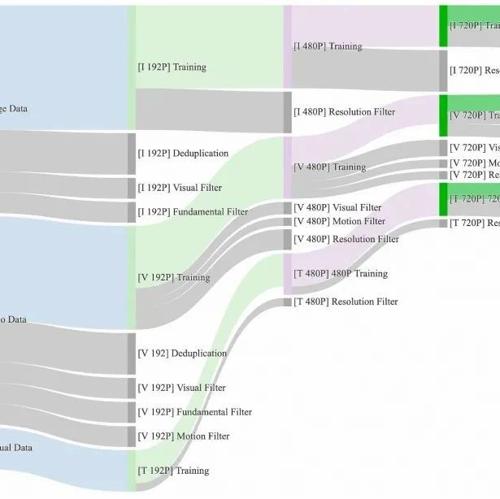
免剪辑直出!AI生成多角色同框对话视频,动态路由精准绑定音频

Bind-Your-Avatar是首个专注同场景多角色说话视频生成的框架,基于扩散Transformer(MM-DiT)通过细粒度Embedding路由实现精确控制。该方法构建了MTCC数据集和基准测试,并在多个指标上显著优于现有方法。
Bind-Your-Avatar是首个专注同场景多角色说话视频生成的框架,基于扩散Transformer(MM-DiT)通过细粒度Embedding路由实现精确控制。该方法构建了MTCC数据集和基准测试,并在多个指标上显著优于现有方法。

MagicTryOn项目利用Transformer模型实现高质量视频试衣效果,包括图像和视频试衣支持。该技术已在多个场景中展现出巨大潜力。
复旦大学和字节跳动团队联合提出CreatiDesign新模型,可实现高精度、多模态、可编辑的AI图形设计生成。该模型解决了扩散Transformer架构在处理图形设计时面临的统一建模、精细解耦控制及大规模高质量标注数据缺失等问题。

↑ 点击
蓝字
关注极市平台
作者丨AI生成未来
来源丨AI生成未来
编辑丨极市平台
极市导读
模型