
变分自编码器
TransDiff–最简洁的AR Transformer + Diffusion图像生成方法
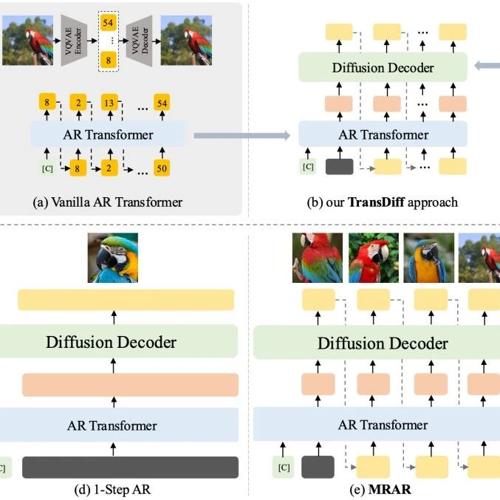
本文介绍了一种新的图像生成方法TransDiff,它结合了AR Transformer和Diffusion模型,并提出了Multi-Reference Autoregression(MRAR)范式。TransDiff使用较小的Diffusion Decoder显著降低参数量,同时在基准测试中表现出色。
MiniMax推出高质量文本转语音模型MiniMax-Speech
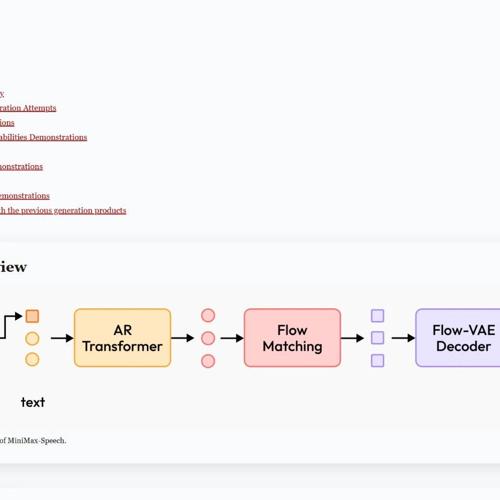
MiniMax发布的新模型MiniMax-Speech通过可学习的说话人编码器和Flow-VAE架构提高了文本转语音的质量与保真度,在零样本情况下实现了跨语言合成,多项测试中表现优异。
支持20+视觉任务,多项SOTA!可扩展多任务视觉基础模型LaVin-DiT:融合时空VAE与DiT

↑ 点击
蓝字
关注极市平台
作者丨AI生成未来
来源丨AI生成未来
编辑丨极市平台
极市导读
模型