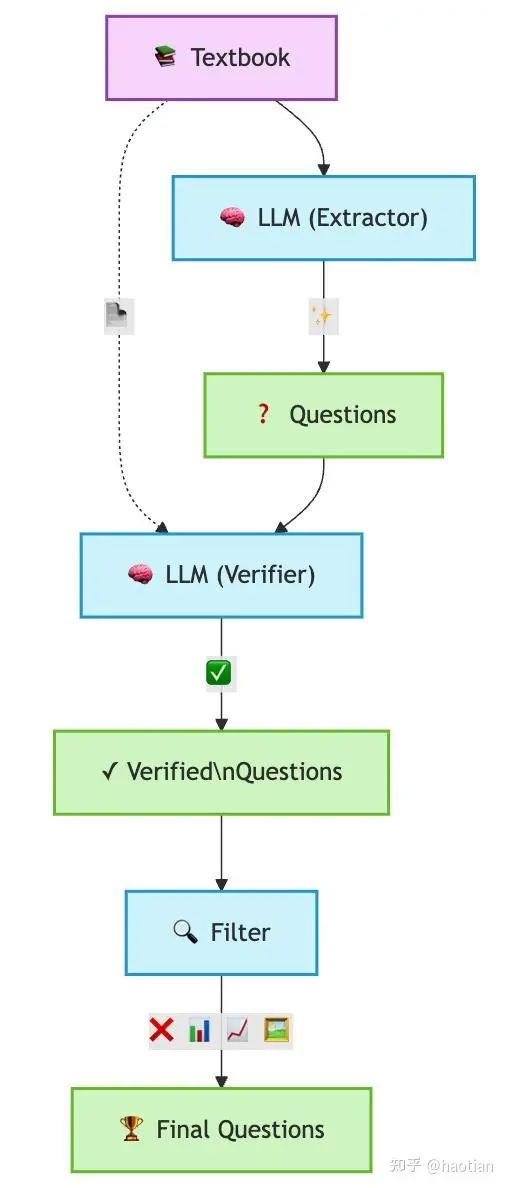
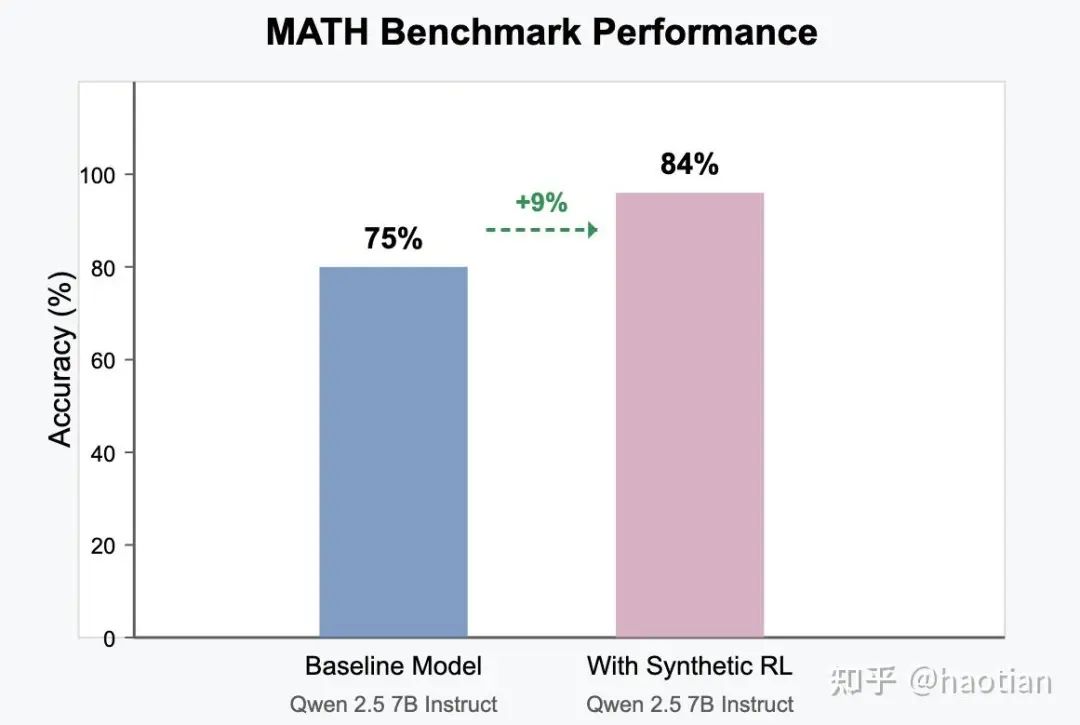
基于以上结果,有理由相信,左脚踩右脚的可能性和前景,毕竟prompt-cot的prompt生成模型只是llama3.1-8b

总结
合理的prompt生成+reasoning-model蒸馏+答案投票(推理模型的投票能力都较强),可以为rl提供更多的答案可验证数据,进一步这些数据亦可用于pretrain阶段,提升数据的覆盖率,以及提供反事实数据(如 加入 不可解的问题等等)。
当然,现在llm的rl实验多数的说服力较低(RL的随机性更多:框架/推理引擎版本/随机数种子/各种未公开trick等等),以及 大部分实验结果只报了一次实验的结果(可能只报了峰值结果,没有报多次实验的平均结果,当然也因为训练周期长,多次实验成本过高,所以,大部分结果需要理性对待)。
最后,yy一下
-
• prompt生成和policy解题放到一个训练流程里面,在线根据policy的评估效果调整prompt生成—>个性化模型训练/对抗训练 -
• 采样引擎的问题会影响训练精度,尤其是rollout样本的分布。为了规避这部分的影响,需要更多的filter过滤样本,以及保持rollout-样本之间有足够的差异性/多样性(语料质量评估/多样性评估等等),还是那个观点:做好replay-buffer的数据质量/多样性控制,比硬调算法trick更关键,否则,很可能算法trick在解决replay-buffer的数据质量问题。
引用链接
[1] OpenCodeInstruct: https://arxiv.org/abs/2504.04030[2] PromptCoT: https://arxiv.org/abs/2503.02324[3] Text to RL: https://tufalabs.ai/blog/_site/jekyll/update/2025/03/25/textbooks-to-rl.html
(文:机器学习算法与自然语言处理)